
The missing manual for defining target variables that matter — bridge the gap between business goals and impactful ML models

Perfect accuracy on the wrong target variable is like acing the wrong exam
– technically impressive, but missing the point entirely.
Target variables or dependent variables are critical for the success of your machine learning model.
When starting to work on a new model, most data scientists dive straight into model development, spending weeks engineering features, fine-tuning algorithms and optimizing hyper-parameters. Yet their models often struggle to get adoption and deliver business value.
The result? Frustration, wasted time, and multiple rounds of rework.
The root cause typically traces back to improperly defined target variables.
The Hidden Complexity of Target Variables
Data science literature typically focuses on model architecture while overlooking a crucial question:
WHAT should the model predict?
Discussions on supervised learning implicitly assume that the prediction objective is defined and that ground truth is readily available. Real-world business problems rarely come with clearly defined prediction objectives, creating several challenges such as :
- Misalignment between business goals and model predictions
- Poor model performance requiring multiple iterations and increased development time
- Theoretically accurate model results that do not pass the “sniff” test
- Difficulty influencing stakeholder adoption
These challenges call for a systematic approach — one that bridges the gap between business goals and model performance. Enter the SCORES framework.
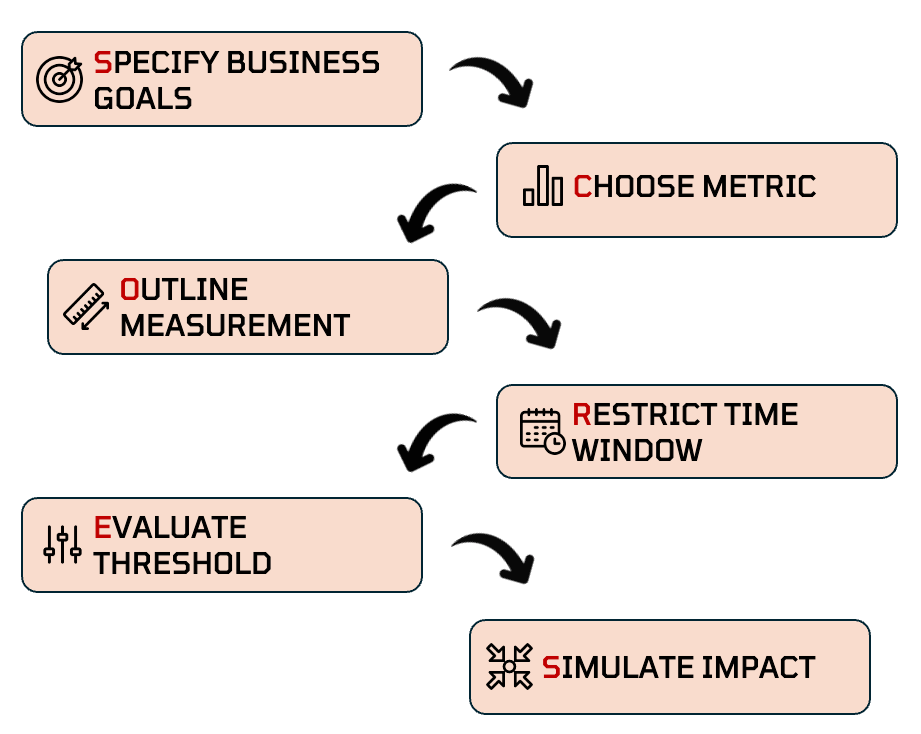
Introducing the SCORES Framework
The SCORES framework is a systematic approach to defining and validating target variables for machine learning classification problems. It guides data scientists through six critical steps that ensure your target variable aligns with business objectives while maintaining model performance.
S — Specify business goals
C — Choose the right metric
O — Outline the measurement type,
R — Restrict the event window,
E — Evaluate metric thresholds
S — Simulate business impact
Consider FinTech First, a digital lending startup that offers credit cards to consumers and small business customers. As the startup evolved from its nascent stages and application volumes tripled, they turned to their data science team to automate the approvals process.
The mission: build a machine learning model to identify risky applicants and approve only the creditworthy customers.
The team’s first challenge? Define what makes a ‘risky’ customer.
Let’s explore how each component of SCORES transforms ambiguous business problems into precise prediction targets, starting with the foundation: business alignment.
S: Specify Business Goals
Before diving into the model development process, every data scientist needs to connect with the product/business stakeholders and align on the business goals and expectations.
Skipping this step can create a disconnect between the model’s capabilities and business needs.
To ensure alignment,
- Ask about growth vs risk tolerance trade-offs
- Document specific goals/success metrics served with the model
- Gather information about existing manual processes
In the case of FinTech First, their science team needed to know:
- What are the business goals? Do we want to target rapid expansion or enforce a tight control on losses (automation with minimal risk)?
- What processes exist for handling existing defaults?
- How do we define a bad customer?
- Do we have a target number of approvals or customer acquisitions from which we are working backwards?
Investing the time to ask such questions at the beginning is critical for ensuring model adoption and can go a long way toward reducing churn.

With clear business objectives in hand, the next challenge is translating them into measurable metrics that your model can actually predict.
C: Choose Metric for Classification Label
Target metrics typically fall into one of three categories:
- Direct metrics that provide clear measurements : Total Past-due Amount ($), Total order amount of food ordered through the app ($), Total amount of orders on the e-commerce website ($)
- Time-based metrics that capture patterns : # late payments, # months with at least one order, # months with an active subscription, # orders/month
- Composite metrics that balance multiple factors: Total Credit Loss (after recovery efforts), Annual profitability per customer (after costs), Number of site visits (with or without purchases),
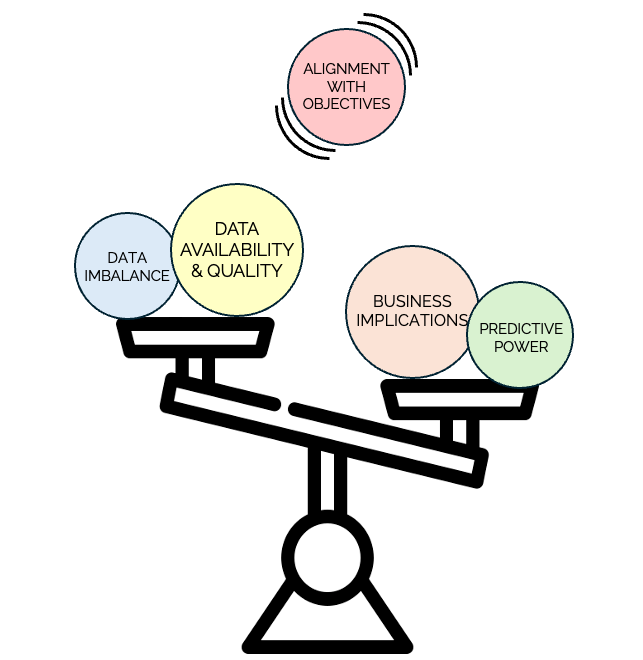
When evaluating trade-offs associated with different metrics, consider :
- Data Imbalance: Does the chosen metric create a significant class imbalance in the training data? How can this imbalance be addressed (e.g., sampling techniques, cost-sensitive learning)?
- Predictive Power: How well can the chosen metric help differentiate between the target classes?
- Business Implications: What are the potential consequences of false positives (e.g., customer dissatisfaction, lost revenue, increased operational costs) vs false negatives (e.g., increased risk of losses, missed opportunities for intervention)? Is one inaccuracy more expensive to the business than the other?
- Alignment with Business Objectives/Processes: How well does the chosen metric align with key business objectives (e.g., revenue growth, customer retention, risk mitigation) and processes (e.g. suspension, write-off, activation, marketing policies)?
- Data Availability and Quality: Is data for the chosen metric readily available and of sufficient quality? Could the metric be biased towards one segment of the customer base than the other?
💡 Pro Tip: Don’t shy away from creating a combination metric definition such as (# of Past Due Payments > X and $ Total Past Due Amount > $Y). Although it increases complexity and the potential for error in labeling, it can help balance the trade-offs listed above without a great deal of compromise.
FinTech First chose to combine outstanding balance with the percentage of credit limit, striking the right balance between absolute risk and customer context.
Once you’ve selected your metric, a crucial decision awaits: how to measure it in a way that captures true business risk.
O: Outline Measurement Type
Once the target metric is identified, we need to determine if we are interested in its absolute or relative value.
Each serves its own purpose: absolute values focus on severity, while relative values provide context.
In FinTech First’s case, a financial trader with a $20,000 monthly credit utilization owing $500 poses a lower financial risk than a college student with a $3000 usage and has yet to repay $2000 of the balance.
A relative metric also helps bring parity if your business consists of a diverse customer base (based on net worth, revenue, frequency of purchases, ability to repay, etc.).
When to Use Absolute Metrics:
- Event severity holds significance (for e.g. fraudulent transactions)
- Regulatory requirements mandate consistent thresholds
- Data limitations prevent relative comparisons
When to Use Relative Metrics:
- Business Context is crucial (for e.g., default risk given net worth, credit history, purchase patterns)
- Ensuring fairness across customers is a priority
- Customer behavior patterns matter when making business decisions (such as distinguishing between a one-time late payment and a habitual late payer).
Choosing between a relative or absolute metric should balance business objectives with population diversity and data constraints. The right measurement type ensures your model maintains reliability and predictive power across all customer segments.
The right metric means little without proper timing. Read on to define when your predictions need to happen.
R: Restrict Event Window
Restricting the event window simply means defining a limit to WHEN the model’s predicted event will occur. The choice of the event window has a significant impact on the prediction’s interpretation and on business outcomes.
Using the following template, we can now define the target variable as
The probability that a [UNIT] will [ACTION] in the next [PERIOD]
Where
Unit: smallest granularity of your training sample (e.g. customer, account)
Action: Action that the model is predicting will happen, based on outputs from Steps C and O (e.g. default/past-due/churn/activate)
Period: Time period defining when the event will occur (e.g., next 1/3/6 months, lifetime).
Note: This step does not apply to predictive models making point-in-time predictions (e.g., identifying fraudulent transactions and spam emails).
The choice of an event window — narrow or wide — significantly impacts model confidence. Models predicting shorter-term events produce more confident predictions than those forecasting longer-term outcomes.
This is due to :
- Feature Aging: Current customer attributes (income, debt ratio, payment behavior) have more substantial predictive power on near-term events. The relationship between a feature value as of inference time and its impact on a future event naturally weakens as time passes between feature capture and event occurrence.
- Increasing Uncertainty: As the Number of customer characteristics increases, the uncertainty in prediction compounds over time as customer characteristics change (for e.g. job status, income, life events)
- External Factors: Long prediction horizons introduce noise from external factors such as macro-economic conditions, market dynamics, and competitive landscapes
For FinTech First, a customer’s current payment behavior strongly indicates their next 30-day default risk but becomes less reliable for predicting their default risk two years from now. Thus, models with shorter prediction horizons demonstrate higher AUC-ROC scores, better calibration of probability estimates, and better stability across different cohorts.
However, a trade-off exists between model predictions and their usability in driving business outcomes. While shorter prediction windows offer more reliable estimates, their limitations include:
- Limited strategic value: Businesses need sufficient lead time for intervention measures (for e.g. marketing campaigns)
- Operational alignment: The ideal prediction window should align with existing business processes and timelines (e.g., account suspension timelines such as 90/120/150 days, collections escalation procedures).
- The “Blind Spot” problem: Short-term predictions create visibility gaps. For example, a customer flagged as “low-risk” for default in the next month could still default in month 2 or 3.
Ultimately, the optimal solution strikes the right balance between an acceptable level of prediction confidence, sufficient lead time for business decisions, and alignment with operational processes.
When choosing between similar prediction windows (e.g., 120 vs 150 days), analyzing the population distribution and customer behavior can help inform the decision. For example, in FinTech First, if only 5% of customers repay at 90 days versus 25% at 120 days, the longer window better distinguishes between late payers and true defaulters.
With timing established, we need to determine what level of our metric signals a meaningful event worth predicting.
E: Evaluate Threshold Values
Thresholds determine when an event becomes material enough for prediction. They help filter out noise and allow the model to learn from and focus on business-relevant events.
For example, for FinTech First, a customer can be classified as “bad” or “risky” if their past-due amount exceeds a certain threshold (e.g., $100, 1% of the credit limit).
The rationale: Past-due amounts less than $100 may be common and not indicative of significant credit risk. However, they can lead to increase in false positives and lower the approval rate for the credit product.
It is imperative to find the right balance because a threshold that is
- Too strict: Leads to excessive action (e.g., 1% approval rate) and a data imbalance
- Too lenient: Leads to model predictions that are not actionable and/or do not drive desirable business outcomes (e.g., high approval rate but also high loss rate).
To determine the threshold for your target variable metric, analyze its historical data distribution. Analyzing data using histograms or percentile distributions can help identify outliers or specific focus areas.
The choice of threshold also depends on the product’s current state and the business’s future goals.
For FinTech First, if the business adopts a conservative risk strategy, select thresholds to approve only the creme-de-la-creme of the population, a.k.a. the lowest-risk segment. If the product has a growth focus, analyze where borderline cases fall — approve all up to customers who are occasionally late but don’t generate material losses.
💡 Pro tip: Segment your population and analyze distributions separately to avoid biases and ensure fair representation across customer groups.
The final step brings everything together — validating that our target variable will drive real business impact.
S: Simulate Business Impact
The final step in the SCORES framework is to combine all the outputs from S — C — O — R — E to create a crisp and precise target variable definition :
“A [unit of analysis] is classified as [positive/negative class] if their [metric] in [time window] is [operator] [threshold] [measurement type]”
“S”:
- Unit of analysis: customer, transaction, machine
- Class label: high-risk, churned, fraudulent, failing
“C”:
- Metric: past-due amount, purchase frequency, deviation, error rate
“O”:
- Measurement type: percentage of transaction, absolute count, statistical measure, percentage of production
“R”:
- Time window: 6 months, 90 days, 24 hours, 7 days
“E”:
- Operator: greater than, less than, exceeds
- Threshold: 5%, 1 transaction, 3 standard deviations, 2%
As shared previously, this framework is domain-agnostic and can be used across different problem domains. For example,
- Credit Risk: “A customer is high-risk if their past-due amount in 6 months exceeds 5% of their transaction amount.”
- Customer Churn: “A customer has churned if their purchase frequency in 90 days is below one transaction.”
- Equipment Failure: “A machine is failing if its error rate in 7 days exceeds 2% of total production”
Once the target variable is defined, it’s time to go back to the business and validate target definitions before model building begins.
Skipping validations can lead to surprises in development/production and increase model development timelines.
To simulate business impact, assign class labels (1/0) to samples in your development dataset and generate a view that captures the following :
- Class distribution of your training sample
- Capture relevant business metrics for samples within the two classes (for e.g. loss-rate, total line of credit, Total Sales, etc.)
- Segment it based on your population segments

The goal is for data scientists and business stakeholders to walk away with actionable insights on :
- What customer profile are we targeting?
- Does it align with the overall strategy of the product?
- Is the class distribution sufficient to achieve reasonable model performance?
This step can also act as a useful forum to get business input or directional guidance if you are debating more than one target variable definition.
For these discussions, keep your SCORES analysis handy to justify choice of target variable recommendations, explain trade-offs and answer stakeholder questions.
From Framework to Impact
Remember — your target variable is your model’s north star. Pick the wrong one, and you’ll navigate toward the wrong destination, no matter how accurate your predictions.
The SCORES framework transforms an often chaotic, intuition-based process into a repeatable process that is :
- Systematic: Replace intuition with structured decision-making
- Collaborative: Align technical and business perspectives from day one
- Impactful: Drive outcomes that matter to your stakeholders
The next time you start building a model, resist the urge to dive into the data. Instead, take a step back, pull out the SCORES framework, and invest time in defining a winning target variable. Your future self (and your stakeholders) will thank you.
Author Note: I’m just getting started as an author on Medium, and your support means a lot!
If you found this helpful, please consider engaging through claps, highlights, or comments.
I’m always open to feedback on how to make these guides more valuable. Thank you for reading!
The SCORES Framework: A Data Scientist’s Guide to Winning Target Variables was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
The missing manual for defining target variables that matter — bridge the gap between business goals and impactful ML modelsPhoto by Jeffrey F Lin on UnsplashPerfect accuracy on the wrong target variable is like acing the wrong exam- technically impressive, but missing the point entirely.Target variables or dependent variables are critical for the success of your machine learning model.When starting to work on a new model, most data scientists dive straight into model development, spending weeks engineering features, fine-tuning algorithms and optimizing hyper-parameters. Yet their models often struggle to get adoption and deliver business value.The result? Frustration, wasted time, and multiple rounds of rework.The root cause typically traces back to improperly defined target variables.The Hidden Complexity of Target VariablesData science literature typically focuses on model architecture while overlooking a crucial question:WHAT should the model predict?Discussions on supervised learning implicitly assume that the prediction objective is defined and that ground truth is readily available. Real-world business problems rarely come with clearly defined prediction objectives, creating several challenges such as :Misalignment between business goals and model predictionsPoor model performance requiring multiple iterations and increased development timeTheoretically accurate model results that do not pass the “sniff” testDifficulty influencing stakeholder adoptionThese challenges call for a systematic approach — one that bridges the gap between business goals and model performance. Enter the SCORES framework.Introducing the SCORES FrameworkThe SCORES framework is a systematic approach to defining and validating target variables for machine learning classification problems. It guides data scientists through six critical steps that ensure your target variable aligns with business objectives while maintaining model performance.S — Specify business goalsC — Choose the right metricO — Outline the measurement type,R — Restrict the event window,E — Evaluate metric thresholdsS — Simulate business impactImage generated by authorConsider FinTech First, a digital lending startup that offers credit cards to consumers and small business customers. As the startup evolved from its nascent stages and application volumes tripled, they turned to their data science team to automate the approvals process.The mission: build a machine learning model to identify risky applicants and approve only the creditworthy customers.The team’s first challenge? Define what makes a ‘risky’ customer.Let’s explore how each component of SCORES transforms ambiguous business problems into precise prediction targets, starting with the foundation: business alignment.S: Specify Business GoalsBefore diving into the model development process, every data scientist needs to connect with the product/business stakeholders and align on the business goals and expectations.Skipping this step can create a disconnect between the model’s capabilities and business needs.To ensure alignment,Ask about growth vs risk tolerance trade-offsDocument specific goals/success metrics served with the modelGather information about existing manual processesIn the case of FinTech First, their science team needed to know:What are the business goals? Do we want to target rapid expansion or enforce a tight control on losses (automation with minimal risk)?What processes exist for handling existing defaults?How do we define a bad customer?Do we have a target number of approvals or customer acquisitions from which we are working backwards?Investing the time to ask such questions at the beginning is critical for ensuring model adoption and can go a long way toward reducing churn.Image generated by Author using Claude AIWith clear business objectives in hand, the next challenge is translating them into measurable metrics that your model can actually predict.C: Choose Metric for Classification LabelTarget metrics typically fall into one of three categories:Direct metrics that provide clear measurements : Total Past-due Amount ($), Total order amount of food ordered through the app ($), Total amount of orders on the e-commerce website ($)Time-based metrics that capture patterns : # late payments, # months with at least one order, # months with an active subscription, # orders/monthComposite metrics that balance multiple factors: Total Credit Loss (after recovery efforts), Annual profitability per customer (after costs), Number of site visits (with or without purchases),When evaluating trade-offs associated with different metrics, consider :Data Imbalance: Does the chosen metric create a significant class imbalance in the training data? How can this imbalance be addressed (e.g., sampling techniques, cost-sensitive learning)?Predictive Power: How well can the chosen metric help differentiate between the target classes?Business Implications: What are the potential consequences of false positives (e.g., customer dissatisfaction, lost revenue, increased operational costs) vs false negatives (e.g., increased risk of losses, missed opportunities for intervention)? Is one inaccuracy more expensive to the business than the other?Alignment with Business Objectives/Processes: How well does the chosen metric align with key business objectives (e.g., revenue growth, customer retention, risk mitigation) and processes (e.g. suspension, write-off, activation, marketing policies)?Data Availability and Quality: Is data for the chosen metric readily available and of sufficient quality? Could the metric be biased towards one segment of the customer base than the other?💡 Pro Tip: Don’t shy away from creating a combination metric definition such as (# of Past Due Payments > X and $ Total Past Due Amount > $Y). Although it increases complexity and the potential for error in labeling, it can help balance the trade-offs listed above without a great deal of compromise.FinTech First chose to combine outstanding balance with the percentage of credit limit, striking the right balance between absolute risk and customer context.Image generated by authorOnce you’ve selected your metric, a crucial decision awaits: how to measure it in a way that captures true business risk.O: Outline Measurement TypeOnce the target metric is identified, we need to determine if we are interested in its absolute or relative value.Each serves its own purpose: absolute values focus on severity, while relative values provide context.In FinTech First’s case, a financial trader with a $20,000 monthly credit utilization owing $500 poses a lower financial risk than a college student with a $3000 usage and has yet to repay $2000 of the balance.A relative metric also helps bring parity if your business consists of a diverse customer base (based on net worth, revenue, frequency of purchases, ability to repay, etc.).When to Use Absolute Metrics:Event severity holds significance (for e.g. fraudulent transactions)Regulatory requirements mandate consistent thresholdsData limitations prevent relative comparisonsWhen to Use Relative Metrics:Business Context is crucial (for e.g., default risk given net worth, credit history, purchase patterns)Ensuring fairness across customers is a priorityCustomer behavior patterns matter when making business decisions (such as distinguishing between a one-time late payment and a habitual late payer).Choosing between a relative or absolute metric should balance business objectives with population diversity and data constraints. The right measurement type ensures your model maintains reliability and predictive power across all customer segments.The right metric means little without proper timing. Read on to define when your predictions need to happen.R: Restrict Event WindowRestricting the event window simply means defining a limit to WHEN the model’s predicted event will occur. The choice of the event window has a significant impact on the prediction’s interpretation and on business outcomes.Using the following template, we can now define the target variable asThe probability that a [UNIT] will [ACTION] in the next [PERIOD]WhereUnit: smallest granularity of your training sample (e.g. customer, account)Action: Action that the model is predicting will happen, based on outputs from Steps C and O (e.g. default/past-due/churn/activate)Period: Time period defining when the event will occur (e.g., next 1/3/6 months, lifetime).Note: This step does not apply to predictive models making point-in-time predictions (e.g., identifying fraudulent transactions and spam emails).The choice of an event window — narrow or wide — significantly impacts model confidence. Models predicting shorter-term events produce more confident predictions than those forecasting longer-term outcomes.This is due to :Feature Aging: Current customer attributes (income, debt ratio, payment behavior) have more substantial predictive power on near-term events. The relationship between a feature value as of inference time and its impact on a future event naturally weakens as time passes between feature capture and event occurrence.Increasing Uncertainty: As the Number of customer characteristics increases, the uncertainty in prediction compounds over time as customer characteristics change (for e.g. job status, income, life events)External Factors: Long prediction horizons introduce noise from external factors such as macro-economic conditions, market dynamics, and competitive landscapesFor FinTech First, a customer’s current payment behavior strongly indicates their next 30-day default risk but becomes less reliable for predicting their default risk two years from now. Thus, models with shorter prediction horizons demonstrate higher AUC-ROC scores, better calibration of probability estimates, and better stability across different cohorts.However, a trade-off exists between model predictions and their usability in driving business outcomes. While shorter prediction windows offer more reliable estimates, their limitations include:Limited strategic value: Businesses need sufficient lead time for intervention measures (for e.g. marketing campaigns)Operational alignment: The ideal prediction window should align with existing business processes and timelines (e.g., account suspension timelines such as 90/120/150 days, collections escalation procedures).The “Blind Spot” problem: Short-term predictions create visibility gaps. For example, a customer flagged as “low-risk” for default in the next month could still default in month 2 or 3.Ultimately, the optimal solution strikes the right balance between an acceptable level of prediction confidence, sufficient lead time for business decisions, and alignment with operational processes.When choosing between similar prediction windows (e.g., 120 vs 150 days), analyzing the population distribution and customer behavior can help inform the decision. For example, in FinTech First, if only 5% of customers repay at 90 days versus 25% at 120 days, the longer window better distinguishes between late payers and true defaulters.With timing established, we need to determine what level of our metric signals a meaningful event worth predicting.E: Evaluate Threshold ValuesThresholds determine when an event becomes material enough for prediction. They help filter out noise and allow the model to learn from and focus on business-relevant events.For example, for FinTech First, a customer can be classified as “bad” or “risky” if their past-due amount exceeds a certain threshold (e.g., $100, 1% of the credit limit).The rationale: Past-due amounts less than $100 may be common and not indicative of significant credit risk. However, they can lead to increase in false positives and lower the approval rate for the credit product.It is imperative to find the right balance because a threshold that isToo strict: Leads to excessive action (e.g., 1% approval rate) and a data imbalanceToo lenient: Leads to model predictions that are not actionable and/or do not drive desirable business outcomes (e.g., high approval rate but also high loss rate).To determine the threshold for your target variable metric, analyze its historical data distribution. Analyzing data using histograms or percentile distributions can help identify outliers or specific focus areas.The choice of threshold also depends on the product’s current state and the business’s future goals.For FinTech First, if the business adopts a conservative risk strategy, select thresholds to approve only the creme-de-la-creme of the population, a.k.a. the lowest-risk segment. If the product has a growth focus, analyze where borderline cases fall — approve all up to customers who are occasionally late but don’t generate material losses.💡 Pro tip: Segment your population and analyze distributions separately to avoid biases and ensure fair representation across customer groups.The final step brings everything together — validating that our target variable will drive real business impact.S: Simulate Business ImpactThe final step in the SCORES framework is to combine all the outputs from S — C — O — R — E to create a crisp and precise target variable definition :“A [unit of analysis] is classified as [positive/negative class] if their [metric] in [time window] is [operator] [threshold] [measurement type]”“S”:Unit of analysis: customer, transaction, machineClass label: high-risk, churned, fraudulent, failing“C”:Metric: past-due amount, purchase frequency, deviation, error rate“O”:Measurement type: percentage of transaction, absolute count, statistical measure, percentage of production“R”:Time window: 6 months, 90 days, 24 hours, 7 days“E”:Operator: greater than, less than, exceedsThreshold: 5%, 1 transaction, 3 standard deviations, 2%As shared previously, this framework is domain-agnostic and can be used across different problem domains. For example,Credit Risk: “A customer is high-risk if their past-due amount in 6 months exceeds 5% of their transaction amount.”Customer Churn: “A customer has churned if their purchase frequency in 90 days is below one transaction.”Equipment Failure: “A machine is failing if its error rate in 7 days exceeds 2% of total production”Once the target variable is defined, it’s time to go back to the business and validate target definitions before model building begins.Skipping validations can lead to surprises in development/production and increase model development timelines.To simulate business impact, assign class labels (1/0) to samples in your development dataset and generate a view that captures the following :Class distribution of your training sampleCapture relevant business metrics for samples within the two classes (for e.g. loss-rate, total line of credit, Total Sales, etc.)Segment it based on your population segmentsSimulating Business Impact from Final Target VariableThe goal is for data scientists and business stakeholders to walk away with actionable insights on :What customer profile are we targeting?Does it align with the overall strategy of the product?Is the class distribution sufficient to achieve reasonable model performance?This step can also act as a useful forum to get business input or directional guidance if you are debating more than one target variable definition.For these discussions, keep your SCORES analysis handy to justify choice of target variable recommendations, explain trade-offs and answer stakeholder questions.From Framework to ImpactRemember — your target variable is your model’s north star. Pick the wrong one, and you’ll navigate toward the wrong destination, no matter how accurate your predictions.The SCORES framework transforms an often chaotic, intuition-based process into a repeatable process that is :Systematic: Replace intuition with structured decision-makingCollaborative: Align technical and business perspectives from day oneImpactful: Drive outcomes that matter to your stakeholdersThe next time you start building a model, resist the urge to dive into the data. Instead, take a step back, pull out the SCORES framework, and invest time in defining a winning target variable. Your future self (and your stakeholders) will thank you.Author Note: I’m just getting started as an author on Medium, and your support means a lot!If you found this helpful, please consider engaging through claps, highlights, or comments.I’m always open to feedback on how to make these guides more valuable. Thank you for reading!The SCORES Framework: A Data Scientist’s Guide to Winning Target Variables was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. machine-learning, target-variable, classification, notes-from-industry, data-science Towards Data Science – MediumRead More


0 Comments