
Integration architecture focusing on security and access control

1. Introduction
Microsoft Fabric and Azure Databricks are both powerhouses in the data analytics field. These platforms can be used end-to-end in a medallion architecture, from data ingestion to creating data products for end users. Azure Databricks excels in the initial stages due to its strength in processing large datasets and populating the different zones of the lakehouse. Microsoft Fabric performs well in the latter stages when data is consumed. Coming from Power BI, the SaaS setup is easy to use and it provides self-service capabilities to end users.
Given the different strengths of these products and that many customers do not have a greenfield situation, a strategic decision can be to integrate the products. You must then find a logical integration point where both products “meet”. This shall be done with security in mind as this is a top priority for all enterprises.
This blog post first explores three different integration options: Lakehouse split, virtualization with shortcuts, and exposing via SQL API. SQL API is a common integration point between back end and front end and the security architecture of this integration is discussed in more detail in chapter 3. See already the architecture diagram below.
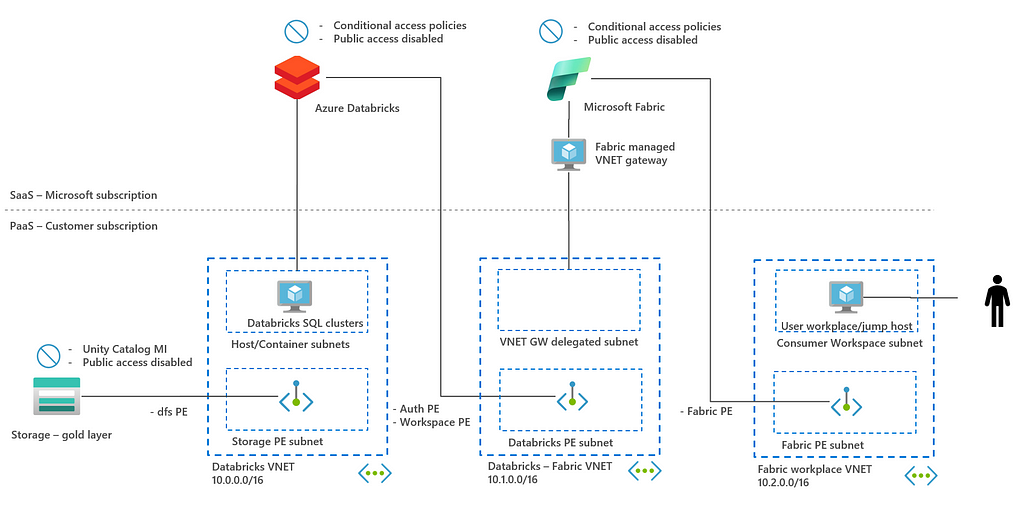
2. Azure Databricks — Microsoft Fabric integration overview
Before diving into the details of securing SQL API architecture, it is helpful to briefly discuss the different options for integrating Azure Databricks and Microsoft Fabric. This chapter outlines three options, highlighting their advantages and disadvantages. For a more extensive overview, refer to this blog.
2.1 Lakehouse split: Bronze, silver zone in Databricks | gold zone in Fabric
In this architecture, you can find that data is processed by Databricks up to the silver zone. Fabric copies and processes the data to gold zone in Fabric using V-Ordering. Gold zone data is exposed via a Fabric lakehouse such that data products can be created for end users, see image below.

The advantage of this architecture is that data is optimized for data consumption in Fabric. The disadvantage is that the lakehouse is split over two tools which adds complexity and can give challenges in data governance (Unity Catalog for bronze/silver, but not for gold).
This architecture is most applicable to companies that place a strong emphasis on data analytics in Microsoft Fabric and may even want to eventually migrate the entire lakehouse to Microsoft Fabric.
2.2 Virtualization: Lakehouse in Databricks | shortcuts to Fabric
In this architecture, all data is in the lakehouse is processed by Databricks. Data is virtualized to Microsoft Fabric Lakehouse using ADLSgen2 shortcuts or even a mirrored Azure Databricks Unity Catalog in Fabric, see also the image below.
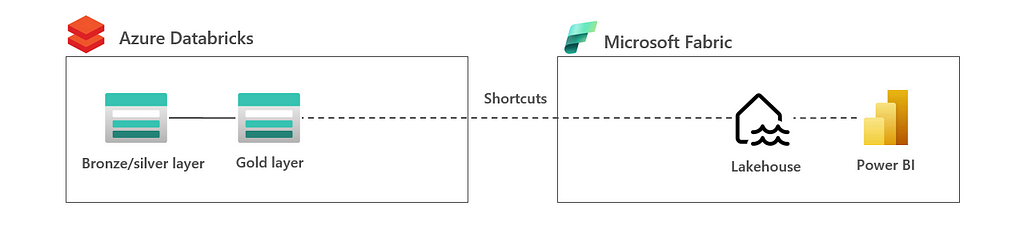
The advantage of this architecture is that lakehouse is owned by a single tool which gives less challenges in integration and governance. The disadvantage is that data is not optimized for Fabric consumption. In this, you may require additional copies in Fabric to apply V-Ordering, and so optimize for Fabric consumption.
This architecture is most applicable for companies that want to keep the lakehouse Databricks owned and want to enable end users to do analytics in Fabric in which the lack of V-Ordering is not much of a concern. The latter could be true if the data sizes are not too big and/or end users need a data copy anyway.
2.3 Exposing SQL API: Lakehouse in Databricks | SQL API to Fabric
In this architecture, all data is in the lakehouse is processed by Databricks again. However, in this architecture the data is exposed to Fabric using the SQL API. In this, you can decide to use a dedicated Databricks SQL Warehouse or serverless SQL. The main difference with shortcut architecture in the previous bullet, is that data is processed in Databricks rather than Fabric. This can be compared to when a web app fires a SQL query to a database; the query is executed in the database.
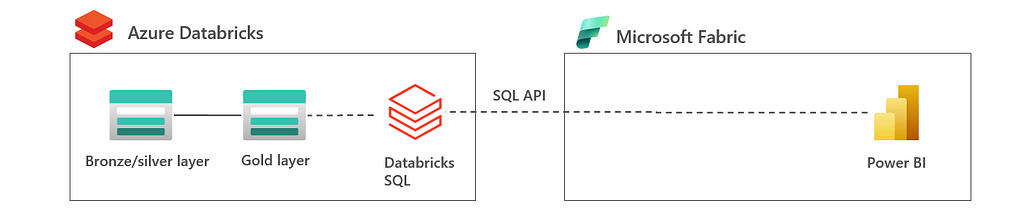
The advantage of this architecture is that lakehouse is owned by a single tool which gives less challenges in integration and governance. Also, SQL API provides a clean interface between Azure Databricks and Microsoft Fabric with less coupling compared to shortcuts. The disadvantage is that end users in Fabric are limited to the Databricks SQL and Fabric is merely used as reporting tool rather than analytics tool.
This architecture is most applicable for companies that want to keep the lakehouse Databricks-owned and are looking to enhance Azure Databricks with the Power BI capabilities that Microsoft Fabric offers.
In the next chapter, a security architecture is discussed for this SQL API integration.
3. Exposing SQL API: security architecture
In this chapter, security architecture is discussed for this SQL API integration. The rationale is that integrating SQL API is a common touch point where back end and front end meet. Furthermore, most security recommendations are applicable for the other architectures discussed earlier.
3.1 Advanced SQL API architecture
To achieve defense in depth, networking isolation and identity-based access control are the two most important steps. You can find this in the diagram below, that was already provided in the introduction of this blog.
In this diagram, three key connectivities that need to be secured are highlighted: ADLSgen2 — Databricks connectivity, Azure Databricks — Microsoft Fabric connectivity and Microsoft Fabric — end user connectivity. In the remaining of this section, the connectivity between the resources is discussed focusing on networking and access control.
In this, it is not in scope to discuss how ADLSgen2, Databricks or Microsoft Fabric can be secured as products themselves. The rationale is that all three resources are major Azure products and offer extensive documentation on how to achieve this. This blog really focuses on the integration points.
3.2 ADLSgen2 — Azure Databricks connectivity
Azure Databricks needs to fetch data from ADLSgen2 with Hierarchical Name Space (HNS) enabled. ADLSgen2 is used as storage since it provides the best disaster recovery capabilities. This includes point-in-time recovery integration with Azure Backup coming in 2025, which offers better protection against malware attacks and accidental deletions. You can find the following networking and access control practices applicable.
Networking: Azure storage public access is disabled. To make sure that Databricks can access the storage account, private endpoints are created in the Databricks VNET. This makes sure that the storage account cannot be accessed from outside the company network and that data stays on the Azure backbone.
Identity-based access control: The storage account can only be accessed via identities and access keys are disabled. To allow Databricks Unity Catalog access to the data, the Databricks access connector identity needs to be granted access using an external location. Depending on the data architecture, this can be an RBAC role to the entire container or a fine-grained ACL/POSIX access rule to the data folder.
3.3 Azure Databricks — Microsoft Fabric connectivity:
Microsoft Fabric needs to fetch data from Azure Databricks. This data shall be used by Fabric to serve end users. In this architecture, the SQL API is used. The networking and identity access control points are also most applicable for the shortcut architecture discussed in paragraph 2.2.
Networking: Azure Databricks public access is disabled. This is both true for the front end as the back end such that clusters are deployed without a public IP address. To make sure that Microsoft Fabric can access data exposed via the SQL API from a network perspective, a data gateway needs to be deployed. It could be decided to deploy a virtual machine in the Databricks VNET, however, that is an IaaS component that needs to be maintained which gives security challenges on its own. A better option is to use a managed virtual network data gateway which is Microsoft managed and provides connectivity.
Identity-based access control: Data in Azure Databricks will be exposed via Unity Catalog. Data in the Unity Catalog shall only be exposed via Identities using fine-grained access control tables and using row-level security. It is not yet possible to use Microsoft Fabric Workspace Identities to access the Databricks SQL API. Instead, a service principal shall be granted access to the data in the Unity Catalog and a personal access token based in this service principal shall be used in the Microsoft Databricks Connector.
3.4 Microsoft Fabric — end user connectivity:
In this architecture, end users will connect to Microsoft Fabric to access reports and to do self-service BI. Within Microsoft, different types of reports can be created based on Power BI. You can apply the following networking and identity-based access controls.
Networking: Microsoft Fabric public access is disabled. Currently, this can only be done at tenant level, as more granular workspace private access will become available in 2025. This can assure that a company can differentiate between private and public workspace. To make sure that end users can access Fabric, private endpoints for Fabric are created in the workspace VNET. This workplace can be peered to the corporate on prem networking using VPN or ExpressRoute. The separation of different networks ensures isolation between the different resources.
Identity-based access control: End users should get access to reports on a need-to-know basis. This can be done to create a separate workspace where reports are stored and to which users get. Also, users shall only be allowed to log in Microsoft Fabric with conditional access policies applied. This way, it can be ensured that users can only log in from hardened devices to prevent data exfiltration.
3.5 Final remarks
In the previous paragraph, an architecture is described where everything is made private and multiple VNET and jumphosts are used. To get your hands dirty and to test this architecture faster, you can decide to test with a simplified architecture below.
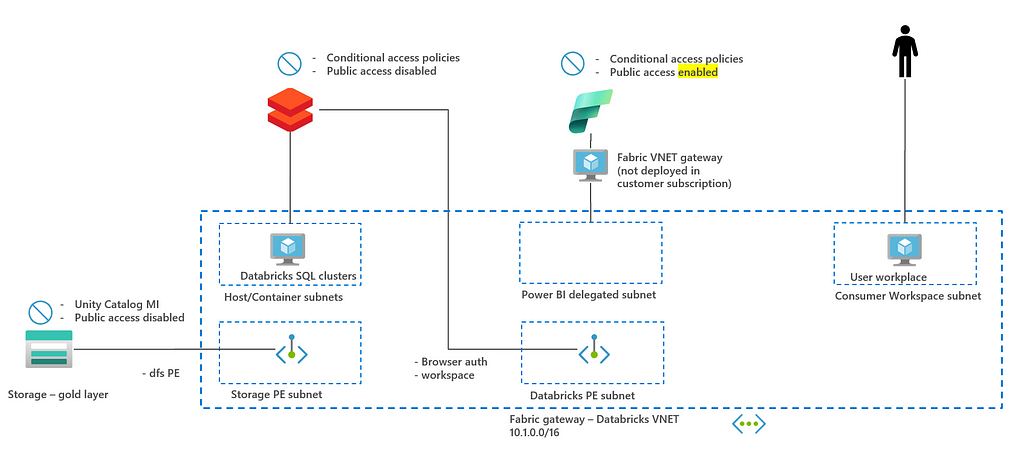
In this architecture, Fabric is configured with public access enabled. Rationale is that Fabric public access setting is currently tenant wide setting. This implies that you need to make all workspaces in a company either private or public. More granular workspace private access will become available in 2025. Also, a single subnet is used to deploy all resources to prevent peering between VNETs and/or deploying multiple jumphosts for connectivity.
4. Conclusion
Microsoft Fabric and Azure Databricks are both powerhouses in the data analytics field. Both tools can cover all parts of the lakehouse architecture, but both tools also have their own strengths. A strategic decision could be to integrate the tools especially if there is a non green situation and both tools are used in a company.
Three different architectures to integrate are discussed: Lakehouse split, virtualization with shortcuts and exposing via SQL API. The first two architectures are more relevant in case you want to put more emphasize on the Fabric analytics capabilities, whereas the last SQL API architecture is more relevant if you want to focus on the Fabric Power BI reporting capabilities.
In the remainder of the blog, a security architecture is provided for the SQL API architecture in which there is a focus on network isolation, private endpoints and identity. Although this architecture focuses on exposing data from the Databricks SQL, the security principles are also applicable for the other architectures.
In short: There are numerous things to take into account if and where to integrate Azure Databricks with Microsoft Fabric. However, this shall always be done with security in mind. This blog aimed to give you an in-depth overview using the SQL API as practical example.
How to Securely Connect Microsoft Fabric to Azure Databricks SQL API was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Integration architecture focusing on security and access controlConnecting Compute — image by Alexandre Debiève on Unsplash1. IntroductionMicrosoft Fabric and Azure Databricks are both powerhouses in the data analytics field. These platforms can be used end-to-end in a medallion architecture, from data ingestion to creating data products for end users. Azure Databricks excels in the initial stages due to its strength in processing large datasets and populating the different zones of the lakehouse. Microsoft Fabric performs well in the latter stages when data is consumed. Coming from Power BI, the SaaS setup is easy to use and it provides self-service capabilities to end users.Given the different strengths of these products and that many customers do not have a greenfield situation, a strategic decision can be to integrate the products. You must then find a logical integration point where both products “meet”. This shall be done with security in mind as this is a top priority for all enterprises.This blog post first explores three different integration options: Lakehouse split, virtualization with shortcuts, and exposing via SQL API. SQL API is a common integration point between back end and front end and the security architecture of this integration is discussed in more detail in chapter 3. See already the architecture diagram below.Securely Connect Microsoft Fabric to Azure Databricks SQL API — image by author2. Azure Databricks — Microsoft Fabric integration overviewBefore diving into the details of securing SQL API architecture, it is helpful to briefly discuss the different options for integrating Azure Databricks and Microsoft Fabric. This chapter outlines three options, highlighting their advantages and disadvantages. For a more extensive overview, refer to this blog.2.1 Lakehouse split: Bronze, silver zone in Databricks | gold zone in FabricIn this architecture, you can find that data is processed by Databricks up to the silver zone. Fabric copies and processes the data to gold zone in Fabric using V-Ordering. Gold zone data is exposed via a Fabric lakehouse such that data products can be created for end users, see image below.2.1 Lakehouse split: Bronze, silver zone in Databricks | gold zone in Fabric — image by authorThe advantage of this architecture is that data is optimized for data consumption in Fabric. The disadvantage is that the lakehouse is split over two tools which adds complexity and can give challenges in data governance (Unity Catalog for bronze/silver, but not for gold).This architecture is most applicable to companies that place a strong emphasis on data analytics in Microsoft Fabric and may even want to eventually migrate the entire lakehouse to Microsoft Fabric.2.2 Virtualization: Lakehouse in Databricks | shortcuts to FabricIn this architecture, all data is in the lakehouse is processed by Databricks. Data is virtualized to Microsoft Fabric Lakehouse using ADLSgen2 shortcuts or even a mirrored Azure Databricks Unity Catalog in Fabric, see also the image below.2.2 Virtualization: Lakehouse in Databricks | shortcuts to Fabric — image by authorThe advantage of this architecture is that lakehouse is owned by a single tool which gives less challenges in integration and governance. The disadvantage is that data is not optimized for Fabric consumption. In this, you may require additional copies in Fabric to apply V-Ordering, and so optimize for Fabric consumption.This architecture is most applicable for companies that want to keep the lakehouse Databricks owned and want to enable end users to do analytics in Fabric in which the lack of V-Ordering is not much of a concern. The latter could be true if the data sizes are not too big and/or end users need a data copy anyway.2.3 Exposing SQL API: Lakehouse in Databricks | SQL API to FabricIn this architecture, all data is in the lakehouse is processed by Databricks again. However, in this architecture the data is exposed to Fabric using the SQL API. In this, you can decide to use a dedicated Databricks SQL Warehouse or serverless SQL. The main difference with shortcut architecture in the previous bullet, is that data is processed in Databricks rather than Fabric. This can be compared to when a web app fires a SQL query to a database; the query is executed in the database.2.3 Exposing SQL API: Lakehouse in Databricks | SQL API to Fabric — image by authorThe advantage of this architecture is that lakehouse is owned by a single tool which gives less challenges in integration and governance. Also, SQL API provides a clean interface between Azure Databricks and Microsoft Fabric with less coupling compared to shortcuts. The disadvantage is that end users in Fabric are limited to the Databricks SQL and Fabric is merely used as reporting tool rather than analytics tool.This architecture is most applicable for companies that want to keep the lakehouse Databricks-owned and are looking to enhance Azure Databricks with the Power BI capabilities that Microsoft Fabric offers.In the next chapter, a security architecture is discussed for this SQL API integration.3. Exposing SQL API: security architectureIn this chapter, security architecture is discussed for this SQL API integration. The rationale is that integrating SQL API is a common touch point where back end and front end meet. Furthermore, most security recommendations are applicable for the other architectures discussed earlier.3.1 Advanced SQL API architectureTo achieve defense in depth, networking isolation and identity-based access control are the two most important steps. You can find this in the diagram below, that was already provided in the introduction of this blog.3.1 Security connect Azure Databricks SQL to MSFT Fabric — image by authorIn this diagram, three key connectivities that need to be secured are highlighted: ADLSgen2 — Databricks connectivity, Azure Databricks — Microsoft Fabric connectivity and Microsoft Fabric — end user connectivity. In the remaining of this section, the connectivity between the resources is discussed focusing on networking and access control.In this, it is not in scope to discuss how ADLSgen2, Databricks or Microsoft Fabric can be secured as products themselves. The rationale is that all three resources are major Azure products and offer extensive documentation on how to achieve this. This blog really focuses on the integration points.3.2 ADLSgen2 — Azure Databricks connectivityAzure Databricks needs to fetch data from ADLSgen2 with Hierarchical Name Space (HNS) enabled. ADLSgen2 is used as storage since it provides the best disaster recovery capabilities. This includes point-in-time recovery integration with Azure Backup coming in 2025, which offers better protection against malware attacks and accidental deletions. You can find the following networking and access control practices applicable.Networking: Azure storage public access is disabled. To make sure that Databricks can access the storage account, private endpoints are created in the Databricks VNET. This makes sure that the storage account cannot be accessed from outside the company network and that data stays on the Azure backbone.Identity-based access control: The storage account can only be accessed via identities and access keys are disabled. To allow Databricks Unity Catalog access to the data, the Databricks access connector identity needs to be granted access using an external location. Depending on the data architecture, this can be an RBAC role to the entire container or a fine-grained ACL/POSIX access rule to the data folder.3.3 Azure Databricks — Microsoft Fabric connectivity:Microsoft Fabric needs to fetch data from Azure Databricks. This data shall be used by Fabric to serve end users. In this architecture, the SQL API is used. The networking and identity access control points are also most applicable for the shortcut architecture discussed in paragraph 2.2.Networking: Azure Databricks public access is disabled. This is both true for the front end as the back end such that clusters are deployed without a public IP address. To make sure that Microsoft Fabric can access data exposed via the SQL API from a network perspective, a data gateway needs to be deployed. It could be decided to deploy a virtual machine in the Databricks VNET, however, that is an IaaS component that needs to be maintained which gives security challenges on its own. A better option is to use a managed virtual network data gateway which is Microsoft managed and provides connectivity.Identity-based access control: Data in Azure Databricks will be exposed via Unity Catalog. Data in the Unity Catalog shall only be exposed via Identities using fine-grained access control tables and using row-level security. It is not yet possible to use Microsoft Fabric Workspace Identities to access the Databricks SQL API. Instead, a service principal shall be granted access to the data in the Unity Catalog and a personal access token based in this service principal shall be used in the Microsoft Databricks Connector.3.4 Microsoft Fabric — end user connectivity:In this architecture, end users will connect to Microsoft Fabric to access reports and to do self-service BI. Within Microsoft, different types of reports can be created based on Power BI. You can apply the following networking and identity-based access controls.Networking: Microsoft Fabric public access is disabled. Currently, this can only be done at tenant level, as more granular workspace private access will become available in 2025. This can assure that a company can differentiate between private and public workspace. To make sure that end users can access Fabric, private endpoints for Fabric are created in the workspace VNET. This workplace can be peered to the corporate on prem networking using VPN or ExpressRoute. The separation of different networks ensures isolation between the different resources.Identity-based access control: End users should get access to reports on a need-to-know basis. This can be done to create a separate workspace where reports are stored and to which users get. Also, users shall only be allowed to log in Microsoft Fabric with conditional access policies applied. This way, it can be ensured that users can only log in from hardened devices to prevent data exfiltration.3.5 Final remarksIn the previous paragraph, an architecture is described where everything is made private and multiple VNET and jumphosts are used. To get your hands dirty and to test this architecture faster, you can decide to test with a simplified architecture below.2.3.1 Security connect Azure Databricks SQL to Microsoft Fabric — image by authorIn this architecture, Fabric is configured with public access enabled. Rationale is that Fabric public access setting is currently tenant wide setting. This implies that you need to make all workspaces in a company either private or public. More granular workspace private access will become available in 2025. Also, a single subnet is used to deploy all resources to prevent peering between VNETs and/or deploying multiple jumphosts for connectivity.4. ConclusionMicrosoft Fabric and Azure Databricks are both powerhouses in the data analytics field. Both tools can cover all parts of the lakehouse architecture, but both tools also have their own strengths. A strategic decision could be to integrate the tools especially if there is a non green situation and both tools are used in a company.Three different architectures to integrate are discussed: Lakehouse split, virtualization with shortcuts and exposing via SQL API. The first two architectures are more relevant in case you want to put more emphasize on the Fabric analytics capabilities, whereas the last SQL API architecture is more relevant if you want to focus on the Fabric Power BI reporting capabilities.In the remainder of the blog, a security architecture is provided for the SQL API architecture in which there is a focus on network isolation, private endpoints and identity. Although this architecture focuses on exposing data from the Databricks SQL, the security principles are also applicable for the other architectures.In short: There are numerous things to take into account if and where to integrate Azure Databricks with Microsoft Fabric. However, this shall always be done with security in mind. This blog aimed to give you an in-depth overview using the SQL API as practical example.How to Securely Connect Microsoft Fabric to Azure Databricks SQL API was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. programming, azure, databricks, microsoft-fabric, data-security Towards Data Science – MediumRead More

 Add to favorites
Add to favorites


0 Comments