
Extracting relevant data from structured tables required more than a standard RAG approach. We enhanced prompt engineering with indexed term suggestions, contextual row retrieval, and dynamic few-shot examples to generate reliable Pandas queries, making our system both accurate and efficient.
Co-authored by Michael Leshchinsky
Clalit is Israel’s largest Health Maintenance Organization — it serves both as the insurer and as the health provider for over 4.5M members across Israel. As you may expect, an organization as large as this has a lot of useful information that should be available to all its customers and staff — lists of medical providers, patients’ eligibilities, information about medical tests and procedures, and much more. Unfortunately, this information is spread across several sources and systems, making it quite difficult for the end-user to fetch the exact piece of information they are looking for.
To solve this we’ve decided to build a multi-agent RAG system that can understand which knowledge domain it needs to query, fetch relevant context from one or several sources, and provide the user with the correct and full answer based on this context.
Each agent is devoted to a specific domain and is a small RAG itself, so it can retrieve context and answer questions about its domain. A coordinator agent understands the users’ questions and decides which agent(s) it should address. Then, it aggregates the answers from all relevant agents and compiles an answer for user.
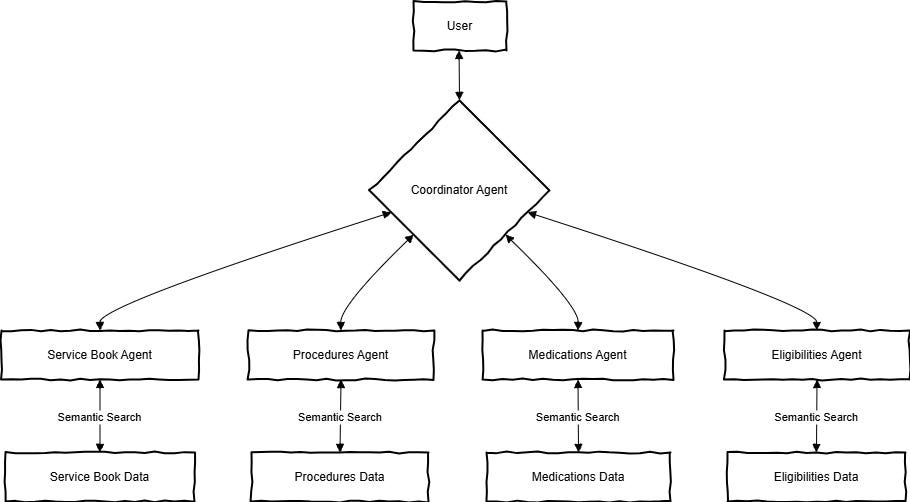
At least, that was the initial idea — very quickly we discovered that not all data sources are made equal and some agents should be something completely different from what one could call a classical RAG.
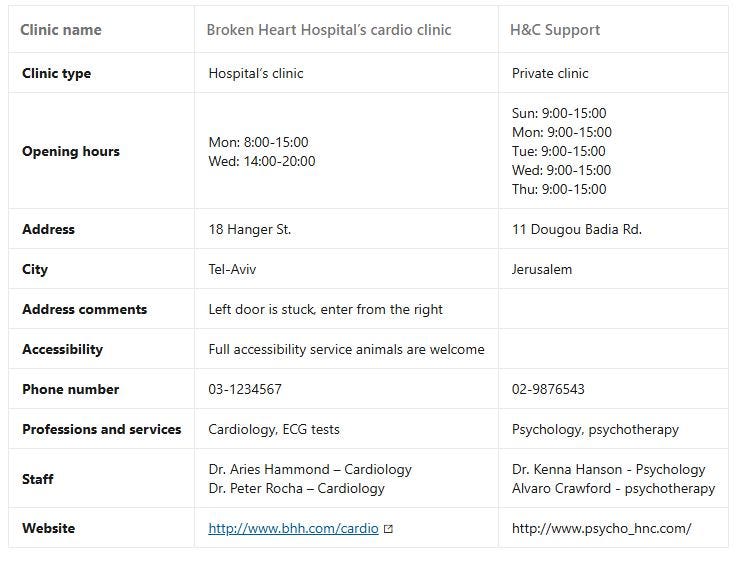
In this article, we will focus on one such use case -the medical providers list, also known as the service book. The service Book is a table with ~23K rows where each row represents a medical provider. The information for each provider includes its address and contact information, the professions and services offered (including staff names), opening hours, and some additional free-text comments regarding the clinic’s accessibility and comments.
Here are some pseudo-examples from the table (displayed vertically due to the large number of columns).
Our initial approach was to convert each row to a text document, index it, and then use a simple RAG to extract it. However, we quickly found that this approach has several limitations:
– User might expect an answer with multiple rows. For example, consider the question: “which pharmacies are available in Tel-Aviv?”. How many documents should our RAG retrieve? What about a question where user explicitly defines how many rows to expect?
– It might be extremely difficult for the retriever to differentiate between the different fields — a clinic in a certain city might be called after another city (e.g., Jerusalem clinic is located in Jerusalem Rd. in Tel-Aviv)
– As humans, we would probably not “text-scan” a table to extract information out of it. Instead, we would prefer to filter the table according to rules. There is no reason our application should behave differently.
Instead, we decided to go in a different direction — ask the LLM to convert user’s question to computer code that will extract the relevant rows.
This approach is inspired by llama-index’s Pandas Query Engine. In brief, the prompt for the LLM is constructed of the user’s query, df.head() to teach the LLM how the table is structured, and some general instructions.
query = """
Your job is to convert user's questions to a single line of Pandas code that will filter `df` and answer the user's query.
---
Here are the top five rows from df:
{df}
---
- Your output will be a single code line with no additional text.
- The output must include: the clinic/center name, type, address, phone number(s), additional remarks, website, and all columns including the answer or that were filtered.
- Think carefully about each search term!
---
USER'S QUESTION: {user_query}
PANDAS CODE:
"""
response = llm.complete(query.format(df=df.head(),
user_query=user_query)
)
try:
result_df = eval(response.text)
except:
result_df = pd.DataFrame()
Sounds easy enough, right? Well, in practice we encountered a cruel reality where in most of our generated code, pandas threw an error for one reason or another, so the main work only started here.
We were able to identify three main reasons for generated code failure and use several dynamic prompt-engineering techniques to address them:
1. Fixing a problem with in-exact terms by adding “thesaurus” of the terms that could be used to filter each column.
2. Providing the LLM with relevant rows from df instead of arbitrary rows extracted by df.head().
3. Dynamic few-shotting with tailored code examples to help the LLM generate correct pandas code.
Adding thesaurus to the prompt
In many cases, the user’s question may not be exactly what the table “expects”. For example, a user may ask for pharmacies in Tel Aviv, but the term in the table is Tel-Aviv-Jaffa. In another case, the user may be looking for an oftalmologist, instead of an ophthalmologist, or for a cardiologist instead of cardiology. It will be difficult for the LLM to write code that will cover all these cases. Instead, it may be to retrieve the correct terms and include it in the prompt as suggestions.
As you may imagine, the service book has a finite number of terms in each column — clinic type may be a hospital clinic, a private clinic, a primary-care clinic, and so on. There is a finite number of city names, medical professions and services, and medical staff. The solution we used was to create a list of all terms (under each field), keep each one as a document, and then index it as a vector.
Then, using a retrieval only engine, we extract ~3 items for each search term, and include those in the prompt. For example, if the user’s question was “which pharmacies are available in Tel Aviv?”, the following terms might be retrieved:
– Clinic type: Pharmacy; Primary-care clinic; Hospital clinic
– City: Tel-Aviv-Jaffa, Tel-Sheva, Pharadis
– Professions and services: Pharmacy, Proctology, Pediatrics
– …
The retrieved terms include the true terms we are looking for (Pharmacy, Tel-Aviv-Jaffa), along some irrelevant terms that may sound similar (Tel-Sheva, proctology). All these terms will be included in the prompt as suggestions, and we expect the LLM to sort out the ones that may be useful.
from llama_index.core import VectorStoreIndex, Document
# Indexing all city names
unique_cities = df['city'].unique()
cities_documents = [Document(text=city) for city in unique_cities]
cities_index = VectorStoreIndex.from_documents(documents=cities_documents)
cities_retriever = cities_index.as_retriever()
# Retrieving suggested cities with the user's query
suggest_cities = ", ".join([doc.text for doc in cities_retriever.retrieve(user_query)])
# Revised query
# Note how it now includes suggestions for relevant cities.
# In a similar manner, we can add suggestions for clinic types, medical professions, etc.
query = """Your job is to convert user's questions to a single line of Pandas code that will filter `df` and answer the user's query.
---
Here are the top five rows from df:
{df}
---
This are the most likely cities you're looking for: {suggest_cities}
---
- Your output will be a single code line with no additional text.
- The output must include: the clinic/center name, type, address, phone number(s), additional remarks, website, and all columns including the answer or that were filtered.
- Think carefully about each search term!
---
USER'S QUESTION: {user_query}
PANDAS CODE:
"""
# Re-filtering the table using the new query
response = llm.complete(query.format(df=df.head(),
suggest_cities=suggest_cities,
user_query=user_query)
)
try:
result_df = eval(response.text)
except:
result_df = pd.DataFrame()
Selecting relevant row examples to include in the prompt
By default, PandasQueryEngine includes the top rows of df in the prompt by embedding df.head() into it, to allow the LLM to learn the table’s structure. However, these top five rows are unlikely to be relevant to the user’s question. Imagine we could wisely select which rows are included in the prompt, such that the LLM will not only learn the table’s structure, but also see examples that are relevant for the current task.
To implement this idea, we used the initial approach described above:
- We converted each row to text and indexed it as a separate document
- Then, we used a retriever to extract the five most relevant rows against the user’s query, and included them in the df example within the prompt
- An important lesson we learn along the way was to include some random, irrelevant examples, so the LLM can also see negative examples and know it has to differentiate between them.
Here’s some code example:
# Indexing and retrieving suggested city names and other fields, as shown above
...
# We convert each row to a document.
# Note how we keep the index of each row - we will use it later.
rows = df.fillna('').apply(lambda x: ", ".join(x), axis=1).to_dict()
rows_documents = [Document(text=v, metadata={'index_number': k}) for k, v in rows.items()]
# Index all examples
rows_index = VectorStoreIndex.from_documents(documents=rows_documents)
rows_retriever = rows_index.as_retriever(top_k_similarity=5)
# Generate example df to include in prompt
retrieved_indices = rows_retriever.retrieve(user_query)
relevant_indices = [i.metadata['index_number'] for i in retrieved_indices]
# Revised query
# This time we also add an example to the prompt
query = """Your job is to convert user's questions to a single line of Pandas code that will filter `df` and answer the user's query.
---
Here are the top five rows from df:
{df}
---
This are the most likely cities you're looking for: {suggest_cities}
---
- Your output will be a single code line with no additional text.
- The output must include: the clinic/center name, type, address, phone number(s), additional remarks, website, and all columns including the answer or that were filtered.
- Think carefully about each search term!
---
Example:
{relevant_example}
---
USER'S QUESTION: {user_query}
PANDAS CODE:
"""
# Re-filtering the table using the new query
# Note how we include both df.head() (as random rows) and the top five relevant rows extracted
# from the retriever
response = llm.complete(query.format(df=pd.concat([df.head(), df.loc[relevant_indices]]),
suggest_cities=suggest_cities,
user_query=user_query)
)
try:
result_df = eval(response.text)
except:
result_df = pd.DataFrame()
Adding a tailored code example to the prompt (Dynamic Few-shotting)
Consider the following user’s question: Does H&C clinic allows service animals?
The generated code was:
df[
(df['clinic_name'].str.contains('H&C')) &
(df['accessibility'].str.contains('service animals'))
][['clinic_name', 'address', 'phone number', 'accessability']]
At first glance, the code looks correct. But… the user didn’t want to filter upon the column accessibility — rather to inspect its content!
Quite early in the process we figured out that a few-shots approach, in which an example question and code answer are included in the prompt, may solve this issue. However, we realized that there are just too many different examples we can think of, each of them emphasizing a different concept.
Our solution was to create a list of different examples, and use a retriever to include the one that is the most similar to the current user’s question. Each example is a dictionary, in which the keys are
- QUESTION: A potential user’s question
- CODE: The requested output code, as we would have write it
- EXPLANATION: Text explanation emphasizing concepts we would like the LLM to consider while generating the code.
For example:
{
'QUESTION': 'Does H&C clinic allows service animals?',
'CODE': "df[df['clinic_name'].str.contains('H&C')][['clinic_name', 'address', 'phone number', 'accessability']]""",
'EXPLANATION': "When asked about whether a service exists or not in a certain clinic - you're not expected to filter upon the related column. Rather, you should return it for the user to inspect!"
}
We can now extended this examples book each time we encounter a new concept we want our system to know how to handle:
# Indexing and retrieving suggested city names, as seen before
...
# Indexing and retrieveing top five relvant rows
...
# Index all examples
examples_documents = [Document(text=ex['QUESTION'],
metadata={k: v for k, v in ex.items()})
for ex in examples_book
]
examples_index = VectorStoreIndex.from_documents(documents=cities_documents)
examples_retriever = examples_index.as_retriever(top_k_similarity=1)
# Retrieve relevant example
relevant_example = examples_retriever.retrieve(user_query)
relevant_example = f"""Question: {relevant_example.text}
Code: {relevant_example.metadata['CODE']}
Explanation: {relevant_example.metadata['EXPLANATION']}
"""
# Revised query
# This time we also add an example to the prompt
query = """Your job is to convert user's questions to a single line of Pandas code that will filter `df` and answer the user's query.
---
Here are the top five rows from df:
{df}
---
This are the most likely cities you're looking for: {suggest_cities}
---
- Your output will be a single code line with no additional text.
- The output must include: the clinic/center name, type, address, phone number(s), additional remarks, website, and all columns including the answer or that were filtered.
- Think carefully about each search term!
---
Example:
{relevant_example}
---
USER'S QUESTION: {user_query}
PANDAS CODE:
"""
# Re-filtering the table using the new query
response = llm.complete(query.format(df=pd.concat([df.head(), df.loc[relevant_indices]]),
suggest_cities=suggest_cities,
relevant_example=relevant_example,
user_query=user_query)
)
try:
result_df = eval(response.text)
except:
result_df = pd.DataFrame()
Summary
In this article, we tried to describe several heuristics that we used to create a more specific, dynamic prompting to extract data from our table. Using pre-indexed data and retrievers, we can enrich our prompt and make it customized to the user’s current question. It is worth mentioning that even though this makes the agent more complex, the running time remained relatively low, since retrievers are generally fast (compared to text generators, at least). This is an illustration of the complete flow:

From Text to Code: Enhancing RAG with Adaptive Prompt Engineering was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Extracting relevant data from structured tables required more than a standard RAG approach. We enhanced prompt engineering with indexed term suggestions, contextual row retrieval, and dynamic few-shot examples to generate reliable Pandas queries, making our system both accurate and efficient.Co-authored by Michael LeshchinskyClalit is Israel’s largest Health Maintenance Organization — it serves both as the insurer and as the health provider for over 4.5M members across Israel. As you may expect, an organization as large as this has a lot of useful information that should be available to all its customers and staff — lists of medical providers, patients’ eligibilities, information about medical tests and procedures, and much more. Unfortunately, this information is spread across several sources and systems, making it quite difficult for the end-user to fetch the exact piece of information they are looking for.To solve this we’ve decided to build a multi-agent RAG system that can understand which knowledge domain it needs to query, fetch relevant context from one or several sources, and provide the user with the correct and full answer based on this context.Each agent is devoted to a specific domain and is a small RAG itself, so it can retrieve context and answer questions about its domain. A coordinator agent understands the users’ questions and decides which agent(s) it should address. Then, it aggregates the answers from all relevant agents and compiles an answer for user.General artchitecture of the solution. Image by authorsAt least, that was the initial idea — very quickly we discovered that not all data sources are made equal and some agents should be something completely different from what one could call a classical RAG.In this article, we will focus on one such use case -the medical providers list, also known as the service book. The service Book is a table with ~23K rows where each row represents a medical provider. The information for each provider includes its address and contact information, the professions and services offered (including staff names), opening hours, and some additional free-text comments regarding the clinic’s accessibility and comments.Here are some pseudo-examples from the table (displayed vertically due to the large number of columns).Our initial approach was to convert each row to a text document, index it, and then use a simple RAG to extract it. However, we quickly found that this approach has several limitations:- User might expect an answer with multiple rows. For example, consider the question: “which pharmacies are available in Tel-Aviv?”. How many documents should our RAG retrieve? What about a question where user explicitly defines how many rows to expect?- It might be extremely difficult for the retriever to differentiate between the different fields — a clinic in a certain city might be called after another city (e.g., Jerusalem clinic is located in Jerusalem Rd. in Tel-Aviv)- As humans, we would probably not “text-scan” a table to extract information out of it. Instead, we would prefer to filter the table according to rules. There is no reason our application should behave differently.Instead, we decided to go in a different direction — ask the LLM to convert user’s question to computer code that will extract the relevant rows.This approach is inspired by llama-index’s Pandas Query Engine. In brief, the prompt for the LLM is constructed of the user’s query, df.head() to teach the LLM how the table is structured, and some general instructions.query = “””Your job is to convert user’s questions to a single line of Pandas code that will filter `df` and answer the user’s query.—Here are the top five rows from df:{df}—- Your output will be a single code line with no additional text.- The output must include: the clinic/center name, type, address, phone number(s), additional remarks, website, and all columns including the answer or that were filtered.- Think carefully about each search term!—USER’S QUESTION: {user_query}PANDAS CODE:”””response = llm.complete(query.format(df=df.head(), user_query=user_query) )try: result_df = eval(response.text)except: result_df = pd.DataFrame()Sounds easy enough, right? Well, in practice we encountered a cruel reality where in most of our generated code, pandas threw an error for one reason or another, so the main work only started here.We were able to identify three main reasons for generated code failure and use several dynamic prompt-engineering techniques to address them:1. Fixing a problem with in-exact terms by adding “thesaurus” of the terms that could be used to filter each column.2. Providing the LLM with relevant rows from df instead of arbitrary rows extracted by df.head().3. Dynamic few-shotting with tailored code examples to help the LLM generate correct pandas code.Adding thesaurus to the promptIn many cases, the user’s question may not be exactly what the table “expects”. For example, a user may ask for pharmacies in Tel Aviv, but the term in the table is Tel-Aviv-Jaffa. In another case, the user may be looking for an oftalmologist, instead of an ophthalmologist, or for a cardiologist instead of cardiology. It will be difficult for the LLM to write code that will cover all these cases. Instead, it may be to retrieve the correct terms and include it in the prompt as suggestions.As you may imagine, the service book has a finite number of terms in each column — clinic type may be a hospital clinic, a private clinic, a primary-care clinic, and so on. There is a finite number of city names, medical professions and services, and medical staff. The solution we used was to create a list of all terms (under each field), keep each one as a document, and then index it as a vector.Then, using a retrieval only engine, we extract ~3 items for each search term, and include those in the prompt. For example, if the user’s question was “which pharmacies are available in Tel Aviv?”, the following terms might be retrieved:- Clinic type: Pharmacy; Primary-care clinic; Hospital clinic- City: Tel-Aviv-Jaffa, Tel-Sheva, Pharadis- Professions and services: Pharmacy, Proctology, Pediatrics- …The retrieved terms include the true terms we are looking for (Pharmacy, Tel-Aviv-Jaffa), along some irrelevant terms that may sound similar (Tel-Sheva, proctology). All these terms will be included in the prompt as suggestions, and we expect the LLM to sort out the ones that may be useful.from llama_index.core import VectorStoreIndex, Document# Indexing all city namesunique_cities = df[‘city’].unique()cities_documents = [Document(text=city) for city in unique_cities]cities_index = VectorStoreIndex.from_documents(documents=cities_documents)cities_retriever = cities_index.as_retriever()# Retrieving suggested cities with the user’s querysuggest_cities = “, “.join([doc.text for doc in cities_retriever.retrieve(user_query)])# Revised query# Note how it now includes suggestions for relevant cities. # In a similar manner, we can add suggestions for clinic types, medical professions, etc.query = “””Your job is to convert user’s questions to a single line of Pandas code that will filter `df` and answer the user’s query.—Here are the top five rows from df:{df}—This are the most likely cities you’re looking for: {suggest_cities}—- Your output will be a single code line with no additional text.- The output must include: the clinic/center name, type, address, phone number(s), additional remarks, website, and all columns including the answer or that were filtered.- Think carefully about each search term!—USER’S QUESTION: {user_query}PANDAS CODE:”””# Re-filtering the table using the new queryresponse = llm.complete(query.format(df=df.head(), suggest_cities=suggest_cities, user_query=user_query) )try: result_df = eval(response.text)except: result_df = pd.DataFrame()Selecting relevant row examples to include in the promptBy default, PandasQueryEngine includes the top rows of df in the prompt by embedding df.head() into it, to allow the LLM to learn the table’s structure. However, these top five rows are unlikely to be relevant to the user’s question. Imagine we could wisely select which rows are included in the prompt, such that the LLM will not only learn the table’s structure, but also see examples that are relevant for the current task.To implement this idea, we used the initial approach described above:We converted each row to text and indexed it as a separate documentThen, we used a retriever to extract the five most relevant rows against the user’s query, and included them in the df example within the promptAn important lesson we learn along the way was to include some random, irrelevant examples, so the LLM can also see negative examples and know it has to differentiate between them.Here’s some code example:# Indexing and retrieving suggested city names and other fields, as shown above…# We convert each row to a document. # Note how we keep the index of each row – we will use it later.rows = df.fillna(”).apply(lambda x: “, “.join(x), axis=1).to_dict()rows_documents = [Document(text=v, metadata={‘index_number’: k}) for k, v in rows.items()]# Index all examplesrows_index = VectorStoreIndex.from_documents(documents=rows_documents)rows_retriever = rows_index.as_retriever(top_k_similarity=5)# Generate example df to include in promptretrieved_indices = rows_retriever.retrieve(user_query)relevant_indices = [i.metadata[‘index_number’] for i in retrieved_indices]# Revised query# This time we also add an example to the promptquery = “””Your job is to convert user’s questions to a single line of Pandas code that will filter `df` and answer the user’s query.—Here are the top five rows from df:{df}—This are the most likely cities you’re looking for: {suggest_cities}—- Your output will be a single code line with no additional text.- The output must include: the clinic/center name, type, address, phone number(s), additional remarks, website, and all columns including the answer or that were filtered.- Think carefully about each search term!—Example:{relevant_example}—USER’S QUESTION: {user_query}PANDAS CODE:”””# Re-filtering the table using the new query# Note how we include both df.head() (as random rows) and the top five relevant rows extracted # from the retrieverresponse = llm.complete(query.format(df=pd.concat([df.head(), df.loc[relevant_indices]]), suggest_cities=suggest_cities, user_query=user_query) )try: result_df = eval(response.text)except: result_df = pd.DataFrame()Adding a tailored code example to the prompt (Dynamic Few-shotting)Consider the following user’s question: Does H&C clinic allows service animals?The generated code was:df[ (df[‘clinic_name’].str.contains(‘H&C’)) & (df[‘accessibility’].str.contains(‘service animals’))][[‘clinic_name’, ‘address’, ‘phone number’, ‘accessability’]]At first glance, the code looks correct. But… the user didn’t want to filter upon the column accessibility — rather to inspect its content!Quite early in the process we figured out that a few-shots approach, in which an example question and code answer are included in the prompt, may solve this issue. However, we realized that there are just too many different examples we can think of, each of them emphasizing a different concept.Our solution was to create a list of different examples, and use a retriever to include the one that is the most similar to the current user’s question. Each example is a dictionary, in which the keys areQUESTION: A potential user’s questionCODE: The requested output code, as we would have write itEXPLANATION: Text explanation emphasizing concepts we would like the LLM to consider while generating the code.For example:{‘QUESTION’: ‘Does H&C clinic allows service animals?’,’CODE’: “df[df[‘clinic_name’].str.contains(‘H&C’)][[‘clinic_name’, ‘address’, ‘phone number’, ‘accessability’]]”””,’EXPLANATION’: “When asked about whether a service exists or not in a certain clinic – you’re not expected to filter upon the related column. Rather, you should return it for the user to inspect!”}We can now extended this examples book each time we encounter a new concept we want our system to know how to handle:# Indexing and retrieving suggested city names, as seen before…# Indexing and retrieveing top five relvant rows…# Index all examplesexamples_documents = [Document(text=ex[‘QUESTION’], metadata={k: v for k, v in ex.items()}) for ex in examples_book ]examples_index = VectorStoreIndex.from_documents(documents=cities_documents)examples_retriever = examples_index.as_retriever(top_k_similarity=1)# Retrieve relevant examplerelevant_example = examples_retriever.retrieve(user_query)relevant_example = f”””Question: {relevant_example.text}Code: {relevant_example.metadata[‘CODE’]}Explanation: {relevant_example.metadata[‘EXPLANATION’]}”””# Revised query# This time we also add an example to the promptquery = “””Your job is to convert user’s questions to a single line of Pandas code that will filter `df` and answer the user’s query.—Here are the top five rows from df:{df}—This are the most likely cities you’re looking for: {suggest_cities}—- Your output will be a single code line with no additional text.- The output must include: the clinic/center name, type, address, phone number(s), additional remarks, website, and all columns including the answer or that were filtered.- Think carefully about each search term!—Example:{relevant_example}—USER’S QUESTION: {user_query}PANDAS CODE:”””# Re-filtering the table using the new queryresponse = llm.complete(query.format(df=pd.concat([df.head(), df.loc[relevant_indices]]), suggest_cities=suggest_cities, relevant_example=relevant_example, user_query=user_query) )try: result_df = eval(response.text)except: result_df = pd.DataFrame()SummaryIn this article, we tried to describe several heuristics that we used to create a more specific, dynamic prompting to extract data from our table. Using pre-indexed data and retrievers, we can enrich our prompt and make it customized to the user’s current question. It is worth mentioning that even though this makes the agent more complex, the running time remained relatively low, since retrievers are generally fast (compared to text generators, at least). This is an illustration of the complete flow:A complete graphical description of the query engine. Image by authors.From Text to Code: Enhancing RAG with Adaptive Prompt Engineering was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. large-language-models, prompt-engineering, retrieval Towards Data Science – MediumRead More


0 Comments