
Introduction
Transformers have changed the way artificial intelligence works, especially in understanding language and learning from data. At the core of these models are tensors (a generalized type of mathematical matrices that help process information) . As data moves through the different parts of a Transformer, these tensors are subject to different transformations that help the model make sense of things like sentences or images. Learning how tensors work inside Transformers can help you understand how today’s smartest AI systems actually work and think.
What This Article Covers and What It Doesn’t
 This Article IS About:
This Article IS About:
- The flow of tensors from input to output within a Transformer model.
- Ensuring dimensional coherence throughout the computational process.
- The step-by-step transformations that tensors undergo in various Transformer layers.
 This Article IS NOT About:
This Article IS NOT About:
- A general introduction to Transformers or deep learning.
- Detailed architecture of Transformer models.
- Training process or hyper-parameter tuning of Transformers.
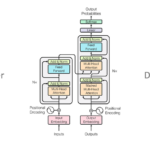
How Tensors Act Within Transformers
A Transformer consists of two main components:
- Encoder: Processes input data, capturing contextual relationships to create meaningful representations.
- Decoder: Utilizes these representations to generate coherent output, predicting each element sequentially.
Tensors are the fundamental data structures that go through these components, experiencing multiple transformations that ensure dimensional coherence and proper information flow.

Input Embedding Layer
Before entering the Transformer, raw input tokens (words, subwords, or characters) are converted into dense vector representations through the embedding layer. This layer functions as a lookup table that maps each token vector, capturing semantic relationships with other words.

For a batch of five sentences, each with a sequence length of 12 tokens, and an embedding dimension of 768, the tensor shape is:
- Tensor shape:
[batch_size, seq_len, embedding_dim] → [5, 12, 768]
After embedding, positional encoding is added, ensuring that order information is preserved without altering the tensor shape.

Multi-Head Attention Mechanism
One of the most critical components of the Transformer is the Multi-Head Attention (MHA) mechanism. It operates on three matrices derived from input embeddings:
- Query (Q)
- Key (K)
- Value (V)
These matrices are generated using learnable weight matrices:
- Wq, Wk, Wv of shape
[embedding_dim, d_model](e.g.,[768, 512]). - The resulting Q, K, V matrices have dimensions
[batch_size, seq_len, d_model].

Splitting Q, K, V into Multiple Heads
For effective parallelization and improved learning, MHA splits Q, K, and V into multiple heads. Suppose we have 8 attention heads:
- Each head operates on a subspace of
d_model / head_count.

- The reshaped tensor dimensions are
[batch_size, seq_len, head_count, d_model / head_count]. - Example:
[5, 12, 8, 64]→ rearranged to[5, 8, 12, 64]to ensure that each head receives a separate sequence slice.

- So each head will get the its share of Qi, Ki, Vi

Attention Calculation
Each head computes attention using the formula:

Once attention is computed for all heads, the outputs are concatenated and passed through a linear transformation, restoring the initial tensor shape.


Residual Connection and Normalization
After the multi-head attention mechanism, a residual connection is added, followed by layer normalization:
- Residual connection:
Output = Embedding Tensor + Multi-Head Attention Output - Normalization:
(Output − μ) / σto stabilize training - Tensor shape remains
[batch_size, seq_len, embedding_dim]

Feed-Forward Network (FFN)
In the decoder, Masked Multi-Head Attention ensures that each token attends only to previous tokens, preventing leakage of future information.

This is achieved using a lower triangular mask of shape [seq_len, seq_len] with -inf values in the upper triangle. Applying this mask ensures that the Softmax function nullifies future positions.

Cross-Attention in Decoding
Since the decoder does not fully understand the input sentence, it utilizes cross-attention to refine predictions. Here:
- The decoder generates queries (Qd) from its input (
[batch_size, target_seq_len, embedding_dim]). - The encoder output serves as keys (Ke) and values (Ve).
- The decoder computes attention between Qd and Ke, extracting relevant context from the encoder’s output.

Conclusion
Transformers use tensors to help them learn and make smart decisions. As the data moves through the network, these tensors go through different steps—like being turned into numbers the model can understand (embedding), focusing on important parts (attention), staying balanced (normalization), and being passed through layers that learn patterns (feed-forward). These changes keep the data in the right shape the whole time. By understanding how tensors move and change, we can get a better idea of how AI models work and how they can understand and create human-like language.
The post Behind the Magic: How Tensors Drive Transformers appeared first on Towards Data Science.
The workflow Of tensors Inside Transformers
The post Behind the Magic: How Tensors Drive Transformers appeared first on Towards Data Science. Large Language Models, AI models, Embedding, multi-head attention, Tensor, Transformers Towards Data ScienceRead More

 Add to favorites
Add to favorites

0 Comments