
Exploring techniques to prompt VLMs
Vision Language Models (VLMs) represent a significant advancement in processing and understanding multimodal data by combining text and visual inputs.
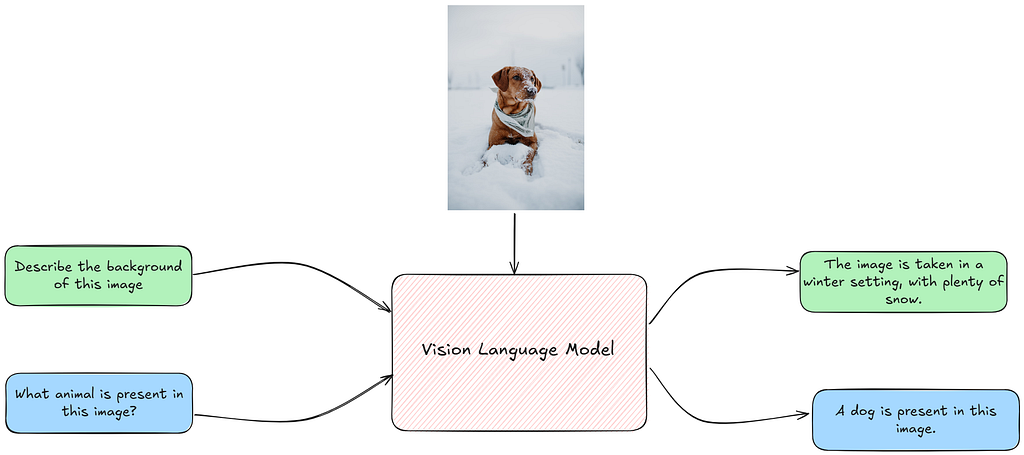
Unlike Large Language Models (LLMs), which handle only text, VLMs are multimodal, enabling users to address tasks requiring both visual and textual comprehension. This capability opens up a wide range of applications, such as Visual Question Answering (VQA), where models answer questions based on images, and Image Captioning, which involves generating descriptive text for images. In this blog post, I explain how we can prompt VLMs for tasks requiring visual understanding, and the different ways in which we can do so.
Table of Contents
- Introduction
- Prompting with VLMs
- Zero-Shot Prompting
- Few-Shot Prompting
- Chain of Thought Prompting
- Object Detection Guided Prompting
- Conclusion
- References
Introduction
VLMs are extensions of existing LLMs — particularly in that they process vision as an additional modality. VLMs are typically trained with mechanisms that align image and text representations in the same representation or vector space, using techniques like cross-attention [1] [2] [3] [4]. The advantages of such systems is that you can interact or “query” images through text as a convenient interface. Because of their multi-modal capacity, VLMs are crucial for bridging the gap between textual and visual data, opening up a large range of use cases that text-only models can’t address. For a more in-depth understanding of how VLMs, I recommend Sebastian Raschka’s excellent article on multi-modal LLMs.
Prompting with VLMs
In an earlier blog, I touched upon techniques for prompting LLMs. Similar to LLMs, VLMs can also be prompted using similar techniques — with the added advantage of incorporating images to help models better understand the task at hand. In this blog, I talk about the common prompting paradigms that apply to VLMs, covering zero-shot, few-shot and chain-of-thought prompting. I also explore how other deep learning methods can help guide in prompting VLMs — such as integrating object detection into prompting strategies. For my experiments, I use OpenAI’s GPT-4o-mini model which is a VLM.
All code and resources used in this blog post are available at this link on github.
Data Used
For this blogpost, I use 5 images downloaded from Unsplash that are permissively licensed for usage. Specifically, I use the following images:
- Photo by Mathias Reding on Unsplash
- Photo by Josh Frenette on Unsplash
- Photo by sander traa on Unsplash
- Photo by NEOM on Unsplash
- Photo by Alexander Zaytsev on Unsplash
The captions for these images are derived from the image urls, as Unsplash images come with the corresponding captions for each image.
Zero-Shot Prompting

Zero-Shot Prompting represents a scenario where the user only provides a description of the task through the system and user prompt, along with the image(s) to be processed. In this setup, the VLM relies only on the task description to generate an output. If we were to categorize prompting methods on a spectrum based on the amount of information provided to the VLM, zero-shot prompting presents the least amount of information to the model.
The advantage for users is that, for most tasks, a well-crafted zero-shot prompt can produce decent outputs simply by describing the task in text. Consider the implications of this: just a few years ago, tasks like image classification or image captioning required training a CNN or deep learning model on a large dataset before they could be used. Now, you can perform these tasks by utilizing text to describe them. You can create an off-the-shelf image classifier by specifying and describing what you want to analyze. Before VLMs, achieving this would have required gathering a large, task-specific dataset, training a model, and then using it for inference.
So how do we prompt them? OpenAI supports sending images as Base64 encoded urls to the VLM [2]. The general request structure looks like this:
{
"role": "system",
"content": "You are a helpful assistant that can analyze images and provide captions."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please analyze the following image:"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,{base64_image}",
"detail": "detail"
}
}
]
}
The structure is largely the same as how you would prompt a normal LLM with OpenAI. However the key difference is in adding an image to the request, which needs to be encoded as a Base64 string. This is where it is actually a bit interesting — though I’m using only one image as an input here, there is nothing stopping me from also attaching multiple images to the request.
Let’s implement helper functions to do zero-shot prompting. To make the experiments faster, I parallelize the requests sent to the OpenAI API. I implement helpers for constructing the prompts and calling the model for getting the outputs.
def encode_image(image_path):
"""
Encodes an image to a base64 string.
Args:
image_path (str): The file path of the image to encode.
Returns:
str: Base64-encoded string of the image, or None if an error occurs.
"""
try:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
except Exception as e:
print(f"Error encoding image: {e}")
return None
def llm_chat_completion(messages, model="gpt-4o-mini", max_tokens=300, temperature=0.0):
"""
Calls OpenAI's ChatCompletion API with the specified parameters.
Args:
messages (list): A list of message dictionaries for the conversation.
model (str): The model to use for the chat completion.
max_tokens (int, optional): Maximum tokens for the response. Defaults to 300.
temperature (float, optional): Sampling temperature for randomness. Defaults to 0.0.
Returns:
str or None: The response content from the API, or None if an error occurs.
"""
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens,
temperature=temperature
)
return response.choices[0].message.content
except Exception as e:
print(f"Error calling LLM: {e}")
return None
def build_few_shot_messages(few_shot_prompt, user_prompt = "Please analyze the following image:", detail="auto"):
"""
Generates few-shot example messages from image-caption pairs.
Args:
few_shot_prompt (dict): A dictionary mapping image paths to metadata,
including "image_caption".
detail (str, optional): Level of image detail to include. Defaults to "auto".
Returns:
list: A list of few-shot example messages.
"""
few_shot_messages = []
for path, data in few_shot_prompt.items():
base64_image = encode_image(path)
if not base64_image:
continue # skip if failed to encode
caption = data
few_shot_messages.append(
{
"role": "user",
"content": [
{"type": "text", "text": user_prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
"detail": detail
}
},
]
}
)
few_shot_messages.append({"role": "assistant", "content": caption})
return few_shot_messages
def build_user_message(image_path, user_prompt="Please analyze the following image:", detail="auto"):
"""
Creates a user message for analyzing a single image.
Args:
image_path (str): Path to the image file.
detail (str, optional): Level of image detail to include. Defaults to "auto".
Returns:
dict or None: The user message dictionary, or None if image encoding fails.
"""
base64_image = encode_image(image_path)
if not base64_image:
return None
return {
"role": "user",
"content": [
{"type": "text", "text": user_prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
"detail": detail
}
},
]
}
def get_image_caption(
image_path,
few_shot_prompt=None,
system_prompt="You are a helpful assistant that can analyze images and provide captions.",
user_prompt="Please analyze the following image:",
model="gpt-4o-mini",
max_tokens=300,
detail="auto",
llm_chat_func=llm_chat_completion,
temperature=0.0
):
"""
Gets a caption for an image using a LLM.
Args:
image_path (str): File path of the image to be analyzed.
few_shot_prompt (dict, optional): Maps image paths to {"image_caption": <caption>}.
system_prompt (str, optional): Initial system prompt for the LLM.
user_prompt (str, optional): User prompt for the LLM.
model (str, optional): LLM model name (default "gpt-4o-mini").
max_tokens (int, optional): Max tokens in the response (default 300).
detail (str, optional): Level of detail for the image analysis (default "auto").
llm_chat_func (callable, optional): Function to call the LLM. Defaults to `llm_chat_completion`.
temperature (float, optional): Sampling temperature (default 0.0).
Returns:
str or None: The generated caption, or None on error.
"""
try:
user_message = build_user_message(image_path, detail)
if not user_message:
return None
# Build message sequence
messages = [{"role": "system", "content": system_prompt}]
# Include few-shot examples if provided
if few_shot_prompt:
few_shot_messages = build_few_shot_messages(few_shot_prompt, detail)
messages.extend(few_shot_messages)
messages.append(user_message)
# Call the LLM
response_text = llm_chat_func(
model=model,
messages=messages,
max_tokens=max_tokens,
temperature=temperature
)
return response_text
except Exception as e:
print(f"Error getting caption: {e}")
return None
def process_images_in_parallel(
image_paths,
model="gpt-4o-mini",
system_prompt="You are a helpful assistant that can analyze images and provide captions.",
user_prompt="Please analyze the following image:",
few_shot_prompt = None,
max_tokens=300,
detail="auto",
max_workers=5):
"""
Processes a list of images in parallel to generate captions using a specified model.
Args:
image_paths (list): List of file paths to the images to be processed.
model (str): The model to use for generating captions (default is "gpt-4o").
max_tokens (int): Maximum number of tokens in the generated captions (default is 300).
detail (str): Level of detail for the image analysis (default is "auto").
max_workers (int): Number of threads to use for parallel processing (default is 5).
Returns:
dict: A dictionary where keys are image paths and values are their corresponding captions.
"""
captions = {}
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# Pass additional arguments using a lambda or partial
future_to_image = {
executor.submit(
get_image_caption,
image_path,
few_shot_prompt,
system_prompt,
user_prompt,
model,
max_tokens,
detail): image_path
for image_path in image_paths
}
# Use tqdm to track progress
for future in tqdm(as_completed(future_to_image), total=len(image_paths), desc="Processing images"):
image_path = future_to_image[future]
try:
caption = future.result()
captions[image_path] = caption
except Exception as e:
print(f"Error processing {image_path}: {e}")
captions[image_path] = None
return captions
We now run the outputs for the two images and get the corresponding caption from the zero-shot prompting setup.
from tqdm import tqdm
import os
IMAGE_QUALITY = "high"
PATH_TO_SAMPLES = "images/"
system_prompt = """You are an AI assistant that provides captions of images.
You will be provided with an image. Analyze the content, context, and notable features of the images.
Provide a concise caption that covers the important aspects of the image."""
user_prompt = "Please analyze the following image:"
image_paths = [os.path.join(PATH_TO_SAMPLES, x) for x in os.listdir(PATH_TO_SAMPLES)]
zero_shot_high_quality_captions = process_images_in_parallel(image_paths, model = "gpt-4o-mini", system_prompt=system_prompt, user_prompt = user_prompt, few_shot_prompt= None, detail=IMAGE_QUALITY, max_workers=5)
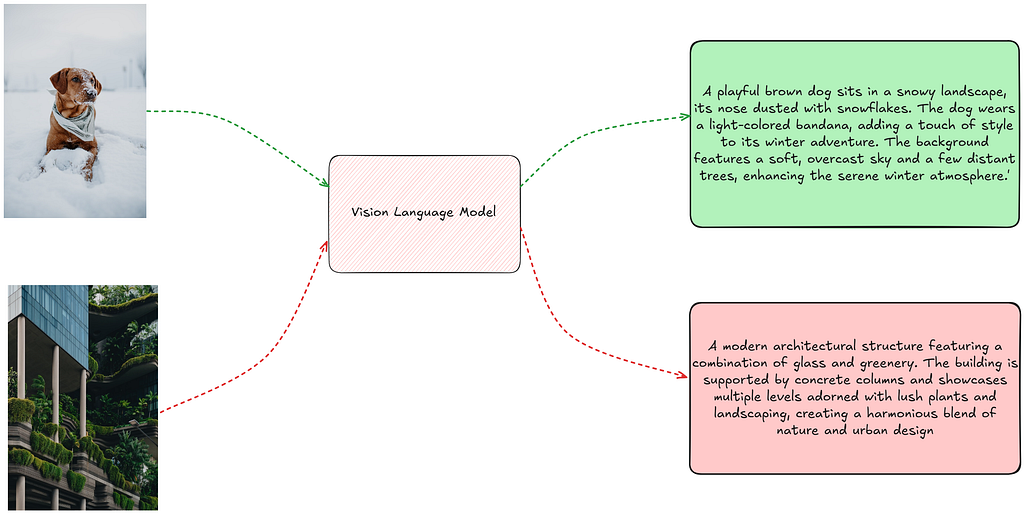
We observe that the model gives detailed captions for the provided images, covering all the aspects in detail.
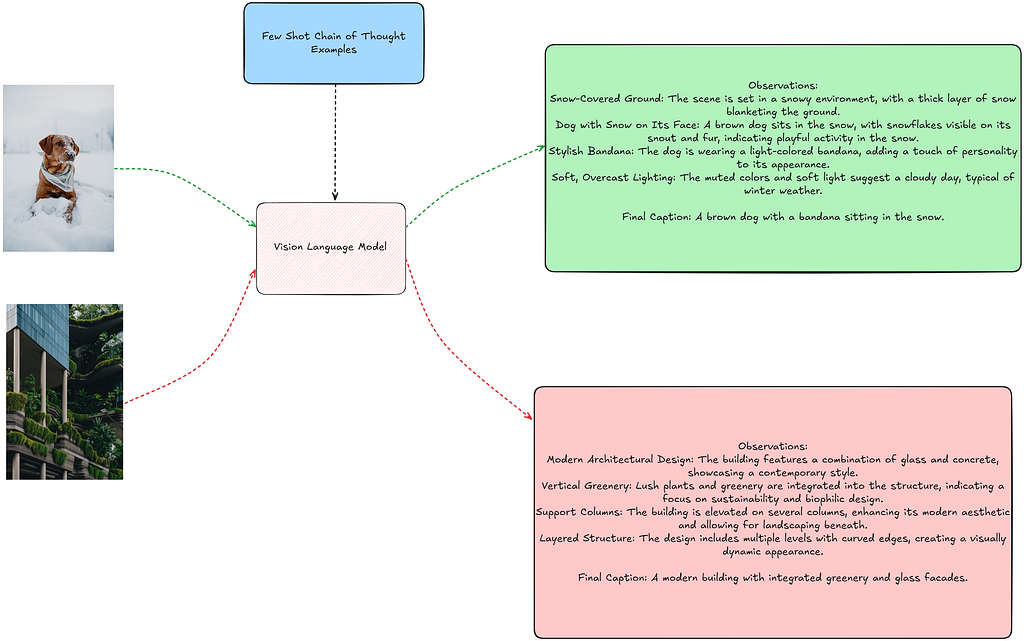
Few-Shot Prompting
Few-Shot Prompting involves providing examples or demostrations of the task as context to the VLM to provide more reference and context to the model about the task to be performed.
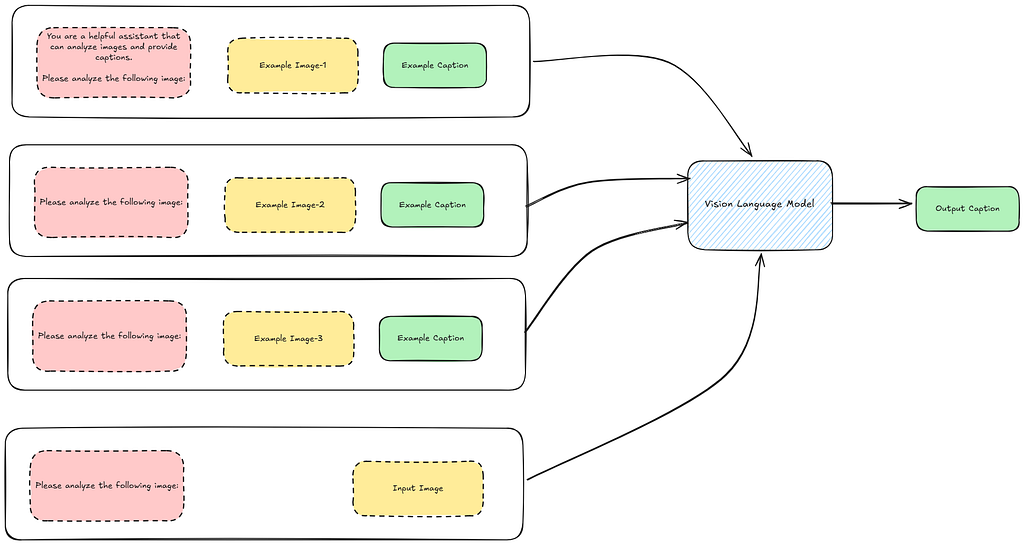
The advantages of few-shot prompting is that it helps provide additional grounding for the task, compared to zero-shot prompting. Let’s look at how this practically occurs in our task. First, consider our existing implementation:
def build_few_shot_messages(few_shot_prompt, user_prompt = "Please analyze the following image:", detail="auto"):
"""
Generates few-shot example messages from image-caption pairs.
Args:
few_shot_prompt (dict): A dictionary mapping image paths to metadata,
including "image_caption".
detail (str, optional): Level of image detail to include. Defaults to "auto".
Returns:
list: A list of few-shot example messages.
"""
few_shot_messages = []
for path, data in few_shot_prompt.items():
base64_image = encode_image(path)
if not base64_image:
continue # skip if failed to encode
caption = data
few_shot_messages.append(
{
"role": "user",
"content": [
{"type": "text", "text": user_prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
"detail": detail
}
},
]
}
)
few_shot_messages.append({"role": "assistant", "content": caption})
return few_shot_messages
I utilize 3 images as few-shot examples to the VLM, and then run our system.
image_captions = json.load(open("image_captions.json"))
FEW_SHOT_EXAMPLES_PATH = "few_shot_examples/"
few_shot_samples = os.listdir(FEW_SHOT_EXAMPLES_PATH)
few_shot_captions = {os.path.join(FEW_SHOT_EXAMPLES_PATH,k):v for k,v in image_captions.items() if k in few_shot_samples}
IMAGE_QUALITY = "high"
few_shot_high_quality_captions = process_images_in_parallel(image_paths, model = "gpt-4o-mini", few_shot_prompt= few_shot_captions, detail=IMAGE_QUALITY, max_workers=5)
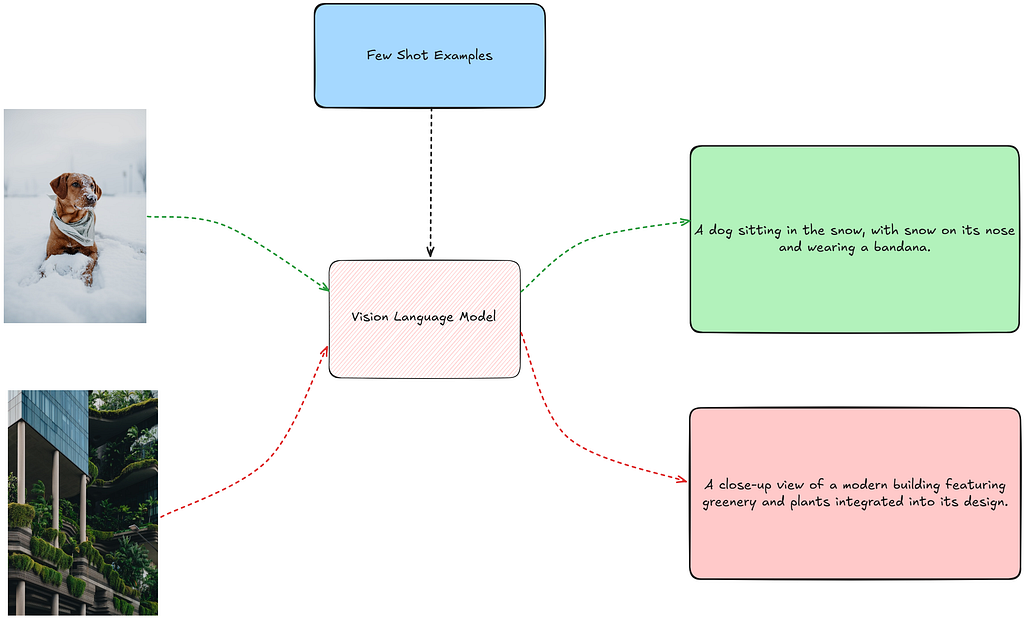
Notice the captions generated with the VLM using the few-shot examples. These captions are much shorter and concise compared to the captions generated in the zero-shot prompting setting. Let’s look at how the captions for these examples look like:
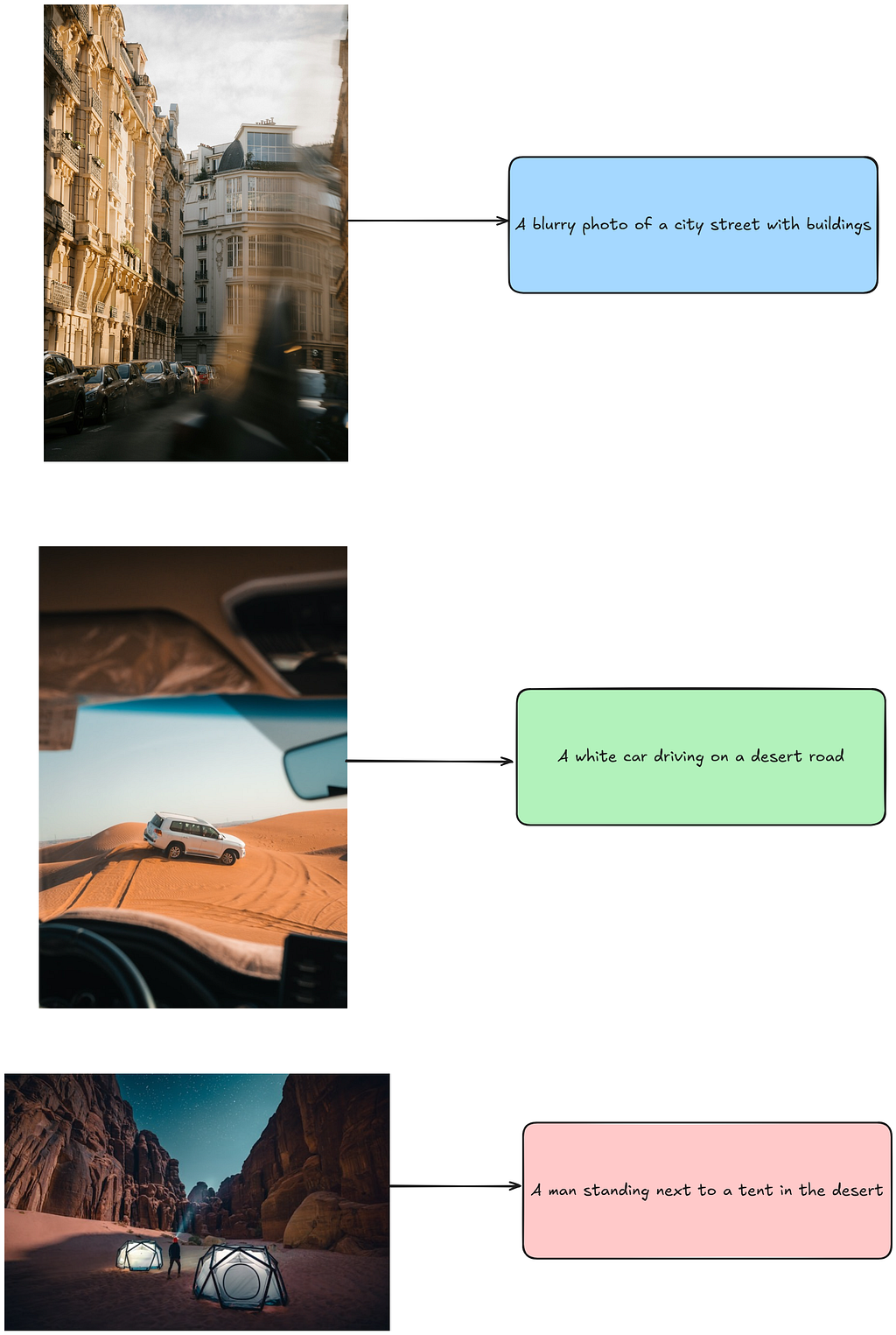
This difference is primarily due to the influence of the few-shot examples. The captions in the few-shot examples clearly influence the output by the VLM for the new images we use, leading to more concise and shorter captions. This illustrates how powerful the selection of few-shot examples can be in shaping the behavior of the VLM. Users can direct the model’s output to more closely match their preferred style, tone, or amount of detail by carefully choosing few-shot samples.
Chain of Thought Prompting
Chain of Thought (CoT) prompting [9], initially developed for LLMs, enables them to tackle address complex problems by breaking them into simpler, intermediate steps and encouraging the model to “think” before answering. This technique can be applied to VLMs without any adjustments. The primary difference is that the VLM can use both image and text as inputs when reasoning under CoT to answer the question.
To implement this, I utilize the 3 examples I picked for few-shot prompting and construct a CoT trace for them by first utilizing OpenAI’s O1 model (which is a multimodal VLM for reasoning tasks). I then use these CoT reasoning traces as my few-shot examples for prompting the VLM. For example, a CoT trace looks like this for one of the images:
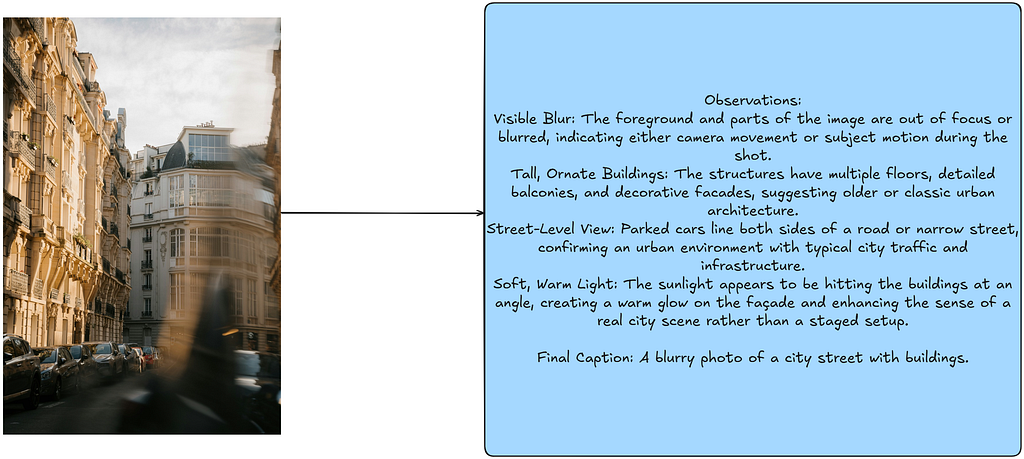
The few-shot CoT traces I created for the images contain detailed reasoning for each aspect of the image that is important for creating the final caption.
few_shot_samples_1_cot = """Observations:
Visible Blur: The foreground and parts of the image are out of focus or blurred, indicating either camera movement or subject motion during the shot.
Tall, Ornate Buildings: The structures have multiple floors, detailed balconies, and decorative facades, suggesting older or classic urban architecture.
Street-Level View: Parked cars line both sides of a road or narrow street, confirming an urban environment with typical city traffic and infrastructure.
Soft, Warm Light: The sunlight appears to be hitting the buildings at an angle, creating a warm glow on the façade and enhancing the sense of a real city scene rather than a staged setup.
Final Caption: A blurry photo of a city street with buildings."""
few_shot_samples_2_cot = """Observations:
Elevated Desert Dunes: The landscape is made up of large, rolling sand dunes in a dry, arid environment.
Off-Road Vehicle: The white SUV appears equipped for travel across uneven terrain, indicated by its size and ground clearance.
Tire Tracks in the Sand: Visible tracks show recent movement across the dunes, reinforcing that the vehicle is in motion and navigating a desert path.
View from Inside Another Car: The dashboard and windshield framing in the foreground suggest the photo is taken from a passenger’s or driver’s perspective, following behind or alongside the SUV.
Final Caption: A white car driving on a desert road."""
few_shot_samples_3_cot = """Observations:
Towering Rock Formations: The steep canyon walls suggest a rugged desert landscape, with sandstone cliffs rising on both sides.
Illuminated Tents: Two futuristic-looking tents emit a soft glow, indicating a nighttime scene with lights or lanterns inside.
Starry Night Sky: The visible stars overhead reinforce that this is an outdoor camping scenario after dark.
Single Male Figure: A man, seen from behind, stands near one of the tents, indicating he is likely part of the camping group.
Final Caption: A man standing next to a tent in the desert."""
We run the CoT prompt setup for the VLM and obtain the results for these images:
import copy
few_shot_samples_cot = copy.deepcopy(few_shot_captions)
few_shot_samples_cot["few_shot_examples/photo_1.jpg"] = few_shot_samples_1_cot
few_shot_samples_cot["few_shot_examples/photo_3.jpg"] = few_shot_samples_2_cot
few_shot_samples_cot["few_shot_examples/photo_4.jpg"] = few_shot_samples_3_cot
IMAGE_QUALITY = "high"
cot_high_quality_captions = process_images_in_parallel(image_paths, model = "gpt-4o-mini", few_shot_prompt= few_shot_samples_cot, detail=IMAGE_QUALITY, max_workers=5)
The outputs from the few-shot CoT setup shows that the VLM is now capable of breaking down the image into intermediate steps before arriving at the final caption. This approach highlights the power of CoT prompting in influencing the behaviour of the VLM for a given task.
Object Detection Guided Prompting
An interesting implication of having models capable of processing images directly and recognizing various aspects is that it opens up numerous opportunities to guide VLMs in performing tasks more efficiently and implementing “feature engineering”. If you think about it, you’ll quickly realize that you could provide images with embedded metadata that is relevant to the VLM’s task.
An example of this is to use object detection as an additional component in prompting VLMs. Such techniques are also explored in detail in this blog from AWS [10]. In this blog, I leverage an object detection model as an additional component in the prompting pipeline for the VLM.
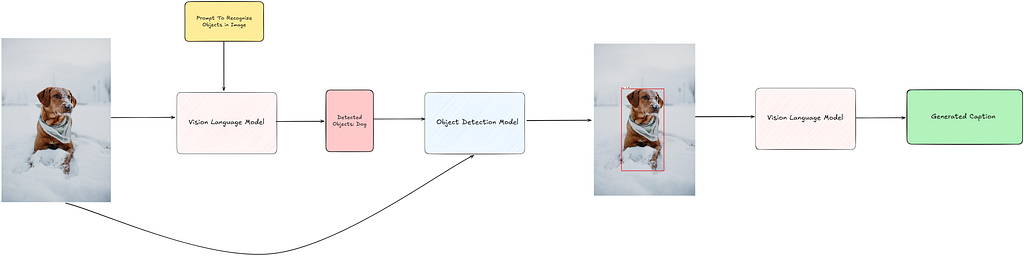
Generally, an object detection model is trained with a fixed vocabulary, meaning it can only recognize a predefined set of object categories. However, in our pipeline, since we can’t predict in advance which objects will appear in the image, we need an object detection model that is versatile and capable of recognizing a wide range of object classes. To achieve this, I use the OWL-ViT model [11], an open-vocabulary object detection model. This model requires text prompts that specifies the objects to be detected.
Another challenge that needs to be addressed is obtaining a high-level idea of the objects present in the image before utilizing the OWL-ViT model, as it requires a text prompt describing the objects. This is where VLMs come to the rescue! First, we pass the image to the VLM with a prompt to identify the high-level objects in the image. These detected objects are then used as text prompts, along with the image, for the OWL-ViT model to generate detections. Next, we plot the detections as bounding boxes on the same image and pass this updated image to the VLM, prompting it to generate a caption. The code for inference is partially adapted from [12].
# Load model directly
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
processor = AutoProcessor.from_pretrained("google/owlvit-base-patch32")
model = AutoModelForZeroShotObjectDetection.from_pretrained("google/owlvit-base-patch32")
I detect the objects present in each image using the VLM:
IMAGE_QUALITY = "high"
system_prompt_object_detection = """You are provided with an image. You must identify all important objects in the image, and provide a standardized list of objects in the image.
Return your output as follows:
Output: object_1, object_2"""
user_prompt = "Extract the objects from the provided image:"
detected_objects = process_images_in_parallel(image_paths, system_prompt=system_prompt_object_detection, user_prompt=user_prompt, model = "gpt-4o-mini", few_shot_prompt= None, detail=IMAGE_QUALITY, max_workers=5)
detected_objects_cleaned = {}
for key, value in detected_objects.items():
detected_objects_cleaned[key] = list(set([x.strip() for x in value.replace("Output: ", "").split(",")]))
The detected objects are now passed as text prompts to the OWL-ViT model to obtain the predictions for the images. I implement a helper function that predicts the bounding boxes for the images, and then plots the bounding box on the original image.
from PIL import Image, ImageDraw, ImageFont
import numpy as np
import torch
def detect_and_draw_bounding_boxes(
image_path,
text_queries,
model,
processor,
output_path,
score_threshold=0.2
):
"""
Detect objects in an image and draw bounding boxes over the original image using PIL.
Parameters:
- image_path (str): Path to the image file.
- text_queries (list of str): List of text queries to process.
- model: Pretrained model to use for detection.
- processor: Processor to preprocess image and text queries.
- output_path (str): Path to save the output image with bounding boxes.
- score_threshold (float): Threshold to filter out low-confidence predictions.
Returns:
- output_image_pil: A PIL Image object with bounding boxes and labels drawn.
"""
img = Image.open(image_path).convert("RGB")
orig_w, orig_h = img.size # original width, height
inputs = processor(
text=text_queries,
images=img,
return_tensors="pt",
padding=True,
truncation=True
).to("cpu")
model.eval()
with torch.no_grad():
outputs = model(**inputs)
logits = torch.max(outputs["logits"][0], dim=-1) # shape (num_boxes,)
scores = torch.sigmoid(logits.values).cpu().numpy() # convert to probabilities
labels = logits.indices.cpu().numpy() # class indices
boxes_norm = outputs["pred_boxes"][0].cpu().numpy() # shape (num_boxes, 4)
converted_boxes = []
for box in boxes_norm:
cx, cy, w, h = box
cx_abs = cx * orig_w
cy_abs = cy * orig_h
w_abs = w * orig_w
h_abs = h * orig_h
x1 = cx_abs - w_abs / 2.0
y1 = cy_abs - h_abs / 2.0
x2 = cx_abs + w_abs / 2.0
y2 = cy_abs + h_abs / 2.0
converted_boxes.append((x1, y1, x2, y2))
draw = ImageDraw.Draw(img)
for score, (x1, y1, x2, y2), label_idx in zip(scores, converted_boxes, labels):
if score < score_threshold:
continue
draw.rectangle([x1, y1, x2, y2], outline="red", width=3)
label_text = text_queries[label_idx].replace("An image of ", "")
text_str = f"{label_text}: {score:.2f}"
text_size = draw.textsize(text_str) # If no font used, remove "font=font"
text_x, text_y = x1, max(0, y1 - text_size[1]) # place text slightly above box
draw.rectangle(
[text_x, text_y, text_x + text_size[0], text_y + text_size[1]],
fill="white"
)
draw.text((text_x, text_y), text_str, fill="red") # , font=font)
img.save(output_path, "JPEG")
return img
for key, value in tqdm(detected_objects_cleaned.items()):
value = ["An image of " + x for x in value]
detect_and_draw_bounding_boxes(key, value, model, processor, "images_with_bounding_boxes/" + key.split("/")[-1], score_threshold=0.15)
The images with the detected objects plotted are now passed to the VLM for captioning:
IMAGE_QUALITY = "high"
image_paths_obj_detected_guided = [x.replace("downloaded_images", "images_with_bounding_boxes") for x in image_paths]
system_prompt="""You are a helpful assistant that can analyze images and provide captions. You are provided with images that also contain bounding box annotations of the important objects in them, along with their labels.
Analyze the overall image and the provided bounding box information and provide an appropriate caption for the image.""",
user_prompt="Please analyze the following image:",
obj_det_zero_shot_high_quality_captions = process_images_in_parallel(image_paths_obj_detected_guided, model = "gpt-4o-mini", few_shot_prompt= None, detail=IMAGE_QUALITY, max_workers=5)
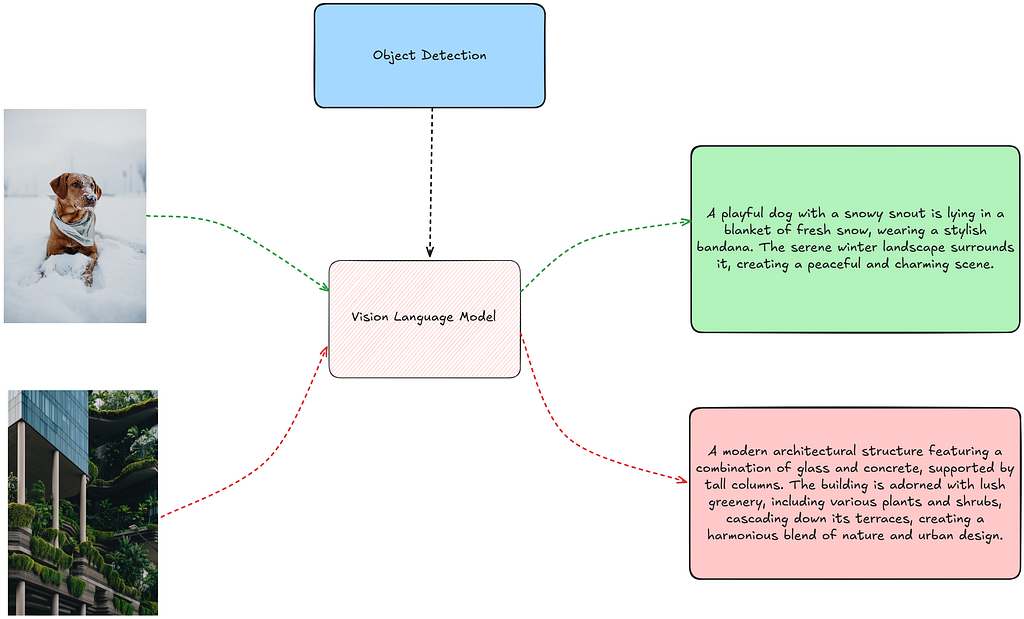
In this task, given the simple nature of the images we use, the location of the objects does not add any significant information to the VLM. However, Object Detection Guided Prompting can be a powerful tool for more complex tasks, such as Document Understanding, where layout information can be effectively provided through object detection to the VLM for further processing. Additionally, Semantic Segmentation can be employed as a method to guide prompting by providing segmentation masks to the VLM.
Conclusion
VLMs are a powerful tool in the arsenal of AI engineers and scientists for solving a variety of problems that require a combination of vision and text skills. In this article, I explore prompting strategies in the context of VLMs to effectively use these models for tasks such as image captioning. This is by no means an exhaustive or comprehensive list of prompting strategies. One thing that has become increasingly clear with the advancements in GenAI is the limitless potential for creative and innovative approaches to prompt and guide LLMs and VLMs in solving tasks.
References
[1] J. Chen, H. Guo, K. Yi, B. Li and M. Elhoseiny, “VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning,” 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 2022, pp. 18009–18019, doi: 10.1109/CVPR52688.2022.01750.
[2] Luo, Z., Xi, Y., Zhang, R., & Ma, J. (2022). A Frustratingly Simple Approach for End-to-End Image Captioning.
[3] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millicah, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karen Simonyan. 2022. Flamingo: a visual language model for few-shot learning. In Proceedings of the 36th International Conference on Neural Information Processing Systems (NIPS ‘22). Curran Associates Inc., Red Hook, NY, USA, Article 1723, 23716–23736.
[4] https://huggingface.co/blog/vision_language_pretraining
[5] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. 2018. Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, Melbourne, Australia. Association for Computational Linguistics.
[6] https://platform.openai.com/docs/guides/vision
[7] Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
[8]https://docs.ragas.io/en/stable/concepts/metrics/available_metrics/traditional/#rouge-score
[9] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., … & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824–24837.
[11] Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. 2022. Simple Open-Vocabulary Object Detection. In Computer Vision — ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part X. Springer-Verlag, Berlin, Heidelberg, 728–755. https://doi.org/10.1007/978-3-031-20080-9_42
[13] https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/gpt-4-v-prompt-engineering
Prompting Vision Language Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Exploring techniques to prompt VLMsVision Language Models (VLMs) represent a significant advancement in processing and understanding multimodal data by combining text and visual inputs.High Level Overview of VLMs. The picture of the cute dog is from Josh Frenette on Unsplash. This image is inspired by the representation of VLMs provided in this blog from HuggingFace (https://huggingface.co/blog/vlms) (Overall Image By Author)Unlike Large Language Models (LLMs), which handle only text, VLMs are multimodal, enabling users to address tasks requiring both visual and textual comprehension. This capability opens up a wide range of applications, such as Visual Question Answering (VQA), where models answer questions based on images, and Image Captioning, which involves generating descriptive text for images. In this blog post, I explain how we can prompt VLMs for tasks requiring visual understanding, and the different ways in which we can do so.Table of ContentsIntroductionPrompting with VLMsZero-Shot PromptingFew-Shot PromptingChain of Thought PromptingObject Detection Guided PromptingConclusionReferencesIntroductionVLMs are extensions of existing LLMs — particularly in that they process vision as an additional modality. VLMs are typically trained with mechanisms that align image and text representations in the same representation or vector space, using techniques like cross-attention [1] [2] [3] [4]. The advantages of such systems is that you can interact or “query” images through text as a convenient interface. Because of their multi-modal capacity, VLMs are crucial for bridging the gap between textual and visual data, opening up a large range of use cases that text-only models can’t address. For a more in-depth understanding of how VLMs, I recommend Sebastian Raschka’s excellent article on multi-modal LLMs.Prompting with VLMsIn an earlier blog, I touched upon techniques for prompting LLMs. Similar to LLMs, VLMs can also be prompted using similar techniques — with the added advantage of incorporating images to help models better understand the task at hand. In this blog, I talk about the common prompting paradigms that apply to VLMs, covering zero-shot, few-shot and chain-of-thought prompting. I also explore how other deep learning methods can help guide in prompting VLMs — such as integrating object detection into prompting strategies. For my experiments, I use OpenAI’s GPT-4o-mini model which is a VLM.All code and resources used in this blog post are available at this link on github.Data UsedFor this blogpost, I use 5 images downloaded from Unsplash that are permissively licensed for usage. Specifically, I use the following images:Photo by Mathias Reding on UnsplashPhoto by Josh Frenette on UnsplashPhoto by sander traa on UnsplashPhoto by NEOM on UnsplashPhoto by Alexander Zaytsev on UnsplashThe captions for these images are derived from the image urls, as Unsplash images come with the corresponding captions for each image.Zero-Shot PromptingZero-Shot Prompting Representation (Image by Author)Zero-Shot Prompting represents a scenario where the user only provides a description of the task through the system and user prompt, along with the image(s) to be processed. In this setup, the VLM relies only on the task description to generate an output. If we were to categorize prompting methods on a spectrum based on the amount of information provided to the VLM, zero-shot prompting presents the least amount of information to the model.The advantage for users is that, for most tasks, a well-crafted zero-shot prompt can produce decent outputs simply by describing the task in text. Consider the implications of this: just a few years ago, tasks like image classification or image captioning required training a CNN or deep learning model on a large dataset before they could be used. Now, you can perform these tasks by utilizing text to describe them. You can create an off-the-shelf image classifier by specifying and describing what you want to analyze. Before VLMs, achieving this would have required gathering a large, task-specific dataset, training a model, and then using it for inference.So how do we prompt them? OpenAI supports sending images as Base64 encoded urls to the VLM [2]. The general request structure looks like this:{ “role”: “system”, “content”: “You are a helpful assistant that can analyze images and provide captions.”},{ “role”: “user”, “content”: [ { “type”: “text”, “text”: “Please analyze the following image:” }, { “type”: “image_url”, “image_url”: { “url”: “data:image/jpeg;base64,{base64_image}”, “detail”: “detail” } } ]}The structure is largely the same as how you would prompt a normal LLM with OpenAI. However the key difference is in adding an image to the request, which needs to be encoded as a Base64 string. This is where it is actually a bit interesting — though I’m using only one image as an input here, there is nothing stopping me from also attaching multiple images to the request.Let’s implement helper functions to do zero-shot prompting. To make the experiments faster, I parallelize the requests sent to the OpenAI API. I implement helpers for constructing the prompts and calling the model for getting the outputs.def encode_image(image_path): “”” Encodes an image to a base64 string. Args: image_path (str): The file path of the image to encode. Returns: str: Base64-encoded string of the image, or None if an error occurs. “”” try: with open(image_path, “rb”) as image_file: return base64.b64encode(image_file.read()).decode(“utf-8″) except Exception as e: print(f”Error encoding image: {e}”) return None def llm_chat_completion(messages, model=”gpt-4o-mini”, max_tokens=300, temperature=0.0): “”” Calls OpenAI’s ChatCompletion API with the specified parameters. Args: messages (list): A list of message dictionaries for the conversation. model (str): The model to use for the chat completion. max_tokens (int, optional): Maximum tokens for the response. Defaults to 300. temperature (float, optional): Sampling temperature for randomness. Defaults to 0.0. Returns: str or None: The response content from the API, or None if an error occurs. “”” try: response = client.chat.completions.create( model=model, messages=messages, max_tokens=max_tokens, temperature=temperature ) return response.choices[0].message.content except Exception as e: print(f”Error calling LLM: {e}”) return Nonedef build_few_shot_messages(few_shot_prompt, user_prompt = “Please analyze the following image:”, detail=”auto”): “”” Generates few-shot example messages from image-caption pairs. Args: few_shot_prompt (dict): A dictionary mapping image paths to metadata, including “image_caption”. detail (str, optional): Level of image detail to include. Defaults to “auto”. Returns: list: A list of few-shot example messages. “”” few_shot_messages = [] for path, data in few_shot_prompt.items(): base64_image = encode_image(path) if not base64_image: continue # skip if failed to encode caption = data few_shot_messages.append( { “role”: “user”, “content”: [ {“type”: “text”, “text”: user_prompt}, { “type”: “image_url”, “image_url”: { “url”: f”data:image/jpeg;base64,{base64_image}”, “detail”: detail } }, ] } ) few_shot_messages.append({“role”: “assistant”, “content”: caption}) return few_shot_messagesdef build_user_message(image_path, user_prompt=”Please analyze the following image:”, detail=”auto”): “”” Creates a user message for analyzing a single image. Args: image_path (str): Path to the image file. detail (str, optional): Level of image detail to include. Defaults to “auto”. Returns: dict or None: The user message dictionary, or None if image encoding fails. “”” base64_image = encode_image(image_path) if not base64_image: return None return { “role”: “user”, “content”: [ {“type”: “text”, “text”: user_prompt}, { “type”: “image_url”, “image_url”: { “url”: f”data:image/jpeg;base64,{base64_image}”, “detail”: detail } }, ] }def get_image_caption( image_path, few_shot_prompt=None, system_prompt=”You are a helpful assistant that can analyze images and provide captions.”, user_prompt=”Please analyze the following image:”, model=”gpt-4o-mini”, max_tokens=300, detail=”auto”, llm_chat_func=llm_chat_completion, temperature=0.0): “”” Gets a caption for an image using a LLM. Args: image_path (str): File path of the image to be analyzed. few_shot_prompt (dict, optional): Maps image paths to {“image_caption”: <caption>}. system_prompt (str, optional): Initial system prompt for the LLM. user_prompt (str, optional): User prompt for the LLM. model (str, optional): LLM model name (default “gpt-4o-mini”). max_tokens (int, optional): Max tokens in the response (default 300). detail (str, optional): Level of detail for the image analysis (default “auto”). llm_chat_func (callable, optional): Function to call the LLM. Defaults to `llm_chat_completion`. temperature (float, optional): Sampling temperature (default 0.0). Returns: str or None: The generated caption, or None on error. “”” try: user_message = build_user_message(image_path, detail) if not user_message: return None # Build message sequence messages = [{“role”: “system”, “content”: system_prompt}] # Include few-shot examples if provided if few_shot_prompt: few_shot_messages = build_few_shot_messages(few_shot_prompt, detail) messages.extend(few_shot_messages) messages.append(user_message) # Call the LLM response_text = llm_chat_func( model=model, messages=messages, max_tokens=max_tokens, temperature=temperature ) return response_text except Exception as e: print(f”Error getting caption: {e}”) return None def process_images_in_parallel( image_paths, model=”gpt-4o-mini”, system_prompt=”You are a helpful assistant that can analyze images and provide captions.”, user_prompt=”Please analyze the following image:”, few_shot_prompt = None, max_tokens=300, detail=”auto”, max_workers=5): “”” Processes a list of images in parallel to generate captions using a specified model. Args: image_paths (list): List of file paths to the images to be processed. model (str): The model to use for generating captions (default is “gpt-4o”). max_tokens (int): Maximum number of tokens in the generated captions (default is 300). detail (str): Level of detail for the image analysis (default is “auto”). max_workers (int): Number of threads to use for parallel processing (default is 5). Returns: dict: A dictionary where keys are image paths and values are their corresponding captions. “”” captions = {} with ThreadPoolExecutor(max_workers=max_workers) as executor: # Pass additional arguments using a lambda or partial future_to_image = { executor.submit( get_image_caption, image_path, few_shot_prompt, system_prompt, user_prompt, model, max_tokens, detail): image_path for image_path in image_paths } # Use tqdm to track progress for future in tqdm(as_completed(future_to_image), total=len(image_paths), desc=”Processing images”): image_path = future_to_image[future] try: caption = future.result() captions[image_path] = caption except Exception as e: print(f”Error processing {image_path}: {e}”) captions[image_path] = None return captionsWe now run the outputs for the two images and get the corresponding caption from the zero-shot prompting setup.from tqdm import tqdmimport osIMAGE_QUALITY = “high”PATH_TO_SAMPLES = “images/”system_prompt = “””You are an AI assistant that provides captions of images. You will be provided with an image. Analyze the content, context, and notable features of the images.Provide a concise caption that covers the important aspects of the image.”””user_prompt = “Please analyze the following image:”image_paths = [os.path.join(PATH_TO_SAMPLES, x) for x in os.listdir(PATH_TO_SAMPLES)]zero_shot_high_quality_captions = process_images_in_parallel(image_paths, model = “gpt-4o-mini”, system_prompt=system_prompt, user_prompt = user_prompt, few_shot_prompt= None, detail=IMAGE_QUALITY, max_workers=5)Outputs from the Zero-Shot Setup. Images in this picture are taken by Josh Frenette on Unsplash and by Alexander Zaytsev on Unsplash (Overall Image by Author).We observe that the model gives detailed captions for the provided images, covering all the aspects in detail.Few-Shot PromptingFew-Shot Prompting involves providing examples or demostrations of the task as context to the VLM to provide more reference and context to the model about the task to be performed.Representation of Few-Shot Prompting (Image by Author)The advantages of few-shot prompting is that it helps provide additional grounding for the task, compared to zero-shot prompting. Let’s look at how this practically occurs in our task. First, consider our existing implementation:def build_few_shot_messages(few_shot_prompt, user_prompt = “Please analyze the following image:”, detail=”auto”): “”” Generates few-shot example messages from image-caption pairs. Args: few_shot_prompt (dict): A dictionary mapping image paths to metadata, including “image_caption”. detail (str, optional): Level of image detail to include. Defaults to “auto”. Returns: list: A list of few-shot example messages. “”” few_shot_messages = [] for path, data in few_shot_prompt.items(): base64_image = encode_image(path) if not base64_image: continue # skip if failed to encode caption = data few_shot_messages.append( { “role”: “user”, “content”: [ {“type”: “text”, “text”: user_prompt}, { “type”: “image_url”, “image_url”: { “url”: f”data:image/jpeg;base64,{base64_image}”, “detail”: detail } }, ] } ) few_shot_messages.append({“role”: “assistant”, “content”: caption}) return few_shot_messagesI utilize 3 images as few-shot examples to the VLM, and then run our system.image_captions = json.load(open(“image_captions.json”))FEW_SHOT_EXAMPLES_PATH = “few_shot_examples/”few_shot_samples = os.listdir(FEW_SHOT_EXAMPLES_PATH)few_shot_captions = {os.path.join(FEW_SHOT_EXAMPLES_PATH,k):v for k,v in image_captions.items() if k in few_shot_samples}IMAGE_QUALITY = “high”few_shot_high_quality_captions = process_images_in_parallel(image_paths, model = “gpt-4o-mini”, few_shot_prompt= few_shot_captions, detail=IMAGE_QUALITY, max_workers=5)Few-Shot Prompting outputs. Images in this picture are taken by Josh Frenette on Unsplash and by Alexander Zaytsev on Unsplash (Overall Image by Author).Notice the captions generated with the VLM using the few-shot examples. These captions are much shorter and concise compared to the captions generated in the zero-shot prompting setting. Let’s look at how the captions for these examples look like:The few-shot images used and their corresponding captions. Images in this picture are by Mathias Reding on Unsplash, sander traa on Unsplash, NEOM on Unsplash. (Image by author)This difference is primarily due to the influence of the few-shot examples. The captions in the few-shot examples clearly influence the output by the VLM for the new images we use, leading to more concise and shorter captions. This illustrates how powerful the selection of few-shot examples can be in shaping the behavior of the VLM. Users can direct the model’s output to more closely match their preferred style, tone, or amount of detail by carefully choosing few-shot samples.Chain of Thought PromptingChain of Thought (CoT) prompting [9], initially developed for LLMs, enables them to tackle address complex problems by breaking them into simpler, intermediate steps and encouraging the model to “think” before answering. This technique can be applied to VLMs without any adjustments. The primary difference is that the VLM can use both image and text as inputs when reasoning under CoT to answer the question.To implement this, I utilize the 3 examples I picked for few-shot prompting and construct a CoT trace for them by first utilizing OpenAI’s O1 model (which is a multimodal VLM for reasoning tasks). I then use these CoT reasoning traces as my few-shot examples for prompting the VLM. For example, a CoT trace looks like this for one of the images:CoT trace for an image. Image in this picture is from Mathias Reding on Unsplash (Image by Author)The few-shot CoT traces I created for the images contain detailed reasoning for each aspect of the image that is important for creating the final caption.few_shot_samples_1_cot = “””Observations:Visible Blur: The foreground and parts of the image are out of focus or blurred, indicating either camera movement or subject motion during the shot.Tall, Ornate Buildings: The structures have multiple floors, detailed balconies, and decorative facades, suggesting older or classic urban architecture.Street-Level View: Parked cars line both sides of a road or narrow street, confirming an urban environment with typical city traffic and infrastructure.Soft, Warm Light: The sunlight appears to be hitting the buildings at an angle, creating a warm glow on the façade and enhancing the sense of a real city scene rather than a staged setup.Final Caption: A blurry photo of a city street with buildings.”””few_shot_samples_2_cot = “””Observations: Elevated Desert Dunes: The landscape is made up of large, rolling sand dunes in a dry, arid environment. Off-Road Vehicle: The white SUV appears equipped for travel across uneven terrain, indicated by its size and ground clearance. Tire Tracks in the Sand: Visible tracks show recent movement across the dunes, reinforcing that the vehicle is in motion and navigating a desert path. View from Inside Another Car: The dashboard and windshield framing in the foreground suggest the photo is taken from a passenger’s or driver’s perspective, following behind or alongside the SUV. Final Caption: A white car driving on a desert road.”””few_shot_samples_3_cot = “””Observations:Towering Rock Formations: The steep canyon walls suggest a rugged desert landscape, with sandstone cliffs rising on both sides.Illuminated Tents: Two futuristic-looking tents emit a soft glow, indicating a nighttime scene with lights or lanterns inside.Starry Night Sky: The visible stars overhead reinforce that this is an outdoor camping scenario after dark.Single Male Figure: A man, seen from behind, stands near one of the tents, indicating he is likely part of the camping group.Final Caption: A man standing next to a tent in the desert.”””We run the CoT prompt setup for the VLM and obtain the results for these images:import copyfew_shot_samples_cot = copy.deepcopy(few_shot_captions)few_shot_samples_cot[“few_shot_examples/photo_1.jpg”] = few_shot_samples_1_cotfew_shot_samples_cot[“few_shot_examples/photo_3.jpg”] = few_shot_samples_2_cotfew_shot_samples_cot[“few_shot_examples/photo_4.jpg”] = few_shot_samples_3_cotIMAGE_QUALITY = “high”cot_high_quality_captions = process_images_in_parallel(image_paths, model = “gpt-4o-mini”, few_shot_prompt= few_shot_samples_cot, detail=IMAGE_QUALITY, max_workers=5)Outputs obtained from Chain-of-Thought prompting. Images in this picture are taken by Josh Frenette on Unsplash and by Alexander Zaytsev on Unsplash (Image by Author)The outputs from the few-shot CoT setup shows that the VLM is now capable of breaking down the image into intermediate steps before arriving at the final caption. This approach highlights the power of CoT prompting in influencing the behaviour of the VLM for a given task.Object Detection Guided PromptingAn interesting implication of having models capable of processing images directly and recognizing various aspects is that it opens up numerous opportunities to guide VLMs in performing tasks more efficiently and implementing “feature engineering”. If you think about it, you’ll quickly realize that you could provide images with embedded metadata that is relevant to the VLM’s task.An example of this is to use object detection as an additional component in prompting VLMs. Such techniques are also explored in detail in this blog from AWS [10]. In this blog, I leverage an object detection model as an additional component in the prompting pipeline for the VLM.An overview of the Object Detection Guided Prompting with VLMs. Image in this picture is taken by Josh Frenette on Unsplash (Image by Author)Generally, an object detection model is trained with a fixed vocabulary, meaning it can only recognize a predefined set of object categories. However, in our pipeline, since we can’t predict in advance which objects will appear in the image, we need an object detection model that is versatile and capable of recognizing a wide range of object classes. To achieve this, I use the OWL-ViT model [11], an open-vocabulary object detection model. This model requires text prompts that specifies the objects to be detected.Another challenge that needs to be addressed is obtaining a high-level idea of the objects present in the image before utilizing the OWL-ViT model, as it requires a text prompt describing the objects. This is where VLMs come to the rescue! First, we pass the image to the VLM with a prompt to identify the high-level objects in the image. These detected objects are then used as text prompts, along with the image, for the OWL-ViT model to generate detections. Next, we plot the detections as bounding boxes on the same image and pass this updated image to the VLM, prompting it to generate a caption. The code for inference is partially adapted from [12].# Load model directlyfrom transformers import AutoProcessor, AutoModelForZeroShotObjectDetectionprocessor = AutoProcessor.from_pretrained(“google/owlvit-base-patch32”)model = AutoModelForZeroShotObjectDetection.from_pretrained(“google/owlvit-base-patch32”)I detect the objects present in each image using the VLM:IMAGE_QUALITY = “high”system_prompt_object_detection = “””You are provided with an image. You must identify all important objects in the image, and provide a standardized list of objects in the image.Return your output as follows:Output: object_1, object_2″””user_prompt = “Extract the objects from the provided image:”detected_objects = process_images_in_parallel(image_paths, system_prompt=system_prompt_object_detection, user_prompt=user_prompt, model = “gpt-4o-mini”, few_shot_prompt= None, detail=IMAGE_QUALITY, max_workers=5)detected_objects_cleaned = {}for key, value in detected_objects.items(): detected_objects_cleaned[key] = list(set([x.strip() for x in value.replace(“Output: “, “”).split(“,”)]))The detected objects are now passed as text prompts to the OWL-ViT model to obtain the predictions for the images. I implement a helper function that predicts the bounding boxes for the images, and then plots the bounding box on the original image.from PIL import Image, ImageDraw, ImageFontimport numpy as npimport torchdef detect_and_draw_bounding_boxes( image_path, text_queries, model, processor, output_path, score_threshold=0.2): “”” Detect objects in an image and draw bounding boxes over the original image using PIL. Parameters: – image_path (str): Path to the image file. – text_queries (list of str): List of text queries to process. – model: Pretrained model to use for detection. – processor: Processor to preprocess image and text queries. – output_path (str): Path to save the output image with bounding boxes. – score_threshold (float): Threshold to filter out low-confidence predictions. Returns: – output_image_pil: A PIL Image object with bounding boxes and labels drawn. “”” img = Image.open(image_path).convert(“RGB”) orig_w, orig_h = img.size # original width, height inputs = processor( text=text_queries, images=img, return_tensors=”pt”, padding=True, truncation=True ).to(“cpu”) model.eval() with torch.no_grad(): outputs = model(**inputs) logits = torch.max(outputs[“logits”][0], dim=-1) # shape (num_boxes,) scores = torch.sigmoid(logits.values).cpu().numpy() # convert to probabilities labels = logits.indices.cpu().numpy() # class indices boxes_norm = outputs[“pred_boxes”][0].cpu().numpy() # shape (num_boxes, 4) converted_boxes = [] for box in boxes_norm: cx, cy, w, h = box cx_abs = cx * orig_w cy_abs = cy * orig_h w_abs = w * orig_w h_abs = h * orig_h x1 = cx_abs – w_abs / 2.0 y1 = cy_abs – h_abs / 2.0 x2 = cx_abs + w_abs / 2.0 y2 = cy_abs + h_abs / 2.0 converted_boxes.append((x1, y1, x2, y2)) draw = ImageDraw.Draw(img) for score, (x1, y1, x2, y2), label_idx in zip(scores, converted_boxes, labels): if score < score_threshold: continue draw.rectangle([x1, y1, x2, y2], outline=”red”, width=3) label_text = text_queries[label_idx].replace(“An image of “, “”) text_str = f”{label_text}: {score:.2f}” text_size = draw.textsize(text_str) # If no font used, remove “font=font” text_x, text_y = x1, max(0, y1 – text_size[1]) # place text slightly above box draw.rectangle( [text_x, text_y, text_x + text_size[0], text_y + text_size[1]], fill=”white” ) draw.text((text_x, text_y), text_str, fill=”red”) # , font=font) img.save(output_path, “JPEG”) return imgfor key, value in tqdm(detected_objects_cleaned.items()): value = [“An image of ” + x for x in value] detect_and_draw_bounding_boxes(key, value, model, processor, “images_with_bounding_boxes/” + key.split(“/”)[-1], score_threshold=0.15)The images with the detected objects plotted are now passed to the VLM for captioning:IMAGE_QUALITY = “high”image_paths_obj_detected_guided = [x.replace(“downloaded_images”, “images_with_bounding_boxes”) for x in image_paths] system_prompt=”””You are a helpful assistant that can analyze images and provide captions. You are provided with images that also contain bounding box annotations of the important objects in them, along with their labels.Analyze the overall image and the provided bounding box information and provide an appropriate caption for the image.”””,user_prompt=”Please analyze the following image:”,obj_det_zero_shot_high_quality_captions = process_images_in_parallel(image_paths_obj_detected_guided, model = “gpt-4o-mini”, few_shot_prompt= None, detail=IMAGE_QUALITY, max_workers=5)Outputs obtained from Object Detection Guided Prompting. Images in this picture are taken by Josh Frenette on Unsplash and by Alexander Zaytsev on Unsplash (Image by Author)In this task, given the simple nature of the images we use, the location of the objects does not add any significant information to the VLM. However, Object Detection Guided Prompting can be a powerful tool for more complex tasks, such as Document Understanding, where layout information can be effectively provided through object detection to the VLM for further processing. Additionally, Semantic Segmentation can be employed as a method to guide prompting by providing segmentation masks to the VLM.ConclusionVLMs are a powerful tool in the arsenal of AI engineers and scientists for solving a variety of problems that require a combination of vision and text skills. In this article, I explore prompting strategies in the context of VLMs to effectively use these models for tasks such as image captioning. This is by no means an exhaustive or comprehensive list of prompting strategies. One thing that has become increasingly clear with the advancements in GenAI is the limitless potential for creative and innovative approaches to prompt and guide LLMs and VLMs in solving tasks.References[1] J. Chen, H. Guo, K. Yi, B. Li and M. Elhoseiny, “VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning,” 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 2022, pp. 18009–18019, doi: 10.1109/CVPR52688.2022.01750.[2] Luo, Z., Xi, Y., Zhang, R., & Ma, J. (2022). A Frustratingly Simple Approach for End-to-End Image Captioning.[3] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millicah, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karen Simonyan. 2022. Flamingo: a visual language model for few-shot learning. In Proceedings of the 36th International Conference on Neural Information Processing Systems (NIPS ‘22). Curran Associates Inc., Red Hook, NY, USA, Article 1723, 23716–23736.[4] https://huggingface.co/blog/vision_language_pretraining[5] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. 2018. Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, Melbourne, Australia. Association for Computational Linguistics.[6] https://platform.openai.com/docs/guides/vision[7] Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.[8]https://docs.ragas.io/en/stable/concepts/metrics/available_metrics/traditional/#rouge-score[9] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., … & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824–24837.[10] https://aws.amazon.com/blogs/machine-learning/foundational-vision-models-and-visual-prompt-engineering-for-autonomous-driving-applications/[11] Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. 2022. Simple Open-Vocabulary Object Detection. In Computer Vision — ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part X. Springer-Verlag, Berlin, Heidelberg, 728–755. https://doi.org/10.1007/978-3-031-20080-9_42[12]https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb[13] https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/gpt-4-v-prompt-engineeringPrompting Vision Language Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. large-language-models, tips-and-tricks, generative-ai-tools, prompting-technique, vision-language-model Towards Data Science – MediumRead More

 Add to favorites
Add to favorites
0 Comments