
A practical approach to address bias in AI systems

As sophisticated AI systems are increasingly used in decision-making, ensuring fairness has become a priority, with a growing need to prevent algorithms from disproportionately affecting vulnerable groups in sensitive areas like the justice or educational system.
One famous example is the COMPAS algorithm, that was designed to assist the U.S. criminal justice system in making the judicial process less biased. However, evidence suggests that the algorithm has unfairly predicted a higher risk of recidivism for Black defendants, as detailed in the 2019 MIT Technology Review article [1].
In the educational system, we’re also starting to see how AI Detectors Falsely Accuse Students of Cheating — With Big Consequences [2]. For example, tools like GPTZero, Copyleaks or Turnitin’s AI-powered plagiarism detectors have been shown to unfairly target English as a Second Language (ESL) students and other vulnerable student population (e.g. neurodivergent). Although designed to maintain academic integrity, these detectors are more likely to flag non-native English speakers for plagiarism, as they tend to overfit linguistic patterns typical of ESL writing. As a non-native writer myself, this article will probably fail to pass any of these AI-powered plagiarism detectors. 😂
My previous article, “FROM Insurance Perspective: IMPORT Responsible AI Challenges and Opportunities”, highlighted the critical role that fairness plays in AI development, especially when applied to high-stakes industries like insurance. One of the key points mentioned was the “paradox of unconscious algorithm discrimination”, formally known as “fairness through Unawareness”, where AI systems, even when meticulously designed to exclude sensitive attributes like ethnicity, religion, or citizenship status, etc. can still leak bias through proxy variables like a person’s zip code. This presents a unique challenge for the insurance industry, where decisions directly impact people’s financial well-being and biased AI systems can further marginalize vulnerable groups, making fairness an even more critical priority.
This new article builds on those ideas and takes a practical approach to address bias in AI systems. Here’s what we’ll cover:
- Understanding Fairness in AI: This section introduces bias in the context of AI and illustrate its sources, explore definitions of “protected attributes” among different geographies and the complexity of intersectionality (compound marginalization), to finally present the various approaches to define fairness from a mathematical perspective.
- What tools do we have available? In recent years, a thriving ecosystem of tools and open-source libraries has emerged to help practitioners measure, explore, and mitigate bias in AI systems. This section offers a curated review of these platforms, highlighting their capabilities and limitations while presenting a two-tiered evaluation process to identify the most promising solutions for building fairer models.
- Hands-on Practical Exercise: We’ll conclude with a step-by-step practical exercise to illustrate how to measure and mitigate bias in an insurance fraud detection model using the open-source library selected in the previous section. You’ll learn how to use a handful of techniques to remove bias from your models and negotiate the tradeoff between bias and efficacy in AI models.
I’ll consider my mission accomplished if, by the end of this article, you’re not only familiar with the concept of fairness in the context AI, but also equipped to practically implement bias mitigation techniques in your own models as part of your AI development toolkit.
Understanding Fairness in AI
What is bias in the context of AI?
In the AI world, bias refers to an unwanted, systematic prejudice that leads to unfair outcomes, specific for vulnerable individuals or groups. Bias often arises when an AI system makes decisions that systematically disadvantage or favor certain populations, thereby producing unfair results. Bias can be introduced at multiple stages of the AI development process, such as during data collection, data preprocessing, data modeling or because of user interaction with the output of the AI system. For example, data imbalances — like underrepresenting certain demographics in training datasets — can cause an AI model to perform poorly for those groups, amplifying real-world inequalities instead of reducing them.
A well-known example of bias in AI was highlighted by the Gender Shades project [3] conducted in MIT’s Media Lab. This study exposed how several commercial facial recognition systems had significantly lower accuracy rates when identifying women and people with darker skin tones compared to lighter-skinned males. These discrepancies weren’t accidental — they simply reflected imbalances in the data used to train these systems, where lighter-skinned, male faces were overrepresented. Such biased outcomes can perpetuate harmful stereotypes and exacerbate existing social inequities, which may in turn damage an organization’s reputation and user’s trust.
Sources of bias
To understand the various sources that could introduce bias in an AI system, I present here the framework created by Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. in their seminal paper “A survey on bias and fairness in Machine Learning” [4], where they state that bias could be generated at three specific moments, as seen in the image below:
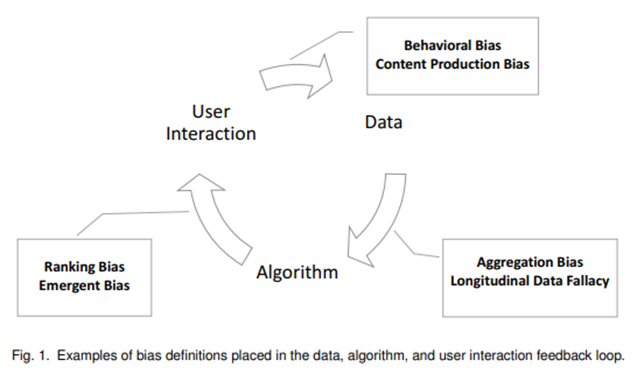
- Data to Algorithm (bias in data collection and preprocessing): Bias at this stage arises when the data used to train the algorithm is unrepresentative or skewed, often due to sampling methods, historical biases, or data preparation techniques that inadvertently favor certain groups or behaviors.

- Algorithm to User (bias in model development and deployment): Bias at this stage refers to the decisions made when developing, tuning, or deploying the algorithm, such as selecting model parameters, balancing accuracy versus fairness, or setting thresholds. These choices can lead to biased outcomes, even if the input data is fair.

- User to data (bias in user interaction and feedback loops): Bias at this stage emerges from the way users interact with the model, especially in feedback loops where user behavior influences future predictions or recommendations. Users’ actions can introduce or reinforce biases over time.

To close this section, let me introduce one example of one of the most influential papers that clearly illustrates how structural and historical biases (measurement bias, survivorship bias, sampling bias, ranking bias, social bias, among others.), left unchecked, can reinforce discriminatory outcomes.
Orchestrating Impartiality: The Impact of Blind Auditions on Female Musicians [5] by Claudia Goldin and Cecilia Rouse examines how the introduction of blind auditions, where the identity of the musician is hidden from the jury, affected the hiring of female musicians in orchestras. The study found that blind auditions significantly increased the likelihood that a woman would be selected for the orchestra.
In the context of AI and giving the increasing development of new sophisticated AI system fed by structural and historical bias data, inequality is perpetuated and reinforced.
Protected attributes
Addressing these biases requires recognizing the “protected attributes” or characteristics — such as race, gender, and age — that are often associated with increased vulnerability to bias. The specific protected attributes can vary across regions and are defined by local legislation. In AI systems, identifying and managing these attributes is essential to ensure fairness.
There follows an extensive, but most probably incomplete, list of protected attributes Explicitly Mentioned (EM) in the current legislation in Europe, the U.K., and U.S.A.
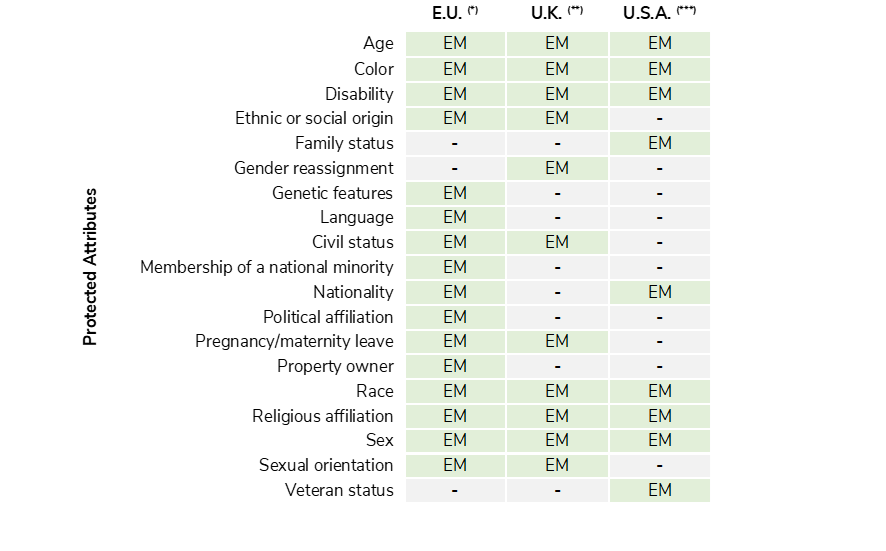
Building on the earlier idea of the paradox of (un)conscious algorithm discrimination, accessing protected attributes is essential for testing and mitigation purposes. In practice, however, some key attributes are not readily available, so alternative strategies are necessary. For instance, ethnic or social origin could be inferred by using zip codes as a bridge to link with census data or by directly inferring ethnicity based on names.
Intersectionality
Intersectionality describes the compounding effects of overlapping protected attributes — such as race, gender, and socio-economic status — on an individual’s experience of bias. AI systems often fail individuals in multiple marginalized categories, such as Black women in fraud detection. This intersectional bias is particularly damaging because it amplifies disadvantage, rather than facing one form of bias, individuals with intersecting protected attributes are more likely to suffer a cascade of biases from multiple sources, resulting in uniquely severe discrimination, Crenshaw, (2013) [14].
Focusing on individual attributes like race or gender alone fails to capture the full spectrum of discrimination experienced at these intersections, which means addressing intersectional bias is critical in developing Responsible AI systems. Attempting to correct bias in each attribute separately often overlooks the ways biases interconnect and amplify one another, and with hundreds of potential combinations, it’s not practical to address each one independently without risking underrepresentation of key intersections.
Some recent studies have shown that by prioritizing intersectionality in bias mitigation, it’s possible to address a broader range of unfair outcomes at once, Yesiltepe et al., 2024[15]. For instance, if a model is adjusted so it is fair specifically for Black women, it’s likely to improve fairness for other racial or gendered groups as well, due to the permeability of bias corrections across intersecting attributes. On this basis, targeting the most marginalized intersection of protected attributes seems like an efficient strategy for mitigating bias. However, further research is necessary to better understand the implications of this approach over internal and external validity, as well as its applications across different types of AI systems (e.g. LLM, computer vision, recommendations systems, continuous predictions, etc.).
Understanding fairness in AI
Fairness in AI is a complex topic, and it’s challenging to create a single, universal definition that applies across all countries and situations. Mehrabi et al. (2021) [4] noted that “different preferences and outlooks in different cultures lend a preference to different ways of looking at fairness”. Consequently, there are many mathematical approaches of fairness, each tailored to specific contexts and criteria. Deciding on a fairness definition in practice involves balancing these criteria and understanding that tradeoffs are often necessary.
Individual fairness: This approach focuses on treating similar individuals in similar ways. The most accepted definitions of individual fairness include:
- Fairness through unawareness: Fairness is maintained if the algorithm does not explicitly use protected attributes, like race or gender, in decision-making, Mehrabi et al., (2021) [4].
- Fairness through awareness: Similar predictions are given to individuals who are defined as “similar” based on a predefined metric of similarity, Dwork et al. (2012) [16].
- Counterfactual fairness: The intuition is that the decision would be the same in a counterfactual world where the individual belongs to a different demographic group, i.e., if we change the protected attribute whilst keeping the factors that are not causally dependent on it constant (ceteris paribus), this should not change the distribution of the predicted outcome. Kusner et al. (2021) [17].
Despite their appeal, individual fairness definitions have a limited applicability in practice. For example, omitting protected attributes alone may not remove biases due to proxy variables like zip codes. Additionally, there are not rules of the thumb to set similarity measures or defining causal relationships needed for “Fairness through awareness” and “Counterfactual fairness” when working with real-world data.
Group fairness: This approach divides a population into groups based on protected attributes and ensures equal treatment across groups. Group fairness definitions are widely used in practical applications, such as hiring or facial recognition, and they aim to create fairness across predefined categories. From this perspective, these are the two main classifications:
- Equality of outcome: This is a form of positive discrimination that favor some groups by treating them in a positive way, even if this results in differential treatment (e.g. negative discrimination toward majority groups) and compromise the accuracy, increasing the prediction error. For instance, an AI model designed to predict patient readmission rates might be adjusted to ensure equal healthcare outcomes for all racial groups, even if this means setting different risk thresholds for each group.
- Equality of opportunity: This concept emphasizes that individuals from both privileged and protected groups should have equal chances of being correctly classified based on their true characteristics. Here, the model seeks to ensure that errors in prediction (such as false positives or false negatives) are distributed evenly across groups, so not one group consistently experiences more errors than others. For instance, in a hiring algorithm, equality of opportunity would mean that qualified candidates from both minority and majority groups have the same chance of being accurately recognized as qualified, reducing the risk that one group experiences a disproportionate number of misclassifications that might unfairly block their access to opportunities. Here is a summary table with the key metrics:
- Equality of opportunity: This concept emphasizes that individuals from both privileged and protected groups should have an equal chance of being correctly classified based on their true characteristics. Here the model seeks to ensure that errors in prediction (such as false positives or false negatives) are distributed evenly across groups, so no one group consistently suffers more errors than others. For instance, in a hiring algorithm, equality of opportunity would mean that qualified candidates from both minority and majority groups have the same chance of being accurately recognized as qualified, reducing the risk that one group experiences a disproportionate number of misclassifications that might unfairly block their access to opportunities. There follows a summary table with the key metrics.
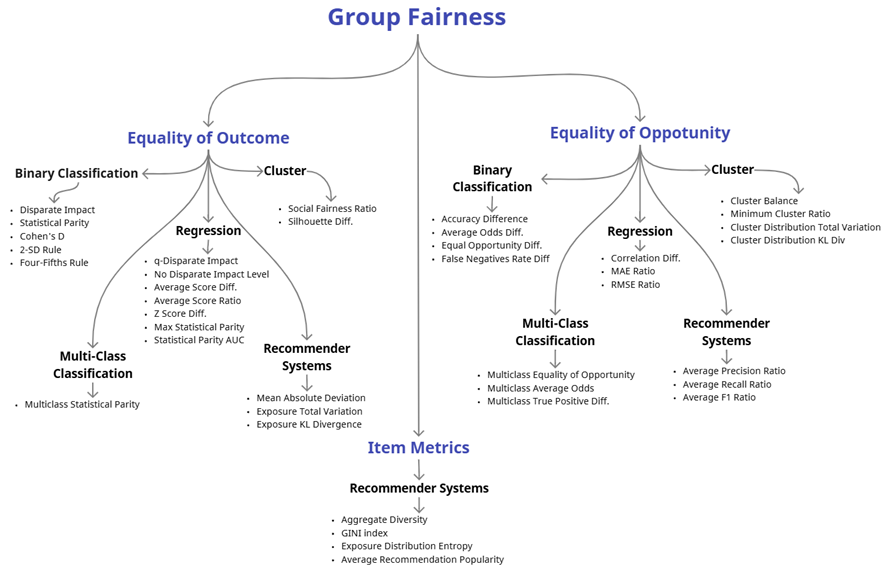
In the end, deciding which metric to use depends on the specific AI system context, and it’s necessary to consider dimensions such as type of algorithm, human-in-the-loop, business requirements, affirmative action defined governance and regulators, etc.
What tools do we have available?
Over the last five to ten years, a robust ecosystem of platforms and open-source libraries has emerged, aiming to measure, explore, and, in some cases, mitigate bias across various AI systems. This section aims to present a curated review of these platforms and libraries, offering insights into their capabilities, and limitations, for practitioners focused on building and deploying fairer models.
To optimize the evaluation process, I’ve employed a two-tiered funnel. First, the selection criteria narrow down the most promising open-source libraries, focusing on accessibility, community support, and functional relevance. Subsequently, the comparison criteria dive deeper, assessing how well these open-source libraries address diverse AI systems, tasks, and integration needs. While this analysis is based on comprehensive research, the dynamic nature of this field means some tools may evolve rapidly, potentially shifting the landscape. There follows a visual representation of the two-tiered funnel and criteria definition.
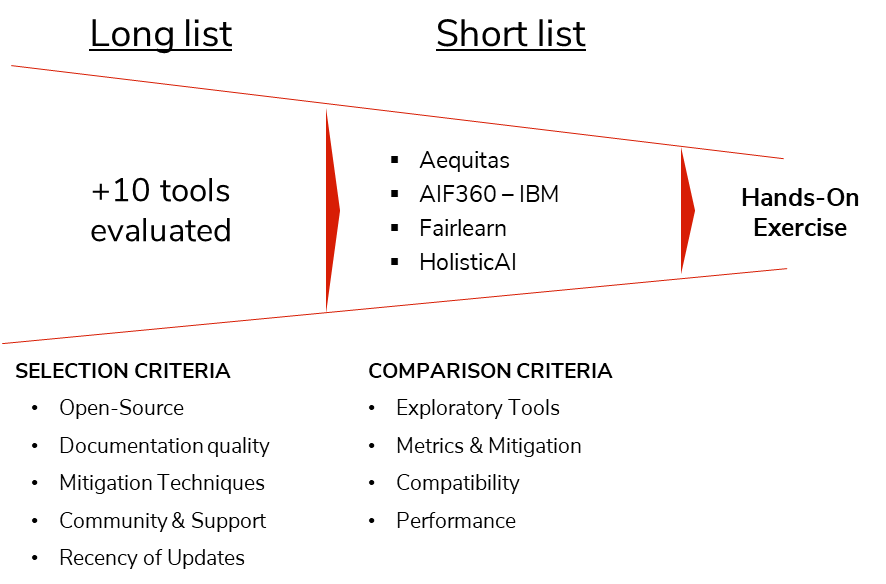
Selection criteria
Below is a description of each of the selection criteria and the tools evaluated that did not meet specific criteria.

Benchmarking
In this section, we present a comparison table with a benchmarking of four promising open-source libraries dedicated to fairness in AI, including Aequitas [27], AIF360 — IBM [28], Fairlearn — Microsoft [29], and Holistic AI [30]. These tools have been carefully selected based on their capabilities, documentation, and relevance to real-world applications. However, it’s important to note a key disclaimer: due to time constraints, the final hands-on exercise will focus on a single library, and the qualitative comparison provided here is based on insights gather from documentation, demos, examples, etc. available in official sources. This benchmark will be based on the following “Comparison Criteria”:
In this section, we present a comparison table with a benchmarking of four promising open-source libraries dedicated to fairness in AI, including Aequitas [27], AIF360 — IBM [28], Fairlearn [29], and Holistic AI[30]. These tools have been carefully selected based on their capabilities, documentation, and relevance to real-world applications. However, it’s important to note a key disclaimer: due to time constraints, the final hands-on exercise will focus on a single library, and the qualitative comparison provided here is based on insights gather from documentation, demos, examples, etc. available in official sources. This benchmark will be based on the following comparison criteria:
- Exploratory tools: Features like flowcharts or side-by-side comparisons to support bias exploration and enhance interpretability.
- Metrics and mitigation: Support for evaluating fairness across multiple AI domains, including binary classification, multi-classification, regressions, clusters, language models, computer vision, and recommender systems.
- Compatibility: Compatibility with popular Python frameworks like MLlib, Scikit-learn, TensorFlow, etc.
- Performance: How well the library balances computational demands with effectiveness in real-world applications.
The results of the benchmarking are presented in the following comparison table.
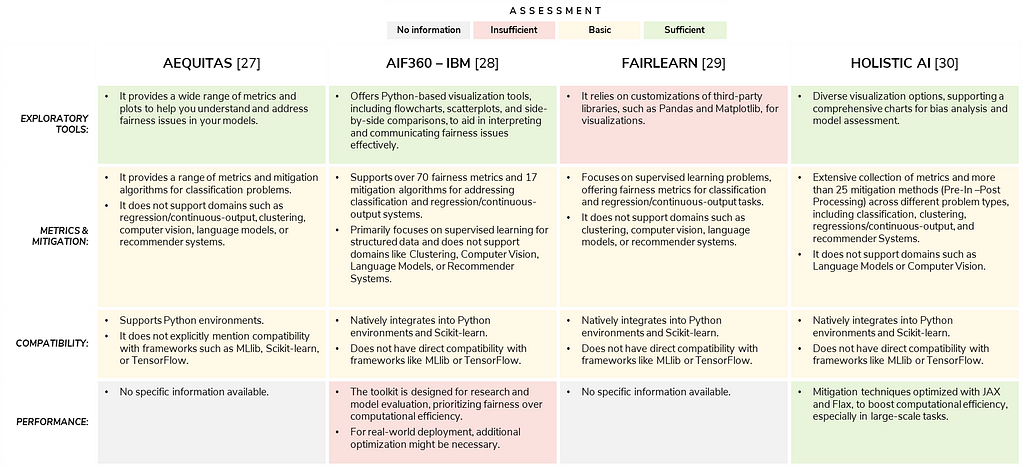
Based on the previous comparison table, the four libraries (Aequitas, AIF360, Fairlearn, and Holistic AI) each offer unique strengths and limitations in addressing fairness in AI. Nonetheless, Holistic AI emerges as a candidate for our hands-on exercise, as it offers extensive metric coverage, diverse mitigation methods, native compatibility with Python and Scikit-learn, and advanced visualization tools. Furthermore, its performance optimizations make it well-suited for practical applications in real-world scenarios like insurance fraud detection.
Hands-on exercise
Understanding the vehicle insurance fraud detection dataset
For this exercise, we will work with a publicly available vehicle insurance fraud detection dataset [31], which contains 15,420 observations and 33 features. The target variable, FraudFound_P, labels whether a claim is fraudulent, with 933 observations (5.98%) identified as fraud related. The dataset includes a range of potential predictors, such as:.
- Demographic and policy-related features: gender, age, marital status, vehicle category, policy type, policy number, driver rating.
- Claim-related features: day of week claimed, month claimed, days policy claim, witness present.
- Policy-related features: deductible, make, vehicle price, number of endorsements.
Among these, gender and age are considered protected attributes, which means we need to pay special attention to how they may influence the model’s predictions. Understanding the dataset’s structure and identifying potential sources of bias are essential.
The business challenge
The goal of this exercise is to build a machine learning model to identify potentially fraudulent motor insurance claims. Fraud detection can significantly improve claim handling efficiency, reduce investigation costs, and minimize losses paid out on fraudulent claims. However, the dataset presents a significant challenge due to the high-class imbalance, with only 5.98% of the claims labeled as fraudulent.
In the context of fraud detection, false negatives (i.e., missed fraudulent claims) are particularly expensive, as they result in financial losses and investigation delays. To address this, we will prioritize the recall metric for identifying the positive class (FraudFound_P = 1). Recall measures the ability of the model to capture fraudulent claims, even at the expense of precision, ensuring that as many fraudulent claims as possible are identified and handled in a timely fashion by analysts in the fraud team.
Baseline model
Here, we will build the initial model for fraud detection using a set of predictors that include demographic and policy-related features, with an emphasis on the gender attribute. For the purposes of this exercise, the gender feature has explicitly been included as a predictor to intentionally introduce bias and force its appearance in the model, given that excluding it would result in a baseline model that is not biased. Moreover, in a real-world setting with a more comprehensive dataset, there are usually indirect proxies that may leak bias into the model. In practice, it is common for models to inadvertently use such proxies, leading to unwanted biased predictions, even when the sensitive attributes themselves are not directly included.
In addition, we excluded age as a predictor, aligning with the individual fairness approach known as “fairness through unawareness,” where we intentionally remove any sensitive attributes that could lead to discriminatory outcomes.
In the following image, we present the Classification Results, Distribution of Predicted Probabilities, and Lift Chart for the baseline model using the XGBoost classifier with a custom threshold of 0.1 (y_prob >= threshold) to identify predicted positive fraudulent claims. This model will serve as a starting point for measuring and mitigating bias, which we will explore in later sections.
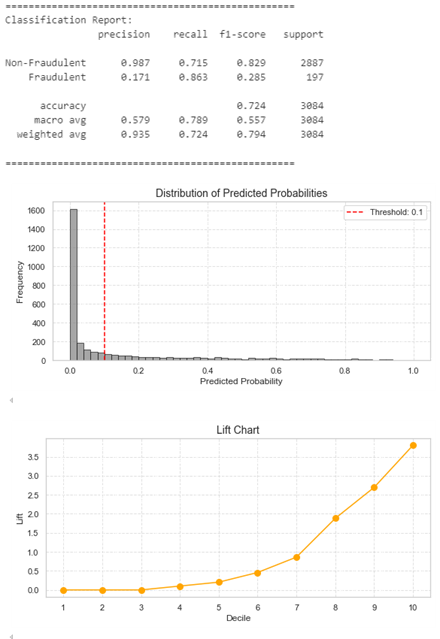
Based on the classification results and visualizations presented below, we can see that the model reaches a Recall of 86%, which is in line with our business requirements. Since our primary goal is to identify as many fraudulent claims as possible, high recall is crucial. The model correctly identifies most of the fraudulent claims, even though the precision for fraudulent claims (17%) is lower. This trade-off is acceptable given that high recall ensures that the fraud investigation team can focus on most fraudulent claims, minimizing potential financial losses.
The distribution of predicted probabilities shows a significant concentration of predictions near zero, indicating that the model is classifying many claims as non-fraudulent. This is expected given the highly imbalanced nature of the dataset (fraudulent claims represent only 5.98% of the total claims). Moreover, the Lift Chart highlights that focusing on the top deciles provides significant gains in identifying fraudulent claims. The model’s ability to increase the detection of fraud in the higher deciles (with a lift of 3.5x in the 10th decile) supports the business objective of prioritizing the investigation of claims that are more likely to be fraudulent, increasing the efficiency of the efforts of the fraud detection team.
These results align with the business goal of improving fraud detection efficiency while minimizing costs associated with investigating non-fraudulent claims. The recall value of 86% ensures that we are not missing a large portion of fraudulent claims, while the lift chart allows us to prioritize resources effectively.
Measuring bias
Based on the XGBoost classifier, we evaluate the potential bias in our fraud detection model using binary metrics from the Holistic AI library. The code snippet below illustrates this.
from holisticai.bias.metrics import classification_bias_metrics
from holisticai.bias.plots import bias_metrics_report
# Define protected attributes (group_a and group_b)
group_a_test = X_test['PA_Female'].values
group_b_test = X_test['PA_Male'].values
# Evaluate bias metrics with the custom threshold
metrics = classification_bias_metrics( group_a=group_a_test, group_b=group_b_test, y_pred=y_pred, y_true=y_test)
print("Bias Metrics with Custom Threshold: n", metrics)
bias_metrics_report(model_type='binary_classification', table_metrics=metrics)
Given the nature of the dataset and the business challenge, we focus on Equality of Opportunity metrics to ensure that individuals from both groups have equal chances of being correctly classified based on their true characteristics. Specifically, we aim to ensure that errors in prediction, such as false positives or false negatives, are distributed evenly across groups. This way, no group experiences disproportionately more errors than others, which is essential for achieving fairness in decision-making. For this exercise, we focus on the gender attribute (male and female), which is intentionally included as a predictor in the model to assess its impact on fairness.
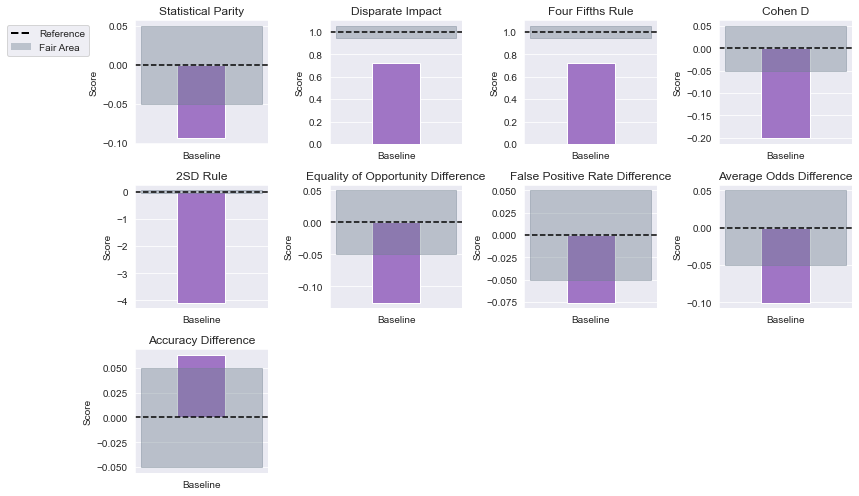
The Equality of Opportunity bias metrics generated using a custom threshold of 0.1 for classification are presented below.
- Equality of Opportunity Difference: -0.126
This metric directly evaluates whether the true positive rate is equal across the groups. A negative value suggests that females are slightly less likely to be correctly classified as fraudulent compared to males, indicating a potential bias favoring males in correctly identifying fraud. - False Positive Rate Difference: -0.076
The False Positive Rate difference is within the fair interval [-0.1, 0.1], indicating no significant disparity in the false positive rates between groups. - Average Odds Difference: -0.101
Average odds difference measures the balance of true positive and false positive rates across groups. A negative value here suggests that the model might be slightly less accurate in identifying fraudulent claims for females than for males. - Accuracy Difference: 0.063
The Accuracy difference is within the fair interval [-0.1, 0.1], indicating minimal bias in overall accuracy between groups.
There are small but significant disparities in Equality of Opportunity and Average Odds Difference, with females being slightly less likely to be correctly classified as fraudulent. This suggests a potential area for improvement, where further steps could be taken to reduce these biases and enhance fairness for both groups.
As we proceed in the next sections, we’ll explore techniques for mitigating this bias and improving fairness, while striving to maintain model performance.
Mitigating bias
In the effort to mitigate bias from the baseline model, the binary mitigation algorithms included in the Holistic AI library were tested. These algorithms used can be categorized into three types:
- Pre-processing methods aim to modify the input data such that any model trained on it would no longer exhibit biases. These methods adjust the data distribution to ensure fairness before training begins. The algorithm evaluated were, Correlation Remover, Disparate Impact Remover, Learning Fair Representations and Reweighing.
- In-processing methods alter the learning process itself, directly influencing the model during training to ensure fairer predictions. These methods aim to achieve fairness during the optimization process. The algorithm evaluated were, Adversarial Debiasing, Exponentiated Gradient, Grid Search Reduction, Meta Fair Classifier, and Prejudice Remover.
- Post-processing methods adjust the model’s predictions after it has been trained, ensuring that the final predictions satisfy some statistical measure of fairness. The algorithm evaluated were, Calibrated Equalized Odds, Equalized Odds, LP Debiaser, ML Debiaser, and Reject Option.
The results from applying the various mitigation algorithms, focusing on key performance and fairness metrics are presented in the accompanying table.
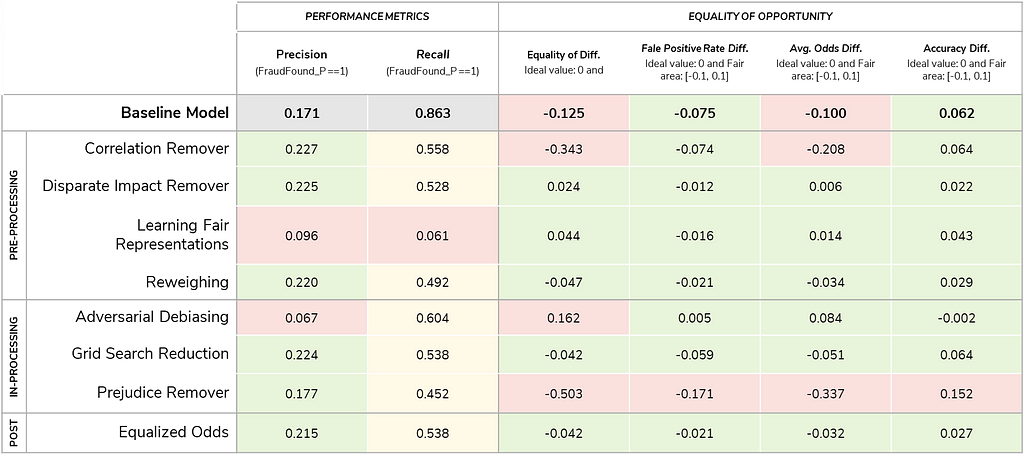
While none of the algorithms tested outperformed the baseline model, the Disparate impact remover (a pre-processing method) and Equalized odds (a post-processing method) showed promising results. Both algorithms improved the fairness metrics significantly, but neither produced results as close to the baseline model’s performance as expected. Moreover, I found that adjusting the threshold for Disparate impact remover and Equalized odds facilitated matching baseline performance while keeping equality of opportunity bias metrics within the fair interval.
Following academic recommendations stating that post-processing methods can be substantially sub-optimal (Woodworth et al., 2017)[32], in that they impact on the model after it was learned and can lead to higher performance degradation when compared to other methods (Ding et al., 2021)[33], I decided to prioritize the Disparate Impact Remover pre-processing algorithm over the post-processing Equalized Odds method. The code snippet below illustrates this process.
from holisticai.bias.mitigation import (AdversarialDebiasing, ExponentiatedGradientReduction, GridSearchReduction, MetaFairClassifier,
PrejudiceRemover, CorrelationRemover, DisparateImpactRemover, LearningFairRepresentation, Reweighing,
CalibratedEqualizedOdds, EqualizedOdds, LPDebiaserBinary, MLDebiaser, RejectOptionClassification)
from holisticai.pipeline import Pipeline
# Step 1: Define the Disparate Impact Remover (Pre-processing)
mitigator = DisparateImpactRemover(repair_level=1.0) # Repair level: 0.0 (no change) to 1.0 (full repair)
# Step 2: Define the XGBoost model
model = XGBClassifier(use_label_encoder=False, eval_metric='logloss')
# Step 3: Create a pipeline with Disparate Impact Remover and XGBoost
pipeline = Pipeline(steps=[
('scaler', StandardScaler()), # Standardize the data
('bm_preprocessing', mitigator), # Apply bias mitigation
('estimator', model) # Train the XGBoost model
])
# Step 4: Fit the pipeline
pipeline.fit(
X_train_processed, y_train,
bm__group_a=group_a_train, bm__group_b=group_b_train # Pass sensitive groups
)
# Step 5: Make predictions with the pipeline
y_prob = pipeline.predict_proba(
X_test_processed,
bm__group_a=group_a_test, bm__group_b=group_b_test
)[:, 1] # Probability for the positive class
# Step 6: Apply a custom threshold
threshold = 0.03
y_pred = (y_prob >= threshold).astype(int)
We further customized the Disparate impact remover algorithm by lowering the probability threshold, aiming to improve model fairness while maintaining key performance metrics. This adjustment was made to explore the potential impact on both model performance and bias mitigation.
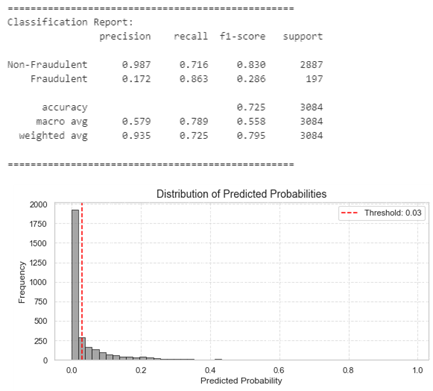
The results show that by adjusting the threshold from 0.1 to 0.03, we significantly improved recall for fraudulent claims (from 0.528 in the baseline to 0.863), but at the cost of precision (which dropped from 0.225 to 0.172). This aligns with the business objective of minimizing undetected fraudulent claims, despite a slight increase in false positives. The tradeoff is adequate: reducing the threshold increases the model’s sensitivity (higher recall) but leads to more false positives (lower precision). However, the overall accuracy of the model is only slightly impacted (from 0.725 to 0.716), reflecting the broader tradeoff between recall and precision that often accompanies threshold adjustments in imbalanced datasets like fraud detection.
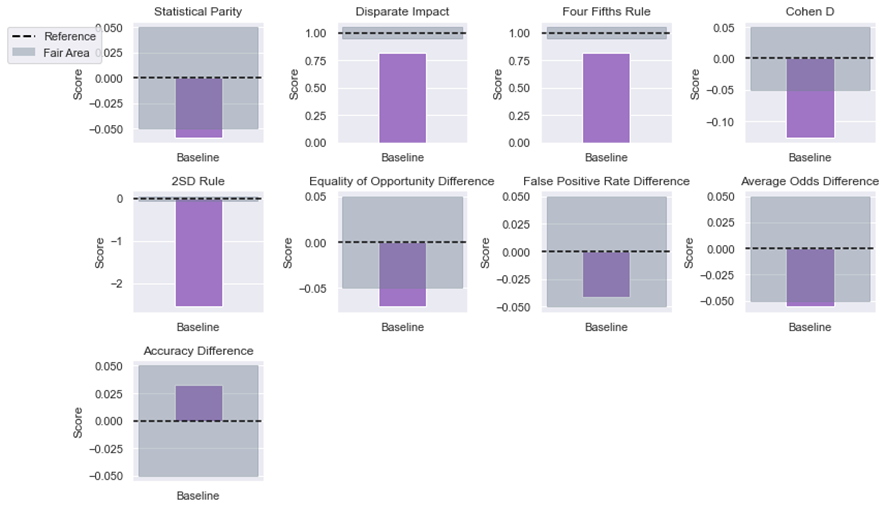
The equality of opportunity bias metrics show minimal impact after adjusting the threshold to 0.03. The Equality of opportunity difference remains within the fair interval at -0.070, indicating that the model still provides equal chances of being correctly classified for both groups. The False positive rate difference of -0.041 and the Average odds difference of -0.056 both stay within the acceptable range, suggesting no significant bias favoring one group over the other. The Accuracy difference of 0.032 also remains small, confirming that the model’s overall accuracy is not disproportionately affected by the threshold adjustment. These results demonstrate that the fairness of the model, in terms of equality of opportunity, is well-maintained even with the threshold change.
Moreover, adjusting the probability threshold is necessary when working with imbalanced datasets such as fraud detection. The distribution of predicted probabilities will change with each mitigation strategy applied, and thresholds should be reviewed and adapted accordingly to balance both performance and fairness, as well as other dimensions not considered in this article (e.g., explainability or privacy). The choice of threshold can significantly influence the model’s behavior, and final decisions should be carefully adjusted based on business needs.
In conclusion, the Disparate impact remover with a threshold of 0.03 offers a reasonable compromise, improving recall for fraudulent claims while maintaining fairness in equality of opportunity metrics. This strategy aligns with both business objectives and fairness considerations, making it a viable approach for mitigating bias in fraud detection models.
Final thoughts…
- Context matters. Fairness metrics are not universal truths. A metric that seems favorable in one scenario might signify something entirely different in another. Always consider the context and relevance to your specific use case, remember that bias is a complex and multifaceted issue.
- Don’t rely on a single metric. No single metric can capture the complexities of fairness. Relying on just one risks overlooking critical issues. Employ a diverse set of metrics to gain a comprehensive understanding.
- Correlation does not imply causation. Disparities in fairness metrics across groups don’t automatically indicate bias. These differences might stem from underlying data characteristics or other factors. Investigate thoroughly before drawing conclusions.
- Beware of trade-offs. Enhancing fairness might sometimes come at the expense of accuracy, privacy or explainability. Carefully evaluate these trade-offs and align them with your overarching goals and priorities.
- Fairness is an ongoing process. Fairness isn’t a one-time achievement. Models evolve, and data changes over time, potentially introducing new biases. Regularly monitor fairness metrics to stay proactive in addressing emerging challenges.
The future of bias detection tools lies in their integration with broader AI ethics frameworks, improved algorithms for bias detection and mitigation, and the development of industry standards for fairness in AI.
Notes and references
[1] MIT Technology Review article. URL: https://www.technologyreview.com/2019/10/17/75285/ai-fairer-than-judge-criminal-risk-assessment-algorithm/ (last accessed 16 Jan 2025).
[2] Bloomberg article. URL: https://www.bloomberg.com/news/features/2024-10-18/do-ai-detectors-work-students-face-false-cheating-accusations?utm_source=substack&utm_medium=email (last accessed 16 Jan 2025).
[3] Genders Shades Project. URL: https://www.media.mit.edu/projects/gender-shades/overview/ (last accessed 16 Jan 2025).
[4] Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. (2021). A survey on bias and fairness in machine learning. ACM computing surveys (CSUR), 54(6), 1–35.
[5] Goldin, C., & Rouse, C. (2000). Orchestrating impartiality: The impact of “blind” auditions on female musicians. American economic review, 90(4), 715–741.
[6] Fundamental Rights of the European Union. URL: https://eur-lex.europa.eu/eli/treaty/char_2012/oj (last accessed 16 Jan 2025).
[7] General framework for equal treatment in employment and occupation. URL: https://eur-lex.europa.eu/eli/dir/2000/78/oj (last accessed 16 Jan 2025).
[8] Principle of equal treatment between persons irrespective of racial or ethnic origin. URL: https://eur-lex.europa.eu/eli/dir/2000/43/oj (last accessed 16 Jan 2025).
[9] Equality Act 2010. URL https://www.legislation.gov.uk/ukpga/2010/15/contents (last accessed 16 Jan 2025).
[10] UK Justice-Types of discrimination (protected characteristics). URL: https://www.gov.uk/discrimination-your-rights (last accessed 16 Jan 2025).
[11] Age Discrimination in Employment Act of 1967. URL: https://www.eeoc.gov/statutes/age-discrimination-employment-act-1967 (last accessed 16 Jan 2025).
[12] Americans with Disabilities Act. URL: https://www.ada.gov/topics/intro-to-ada/ (last accessed 16 Jan 2025).
[13] Civil Rights Act of 1964 (Title VII). URL: https://www.eeoc.gov/statutes/title-vii-civil-rights-act-1964 (last accessed 16 Jan 2025).
[14] Cho, S., Crenshaw, K. W., & McCall, L. (2013). Toward a field of intersectionality studies: Theory, applications, and praxis. Signs: Journal of women in culture and society, 38(4), 785–810.
[15] Yesiltepe, H., Akdemir, K., & Yanardag, P. (2024). MIST: Mitigating Intersectional Bias with Disentangled Cross-Attention Editing in Text-to-Image Diffusion Models. arXiv preprint arXiv:2403.19738.
[16] Dwork, C., Hardt, M., Pitassi, T., Reingold, O., & Zemel, R. (2012, January). Fairness through awareness. In Proceedings of the 3rd innovations in theoretical computer science conference (pp. 214–226).
[17] Kusner, M. J., Loftus, J., Russell, C., & Silva, R. (2017). Counterfactual fairness. Advances in neural information processing systems, 30.
[18] Holistic AI readthedocs fairness metrics. URL: https://holisticai.readthedocs.io/en/latest/getting_started/bias/metrics.html#summary-table (last accessed 16 Jan 2025).
[19] Credo AI. URL: https://www.credo.ai/ (last accessed 16 Jan 2025).
[20] Fairnow. URL: https://fairnow.ai/ (last accessed 16 Jan 2025).
[21] MindFoundry. URL: https://www.mindfoundry.ai/ (last accessed 16 Jan 2025).
[22] Modulos. URL: https://www.modulos.ai/ (last accessed 16 Jan 2025).
[23] Monitaur. ULR: https://www.monitaur.ai/ (last accessed 16 Jan 2025).
[24] Fairness indicator — Google. URL: https://github.com/tensorflow/fairness-indicators (last accessed 16 Jan 2025).
[25] Credo AI Lens. URL: https://github.com/credo-ai/credoai_lens (last accessed 16 Jan 2025).
[26] Themis-ML. ULR: https://github.com/cosmicBboy/themis-ml (last accessed 16 Jan 2025).
[27] Aequitas. URL: https://github.com/dssg/aequitas (last accessed 16 Jan 2025).
[28] AIF360 — IBM. URL: https://github.com/Trusted-AI/AIF360 (last accessed 16 Jan 2025).
[29] Fairlearn — Microsoft. URL: https://github.com/fairlearn/fairlearn (last accessed 16 Jan 2025).
[30] Holistic AI. URL: https://github.com/holistic-ai/holisticai (last accessed 16 Jan 2025).
[31] Available at https://www.kaggle.com/datasets/shivamb/vehicle-claim-fraud-detection (last accessed 16 Jan 2025). Licensed under CC0: Public Domain.
[32] Woodworth, B., Gunasekar, S., Ohannessian, M. I., & Srebro, N. (2017, June). Learning non-discriminatory predictors. In Conference on Learning Theory (pp. 1920–1953). PMLR.
[33] Frances Ding, Moritz Hardt, John Miller, and Ludwig Schmidt. Retiring adult: New datasets for fair machine learning. In Thirty-Fifth Conference on Neural Information Processing Systems, 2021.
Fighting Fraud Fairly: Upgrade Your AI Toolkit 🧰 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
A practical approach to address bias in AI systemsPhoto by the authorAs sophisticated AI systems are increasingly used in decision-making, ensuring fairness has become a priority, with a growing need to prevent algorithms from disproportionately affecting vulnerable groups in sensitive areas like the justice or educational system.One famous example is the COMPAS algorithm, that was designed to assist the U.S. criminal justice system in making the judicial process less biased. However, evidence suggests that the algorithm has unfairly predicted a higher risk of recidivism for Black defendants, as detailed in the 2019 MIT Technology Review article [1].In the educational system, we’re also starting to see how AI Detectors Falsely Accuse Students of Cheating — With Big Consequences [2]. For example, tools like GPTZero, Copyleaks or Turnitin’s AI-powered plagiarism detectors have been shown to unfairly target English as a Second Language (ESL) students and other vulnerable student population (e.g. neurodivergent). Although designed to maintain academic integrity, these detectors are more likely to flag non-native English speakers for plagiarism, as they tend to overfit linguistic patterns typical of ESL writing. As a non-native writer myself, this article will probably fail to pass any of these AI-powered plagiarism detectors. 😂My previous article, “FROM Insurance Perspective: IMPORT Responsible AI Challenges and Opportunities”, highlighted the critical role that fairness plays in AI development, especially when applied to high-stakes industries like insurance. One of the key points mentioned was the “paradox of unconscious algorithm discrimination”, formally known as “fairness through Unawareness”, where AI systems, even when meticulously designed to exclude sensitive attributes like ethnicity, religion, or citizenship status, etc. can still leak bias through proxy variables like a person’s zip code. This presents a unique challenge for the insurance industry, where decisions directly impact people’s financial well-being and biased AI systems can further marginalize vulnerable groups, making fairness an even more critical priority.This new article builds on those ideas and takes a practical approach to address bias in AI systems. Here’s what we’ll cover:Understanding Fairness in AI: This section introduces bias in the context of AI and illustrate its sources, explore definitions of “protected attributes” among different geographies and the complexity of intersectionality (compound marginalization), to finally present the various approaches to define fairness from a mathematical perspective.What tools do we have available? In recent years, a thriving ecosystem of tools and open-source libraries has emerged to help practitioners measure, explore, and mitigate bias in AI systems. This section offers a curated review of these platforms, highlighting their capabilities and limitations while presenting a two-tiered evaluation process to identify the most promising solutions for building fairer models.Hands-on Practical Exercise: We’ll conclude with a step-by-step practical exercise to illustrate how to measure and mitigate bias in an insurance fraud detection model using the open-source library selected in the previous section. You’ll learn how to use a handful of techniques to remove bias from your models and negotiate the tradeoff between bias and efficacy in AI models.I’ll consider my mission accomplished if, by the end of this article, you’re not only familiar with the concept of fairness in the context AI, but also equipped to practically implement bias mitigation techniques in your own models as part of your AI development toolkit.Understanding Fairness in AIWhat is bias in the context of AI?In the AI world, bias refers to an unwanted, systematic prejudice that leads to unfair outcomes, specific for vulnerable individuals or groups. Bias often arises when an AI system makes decisions that systematically disadvantage or favor certain populations, thereby producing unfair results. Bias can be introduced at multiple stages of the AI development process, such as during data collection, data preprocessing, data modeling or because of user interaction with the output of the AI system. For example, data imbalances — like underrepresenting certain demographics in training datasets — can cause an AI model to perform poorly for those groups, amplifying real-world inequalities instead of reducing them.A well-known example of bias in AI was highlighted by the Gender Shades project [3] conducted in MIT’s Media Lab. This study exposed how several commercial facial recognition systems had significantly lower accuracy rates when identifying women and people with darker skin tones compared to lighter-skinned males. These discrepancies weren’t accidental — they simply reflected imbalances in the data used to train these systems, where lighter-skinned, male faces were overrepresented. Such biased outcomes can perpetuate harmful stereotypes and exacerbate existing social inequities, which may in turn damage an organization’s reputation and user’s trust.Sources of biasTo understand the various sources that could introduce bias in an AI system, I present here the framework created by Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. in their seminal paper “A survey on bias and fairness in Machine Learning” [4], where they state that bias could be generated at three specific moments, as seen in the image below:Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. in their seminal paper “A survey on bias and fairness in Machine Learning” [4]Data to Algorithm (bias in data collection and preprocessing): Bias at this stage arises when the data used to train the algorithm is unrepresentative or skewed, often due to sampling methods, historical biases, or data preparation techniques that inadvertently favor certain groups or behaviors.Table by the author based on Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K. and Galstyan, A., 2021. A survey on bias and fairness in machine learning. ACM computing surveys (CSUR), 54(6), pp.1–35.: [4]Algorithm to User (bias in model development and deployment): Bias at this stage refers to the decisions made when developing, tuning, or deploying the algorithm, such as selecting model parameters, balancing accuracy versus fairness, or setting thresholds. These choices can lead to biased outcomes, even if the input data is fair.Table by the author based on Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K. and Galstyan, A., 2021. A survey on bias and fairness in machine learning. ACM computing surveys (CSUR), 54(6), pp.1–35.: [4User to data (bias in user interaction and feedback loops): Bias at this stage emerges from the way users interact with the model, especially in feedback loops where user behavior influences future predictions or recommendations. Users’ actions can introduce or reinforce biases over time.Table compiled by the author based on Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K. and Galstyan, A., 2021. A survey on bias and fairness in machine learning. ACM computing surveys (CSUR), 54(6), pp.1–35.: [4]To close this section, let me introduce one example of one of the most influential papers that clearly illustrates how structural and historical biases (measurement bias, survivorship bias, sampling bias, ranking bias, social bias, among others.), left unchecked, can reinforce discriminatory outcomes.Orchestrating Impartiality: The Impact of Blind Auditions on Female Musicians [5] by Claudia Goldin and Cecilia Rouse examines how the introduction of blind auditions, where the identity of the musician is hidden from the jury, affected the hiring of female musicians in orchestras. The study found that blind auditions significantly increased the likelihood that a woman would be selected for the orchestra.In the context of AI and giving the increasing development of new sophisticated AI system fed by structural and historical bias data, inequality is perpetuated and reinforced.Protected attributesAddressing these biases requires recognizing the “protected attributes” or characteristics — such as race, gender, and age — that are often associated with increased vulnerability to bias. The specific protected attributes can vary across regions and are defined by local legislation. In AI systems, identifying and managing these attributes is essential to ensure fairness.There follows an extensive, but most probably incomplete, list of protected attributes Explicitly Mentioned (EM) in the current legislation in Europe, the U.K., and U.S.A.Table created by the author based on (*) Fundamental Rights of the European Union [6], General framework for equal treatment in employment and occupation [7], and Principle of equal treatment between persons irrespective of racial or ethnic origin [8]; (**) Equality Act 2010 [9], and UK Justice-Types of discrimination (‘protected characteristics’) [10]; (***) Age Discrimination in Employment Act of 1967 [11], Americans with Disabilities Act [12], and Civil Rights Act of 1964 (Title VII) [13].Building on the earlier idea of the paradox of (un)conscious algorithm discrimination, accessing protected attributes is essential for testing and mitigation purposes. In practice, however, some key attributes are not readily available, so alternative strategies are necessary. For instance, ethnic or social origin could be inferred by using zip codes as a bridge to link with census data or by directly inferring ethnicity based on names.IntersectionalityIntersectionality describes the compounding effects of overlapping protected attributes — such as race, gender, and socio-economic status — on an individual’s experience of bias. AI systems often fail individuals in multiple marginalized categories, such as Black women in fraud detection. This intersectional bias is particularly damaging because it amplifies disadvantage, rather than facing one form of bias, individuals with intersecting protected attributes are more likely to suffer a cascade of biases from multiple sources, resulting in uniquely severe discrimination, Crenshaw, (2013) [14].Focusing on individual attributes like race or gender alone fails to capture the full spectrum of discrimination experienced at these intersections, which means addressing intersectional bias is critical in developing Responsible AI systems. Attempting to correct bias in each attribute separately often overlooks the ways biases interconnect and amplify one another, and with hundreds of potential combinations, it’s not practical to address each one independently without risking underrepresentation of key intersections.Some recent studies have shown that by prioritizing intersectionality in bias mitigation, it’s possible to address a broader range of unfair outcomes at once, Yesiltepe et al., 2024[15]. For instance, if a model is adjusted so it is fair specifically for Black women, it’s likely to improve fairness for other racial or gendered groups as well, due to the permeability of bias corrections across intersecting attributes. On this basis, targeting the most marginalized intersection of protected attributes seems like an efficient strategy for mitigating bias. However, further research is necessary to better understand the implications of this approach over internal and external validity, as well as its applications across different types of AI systems (e.g. LLM, computer vision, recommendations systems, continuous predictions, etc.).Understanding fairness in AIFairness in AI is a complex topic, and it’s challenging to create a single, universal definition that applies across all countries and situations. Mehrabi et al. (2021) [4] noted that “different preferences and outlooks in different cultures lend a preference to different ways of looking at fairness”. Consequently, there are many mathematical approaches of fairness, each tailored to specific contexts and criteria. Deciding on a fairness definition in practice involves balancing these criteria and understanding that tradeoffs are often necessary.Individual fairness: This approach focuses on treating similar individuals in similar ways. The most accepted definitions of individual fairness include:Fairness through unawareness: Fairness is maintained if the algorithm does not explicitly use protected attributes, like race or gender, in decision-making, Mehrabi et al., (2021) [4].Fairness through awareness: Similar predictions are given to individuals who are defined as “similar” based on a predefined metric of similarity, Dwork et al. (2012) [16].Counterfactual fairness: The intuition is that the decision would be the same in a counterfactual world where the individual belongs to a different demographic group, i.e., if we change the protected attribute whilst keeping the factors that are not causally dependent on it constant (ceteris paribus), this should not change the distribution of the predicted outcome. Kusner et al. (2021) [17].Despite their appeal, individual fairness definitions have a limited applicability in practice. For example, omitting protected attributes alone may not remove biases due to proxy variables like zip codes. Additionally, there are not rules of the thumb to set similarity measures or defining causal relationships needed for “Fairness through awareness” and “Counterfactual fairness” when working with real-world data.Group fairness: This approach divides a population into groups based on protected attributes and ensures equal treatment across groups. Group fairness definitions are widely used in practical applications, such as hiring or facial recognition, and they aim to create fairness across predefined categories. From this perspective, these are the two main classifications:Equality of outcome: This is a form of positive discrimination that favor some groups by treating them in a positive way, even if this results in differential treatment (e.g. negative discrimination toward majority groups) and compromise the accuracy, increasing the prediction error. For instance, an AI model designed to predict patient readmission rates might be adjusted to ensure equal healthcare outcomes for all racial groups, even if this means setting different risk thresholds for each group.Equality of opportunity: This concept emphasizes that individuals from both privileged and protected groups should have equal chances of being correctly classified based on their true characteristics. Here, the model seeks to ensure that errors in prediction (such as false positives or false negatives) are distributed evenly across groups, so not one group consistently experiences more errors than others. For instance, in a hiring algorithm, equality of opportunity would mean that qualified candidates from both minority and majority groups have the same chance of being accurately recognized as qualified, reducing the risk that one group experiences a disproportionate number of misclassifications that might unfairly block their access to opportunities. Here is a summary table with the key metrics:Equality of opportunity: This concept emphasizes that individuals from both privileged and protected groups should have an equal chance of being correctly classified based on their true characteristics. Here the model seeks to ensure that errors in prediction (such as false positives or false negatives) are distributed evenly across groups, so no one group consistently suffers more errors than others. For instance, in a hiring algorithm, equality of opportunity would mean that qualified candidates from both minority and majority groups have the same chance of being accurately recognized as qualified, reducing the risk that one group experiences a disproportionate number of misclassifications that might unfairly block their access to opportunities. There follows a summary table with the key metrics.Image created by the author based on Holistic AI readthedocs fairness metrics [18]In the end, deciding which metric to use depends on the specific AI system context, and it’s necessary to consider dimensions such as type of algorithm, human-in-the-loop, business requirements, affirmative action defined governance and regulators, etc.What tools do we have available?Over the last five to ten years, a robust ecosystem of platforms and open-source libraries has emerged, aiming to measure, explore, and, in some cases, mitigate bias across various AI systems. This section aims to present a curated review of these platforms and libraries, offering insights into their capabilities, and limitations, for practitioners focused on building and deploying fairer models.To optimize the evaluation process, I’ve employed a two-tiered funnel. First, the selection criteria narrow down the most promising open-source libraries, focusing on accessibility, community support, and functional relevance. Subsequently, the comparison criteria dive deeper, assessing how well these open-source libraries address diverse AI systems, tasks, and integration needs. While this analysis is based on comprehensive research, the dynamic nature of this field means some tools may evolve rapidly, potentially shifting the landscape. There follows a visual representation of the two-tiered funnel and criteria definition.Two-tiered funnel. Image by the authorSelection criteriaBelow is a description of each of the selection criteria and the tools evaluated that did not meet specific criteria.Table compiled by the authorBenchmarkingIn this section, we present a comparison table with a benchmarking of four promising open-source libraries dedicated to fairness in AI, including Aequitas [27], AIF360 — IBM [28], Fairlearn — Microsoft [29], and Holistic AI [30]. These tools have been carefully selected based on their capabilities, documentation, and relevance to real-world applications. However, it’s important to note a key disclaimer: due to time constraints, the final hands-on exercise will focus on a single library, and the qualitative comparison provided here is based on insights gather from documentation, demos, examples, etc. available in official sources. This benchmark will be based on the following “Comparison Criteria”:In this section, we present a comparison table with a benchmarking of four promising open-source libraries dedicated to fairness in AI, including Aequitas [27], AIF360 — IBM [28], Fairlearn [29], and Holistic AI[30]. These tools have been carefully selected based on their capabilities, documentation, and relevance to real-world applications. However, it’s important to note a key disclaimer: due to time constraints, the final hands-on exercise will focus on a single library, and the qualitative comparison provided here is based on insights gather from documentation, demos, examples, etc. available in official sources. This benchmark will be based on the following comparison criteria:Exploratory tools: Features like flowcharts or side-by-side comparisons to support bias exploration and enhance interpretability.Metrics and mitigation: Support for evaluating fairness across multiple AI domains, including binary classification, multi-classification, regressions, clusters, language models, computer vision, and recommender systems.Compatibility: Compatibility with popular Python frameworks like MLlib, Scikit-learn, TensorFlow, etc.Performance: How well the library balances computational demands with effectiveness in real-world applications.The results of the benchmarking are presented in the following comparison table.Table created by the author based on documentation, demos, examples, etc. available in [27], [28], [29], and [30]Based on the previous comparison table, the four libraries (Aequitas, AIF360, Fairlearn, and Holistic AI) each offer unique strengths and limitations in addressing fairness in AI. Nonetheless, Holistic AI emerges as a candidate for our hands-on exercise, as it offers extensive metric coverage, diverse mitigation methods, native compatibility with Python and Scikit-learn, and advanced visualization tools. Furthermore, its performance optimizations make it well-suited for practical applications in real-world scenarios like insurance fraud detection.Hands-on exerciseUnderstanding the vehicle insurance fraud detection datasetFor this exercise, we will work with a publicly available vehicle insurance fraud detection dataset [31], which contains 15,420 observations and 33 features. The target variable, FraudFound_P, labels whether a claim is fraudulent, with 933 observations (5.98%) identified as fraud related. The dataset includes a range of potential predictors, such as:.Demographic and policy-related features: gender, age, marital status, vehicle category, policy type, policy number, driver rating.Claim-related features: day of week claimed, month claimed, days policy claim, witness present.Policy-related features: deductible, make, vehicle price, number of endorsements.Among these, gender and age are considered protected attributes, which means we need to pay special attention to how they may influence the model’s predictions. Understanding the dataset’s structure and identifying potential sources of bias are essential.The business challengeThe goal of this exercise is to build a machine learning model to identify potentially fraudulent motor insurance claims. Fraud detection can significantly improve claim handling efficiency, reduce investigation costs, and minimize losses paid out on fraudulent claims. However, the dataset presents a significant challenge due to the high-class imbalance, with only 5.98% of the claims labeled as fraudulent.In the context of fraud detection, false negatives (i.e., missed fraudulent claims) are particularly expensive, as they result in financial losses and investigation delays. To address this, we will prioritize the recall metric for identifying the positive class (FraudFound_P = 1). Recall measures the ability of the model to capture fraudulent claims, even at the expense of precision, ensuring that as many fraudulent claims as possible are identified and handled in a timely fashion by analysts in the fraud team.Baseline modelHere, we will build the initial model for fraud detection using a set of predictors that include demographic and policy-related features, with an emphasis on the gender attribute. For the purposes of this exercise, the gender feature has explicitly been included as a predictor to intentionally introduce bias and force its appearance in the model, given that excluding it would result in a baseline model that is not biased. Moreover, in a real-world setting with a more comprehensive dataset, there are usually indirect proxies that may leak bias into the model. In practice, it is common for models to inadvertently use such proxies, leading to unwanted biased predictions, even when the sensitive attributes themselves are not directly included.In addition, we excluded age as a predictor, aligning with the individual fairness approach known as “fairness through unawareness,” where we intentionally remove any sensitive attributes that could lead to discriminatory outcomes.In the following image, we present the Classification Results, Distribution of Predicted Probabilities, and Lift Chart for the baseline model using the XGBoost classifier with a custom threshold of 0.1 (y_prob >= threshold) to identify predicted positive fraudulent claims. This model will serve as a starting point for measuring and mitigating bias, which we will explore in later sections.Baseline model results. Image compiled by the authorBased on the classification results and visualizations presented below, we can see that the model reaches a Recall of 86%, which is in line with our business requirements. Since our primary goal is to identify as many fraudulent claims as possible, high recall is crucial. The model correctly identifies most of the fraudulent claims, even though the precision for fraudulent claims (17%) is lower. This trade-off is acceptable given that high recall ensures that the fraud investigation team can focus on most fraudulent claims, minimizing potential financial losses.The distribution of predicted probabilities shows a significant concentration of predictions near zero, indicating that the model is classifying many claims as non-fraudulent. This is expected given the highly imbalanced nature of the dataset (fraudulent claims represent only 5.98% of the total claims). Moreover, the Lift Chart highlights that focusing on the top deciles provides significant gains in identifying fraudulent claims. The model’s ability to increase the detection of fraud in the higher deciles (with a lift of 3.5x in the 10th decile) supports the business objective of prioritizing the investigation of claims that are more likely to be fraudulent, increasing the efficiency of the efforts of the fraud detection team.These results align with the business goal of improving fraud detection efficiency while minimizing costs associated with investigating non-fraudulent claims. The recall value of 86% ensures that we are not missing a large portion of fraudulent claims, while the lift chart allows us to prioritize resources effectively.Measuring biasBased on the XGBoost classifier, we evaluate the potential bias in our fraud detection model using binary metrics from the Holistic AI library. The code snippet below illustrates this.from holisticai.bias.metrics import classification_bias_metricsfrom holisticai.bias.plots import bias_metrics_report# Define protected attributes (group_a and group_b)group_a_test = X_test[‘PA_Female’].valuesgroup_b_test = X_test[‘PA_Male’].values# Evaluate bias metrics with the custom thresholdmetrics = classification_bias_metrics( group_a=group_a_test, group_b=group_b_test, y_pred=y_pred, y_true=y_test)print(“Bias Metrics with Custom Threshold: n”, metrics)bias_metrics_report(model_type=’binary_classification’, table_metrics=metrics)Given the nature of the dataset and the business challenge, we focus on Equality of Opportunity metrics to ensure that individuals from both groups have equal chances of being correctly classified based on their true characteristics. Specifically, we aim to ensure that errors in prediction, such as false positives or false negatives, are distributed evenly across groups. This way, no group experiences disproportionately more errors than others, which is essential for achieving fairness in decision-making. For this exercise, we focus on the gender attribute (male and female), which is intentionally included as a predictor in the model to assess its impact on fairness.Bias metrics report of baseline model. Image compiled by the authorThe Equality of Opportunity bias metrics generated using a custom threshold of 0.1 for classification are presented below.Equality of Opportunity Difference: -0.126 This metric directly evaluates whether the true positive rate is equal across the groups. A negative value suggests that females are slightly less likely to be correctly classified as fraudulent compared to males, indicating a potential bias favoring males in correctly identifying fraud.False Positive Rate Difference: -0.076 The False Positive Rate difference is within the fair interval [-0.1, 0.1], indicating no significant disparity in the false positive rates between groups.Average Odds Difference: -0.101 Average odds difference measures the balance of true positive and false positive rates across groups. A negative value here suggests that the model might be slightly less accurate in identifying fraudulent claims for females than for males.Accuracy Difference: 0.063 The Accuracy difference is within the fair interval [-0.1, 0.1], indicating minimal bias in overall accuracy between groups.There are small but significant disparities in Equality of Opportunity and Average Odds Difference, with females being slightly less likely to be correctly classified as fraudulent. This suggests a potential area for improvement, where further steps could be taken to reduce these biases and enhance fairness for both groups.As we proceed in the next sections, we’ll explore techniques for mitigating this bias and improving fairness, while striving to maintain model performance.Mitigating biasIn the effort to mitigate bias from the baseline model, the binary mitigation algorithms included in the Holistic AI library were tested. These algorithms used can be categorized into three types:Pre-processing methods aim to modify the input data such that any model trained on it would no longer exhibit biases. These methods adjust the data distribution to ensure fairness before training begins. The algorithm evaluated were, Correlation Remover, Disparate Impact Remover, Learning Fair Representations and Reweighing.In-processing methods alter the learning process itself, directly influencing the model during training to ensure fairer predictions. These methods aim to achieve fairness during the optimization process. The algorithm evaluated were, Adversarial Debiasing, Exponentiated Gradient, Grid Search Reduction, Meta Fair Classifier, and Prejudice Remover.Post-processing methods adjust the model’s predictions after it has been trained, ensuring that the final predictions satisfy some statistical measure of fairness. The algorithm evaluated were, Calibrated Equalized Odds, Equalized Odds, LP Debiaser, ML Debiaser, and Reject Option.The results from applying the various mitigation algorithms, focusing on key performance and fairness metrics are presented in the accompanying table.Comparison table of mitigation algorithm results. Table compiled by the authorWhile none of the algorithms tested outperformed the baseline model, the Disparate impact remover (a pre-processing method) and Equalized odds (a post-processing method) showed promising results. Both algorithms improved the fairness metrics significantly, but neither produced results as close to the baseline model’s performance as expected. Moreover, I found that adjusting the threshold for Disparate impact remover and Equalized odds facilitated matching baseline performance while keeping equality of opportunity bias metrics within the fair interval.Following academic recommendations stating that post-processing methods can be substantially sub-optimal (Woodworth et al., 2017)[32], in that they impact on the model after it was learned and can lead to higher performance degradation when compared to other methods (Ding et al., 2021)[33], I decided to prioritize the Disparate Impact Remover pre-processing algorithm over the post-processing Equalized Odds method. The code snippet below illustrates this process.from holisticai.bias.mitigation import (AdversarialDebiasing, ExponentiatedGradientReduction, GridSearchReduction, MetaFairClassifier, PrejudiceRemover, CorrelationRemover, DisparateImpactRemover, LearningFairRepresentation, Reweighing, CalibratedEqualizedOdds, EqualizedOdds, LPDebiaserBinary, MLDebiaser, RejectOptionClassification)from holisticai.pipeline import Pipeline# Step 1: Define the Disparate Impact Remover (Pre-processing)mitigator = DisparateImpactRemover(repair_level=1.0) # Repair level: 0.0 (no change) to 1.0 (full repair)# Step 2: Define the XGBoost modelmodel = XGBClassifier(use_label_encoder=False, eval_metric=’logloss’)# Step 3: Create a pipeline with Disparate Impact Remover and XGBoostpipeline = Pipeline(steps=[ (‘scaler’, StandardScaler()), # Standardize the data (‘bm_preprocessing’, mitigator), # Apply bias mitigation (‘estimator’, model) # Train the XGBoost model])# Step 4: Fit the pipelinepipeline.fit( X_train_processed, y_train, bm__group_a=group_a_train, bm__group_b=group_b_train # Pass sensitive groups)# Step 5: Make predictions with the pipeliney_prob = pipeline.predict_proba( X_test_processed, bm__group_a=group_a_test, bm__group_b=group_b_test)[:, 1] # Probability for the positive class# Step 6: Apply a custom thresholdthreshold = 0.03y_pred = (y_prob >= threshold).astype(int)We further customized the Disparate impact remover algorithm by lowering the probability threshold, aiming to improve model fairness while maintaining key performance metrics. This adjustment was made to explore the potential impact on both model performance and bias mitigation.Results of de-biased model (Disparate Impact Remover). Image compiled by the authorThe results show that by adjusting the threshold from 0.1 to 0.03, we significantly improved recall for fraudulent claims (from 0.528 in the baseline to 0.863), but at the cost of precision (which dropped from 0.225 to 0.172). This aligns with the business objective of minimizing undetected fraudulent claims, despite a slight increase in false positives. The tradeoff is adequate: reducing the threshold increases the model’s sensitivity (higher recall) but leads to more false positives (lower precision). However, the overall accuracy of the model is only slightly impacted (from 0.725 to 0.716), reflecting the broader tradeoff between recall and precision that often accompanies threshold adjustments in imbalanced datasets like fraud detection.Bias metrics report for de-biased model (Disparate Impact Remover). Image compiled by the authorThe equality of opportunity bias metrics show minimal impact after adjusting the threshold to 0.03. The Equality of opportunity difference remains within the fair interval at -0.070, indicating that the model still provides equal chances of being correctly classified for both groups. The False positive rate difference of -0.041 and the Average odds difference of -0.056 both stay within the acceptable range, suggesting no significant bias favoring one group over the other. The Accuracy difference of 0.032 also remains small, confirming that the model’s overall accuracy is not disproportionately affected by the threshold adjustment. These results demonstrate that the fairness of the model, in terms of equality of opportunity, is well-maintained even with the threshold change.Moreover, adjusting the probability threshold is necessary when working with imbalanced datasets such as fraud detection. The distribution of predicted probabilities will change with each mitigation strategy applied, and thresholds should be reviewed and adapted accordingly to balance both performance and fairness, as well as other dimensions not considered in this article (e.g., explainability or privacy). The choice of threshold can significantly influence the model’s behavior, and final decisions should be carefully adjusted based on business needs.In conclusion, the Disparate impact remover with a threshold of 0.03 offers a reasonable compromise, improving recall for fraudulent claims while maintaining fairness in equality of opportunity metrics. This strategy aligns with both business objectives and fairness considerations, making it a viable approach for mitigating bias in fraud detection models.Final thoughts…Context matters. Fairness metrics are not universal truths. A metric that seems favorable in one scenario might signify something entirely different in another. Always consider the context and relevance to your specific use case, remember that bias is a complex and multifaceted issue.Don’t rely on a single metric. No single metric can capture the complexities of fairness. Relying on just one risks overlooking critical issues. Employ a diverse set of metrics to gain a comprehensive understanding.Correlation does not imply causation. Disparities in fairness metrics across groups don’t automatically indicate bias. These differences might stem from underlying data characteristics or other factors. Investigate thoroughly before drawing conclusions.Beware of trade-offs. Enhancing fairness might sometimes come at the expense of accuracy, privacy or explainability. Carefully evaluate these trade-offs and align them with your overarching goals and priorities.Fairness is an ongoing process. Fairness isn’t a one-time achievement. Models evolve, and data changes over time, potentially introducing new biases. Regularly monitor fairness metrics to stay proactive in addressing emerging challenges.The future of bias detection tools lies in their integration with broader AI ethics frameworks, improved algorithms for bias detection and mitigation, and the development of industry standards for fairness in AI.Notes and references[1] MIT Technology Review article. URL: https://www.technologyreview.com/2019/10/17/75285/ai-fairer-than-judge-criminal-risk-assessment-algorithm/ (last accessed 16 Jan 2025).[2] Bloomberg article. URL: https://www.bloomberg.com/news/features/2024-10-18/do-ai-detectors-work-students-face-false-cheating-accusations?utm_source=substack&utm_medium=email (last accessed 16 Jan 2025).[3] Genders Shades Project. URL: https://www.media.mit.edu/projects/gender-shades/overview/ (last accessed 16 Jan 2025).[4] Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. (2021). A survey on bias and fairness in machine learning. ACM computing surveys (CSUR), 54(6), 1–35.[5] Goldin, C., & Rouse, C. (2000). Orchestrating impartiality: The impact of “blind” auditions on female musicians. American economic review, 90(4), 715–741.[6] Fundamental Rights of the European Union. URL: https://eur-lex.europa.eu/eli/treaty/char_2012/oj (last accessed 16 Jan 2025).[7] General framework for equal treatment in employment and occupation. URL: https://eur-lex.europa.eu/eli/dir/2000/78/oj (last accessed 16 Jan 2025).[8] Principle of equal treatment between persons irrespective of racial or ethnic origin. URL: https://eur-lex.europa.eu/eli/dir/2000/43/oj (last accessed 16 Jan 2025).[9] Equality Act 2010. URL https://www.legislation.gov.uk/ukpga/2010/15/contents (last accessed 16 Jan 2025).[10] UK Justice-Types of discrimination (protected characteristics). URL: https://www.gov.uk/discrimination-your-rights (last accessed 16 Jan 2025).[11] Age Discrimination in Employment Act of 1967. URL: https://www.eeoc.gov/statutes/age-discrimination-employment-act-1967 (last accessed 16 Jan 2025).[12] Americans with Disabilities Act. URL: https://www.ada.gov/topics/intro-to-ada/ (last accessed 16 Jan 2025).[13] Civil Rights Act of 1964 (Title VII). URL: https://www.eeoc.gov/statutes/title-vii-civil-rights-act-1964 (last accessed 16 Jan 2025).[14] Cho, S., Crenshaw, K. W., & McCall, L. (2013). Toward a field of intersectionality studies: Theory, applications, and praxis. Signs: Journal of women in culture and society, 38(4), 785–810.[15] Yesiltepe, H., Akdemir, K., & Yanardag, P. (2024). MIST: Mitigating Intersectional Bias with Disentangled Cross-Attention Editing in Text-to-Image Diffusion Models. arXiv preprint arXiv:2403.19738.[16] Dwork, C., Hardt, M., Pitassi, T., Reingold, O., & Zemel, R. (2012, January). Fairness through awareness. In Proceedings of the 3rd innovations in theoretical computer science conference (pp. 214–226).[17] Kusner, M. J., Loftus, J., Russell, C., & Silva, R. (2017). Counterfactual fairness. Advances in neural information processing systems, 30.[18] Holistic AI readthedocs fairness metrics. URL: https://holisticai.readthedocs.io/en/latest/getting_started/bias/metrics.html#summary-table (last accessed 16 Jan 2025).[19] Credo AI. URL: https://www.credo.ai/ (last accessed 16 Jan 2025).[20] Fairnow. URL: https://fairnow.ai/ (last accessed 16 Jan 2025).[21] MindFoundry. URL: https://www.mindfoundry.ai/ (last accessed 16 Jan 2025).[22] Modulos. URL: https://www.modulos.ai/ (last accessed 16 Jan 2025).[23] Monitaur. ULR: https://www.monitaur.ai/ (last accessed 16 Jan 2025).[24] Fairness indicator — Google. URL: https://github.com/tensorflow/fairness-indicators (last accessed 16 Jan 2025).[25] Credo AI Lens. URL: https://github.com/credo-ai/credoai_lens (last accessed 16 Jan 2025).[26] Themis-ML. ULR: https://github.com/cosmicBboy/themis-ml (last accessed 16 Jan 2025).[27] Aequitas. URL: https://github.com/dssg/aequitas (last accessed 16 Jan 2025).[28] AIF360 — IBM. URL: https://github.com/Trusted-AI/AIF360 (last accessed 16 Jan 2025).[29] Fairlearn — Microsoft. URL: https://github.com/fairlearn/fairlearn (last accessed 16 Jan 2025).[30] Holistic AI. URL: https://github.com/holistic-ai/holisticai (last accessed 16 Jan 2025).[31] Available at https://www.kaggle.com/datasets/shivamb/vehicle-claim-fraud-detection (last accessed 16 Jan 2025). Licensed under CC0: Public Domain.[32] Woodworth, B., Gunasekar, S., Ohannessian, M. I., & Srebro, N. (2017, June). Learning non-discriminatory predictors. In Conference on Learning Theory (pp. 1920–1953). PMLR.[33] Frances Ding, Moritz Hardt, John Miller, and Ludwig Schmidt. Retiring adult: New datasets for fair machine learning. In Thirty-Fifth Conference on Neural Information Processing Systems, 2021.Fighting Fraud Fairly: Upgrade Your AI Toolkit 🧰 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. editors-pick, responsible-ai, fraud, bias, fairness Towards Data Science – MediumRead More

 Add to favorites
Add to favorites


0 Comments