Applications and techniques for AI mono-to-stereo upmixing

Mono recordings are a snapshot of history, but they lack the spatial richness that makes music feel truly alive. With AI, we can artificially transform mono recordings to stereo or even remix existing stereo recordings. In this article, we explore the practical use cases and methods for mono-to-stereo upmixing.
Mono and Stereo in the physical and digital world

When an orchestra plays live, sound waves travel from different instruments through the room and to your ears. This causes differences in timing (when the sound reaches your ear) and loudness (how loud the sound appears in each ear). Through this process, a musical performance becomes more than harmony, timbre, and rhythm. Each instrument sends spatial information, immersing the listener in a “here and now” experience that grips their attention and emotions.
Listen to the difference between the first snippet (no spatial information), and the second snippet (clear differences between left and right ear):
Headphones are strongly recommended throughout the article, but are not strictly necessary.
Exampe: Mono
https://medium.com/media/f484d5274ef70332f5920662eff2d556/href
Example: Stereo
https://medium.com/media/cd587700468d0c34ec93986671b77d6f/href
As you can hear, the spatial information conveyed through a recording has a strong influence on the liveliness and excitement we perceive as listeners.
In digital audio, the most common formats are mono and stereo. A mono recording consists of only one audio signal that sounds exactly the same on both sides of your headphone earpieces (let’s call them channels). A stereo recording consists of two separate signals that are panned fully to the left and right channels, respectively.
Now that we have experienced how stereo sound makes the listening experience much more lively and engaging and we also understand the key terminologies, we can delve deeper into what we are here for: The role of AI in mono-to-stereo conversion, also known as mono-to-stereo upmixing.
Use Cases for Mono-to-Stereo Upmixing
AI is not an end in itself. To justify the development and use of such advanced technology, we need practical use cases. The two primary use cases for mono-to-stereo upmixing are
1. Enriching existing music in mono format to a stereo experience.
Although stereo recording technology was invented in the early 1930s, it took until the 1960s for it to become the de-facto standard in recording studios and even longer to establish itself in regular households. In the late 50s, new movie releases still came with a stereo track and an additional mono track to account for theatres that were not ready to transition to stereo systems. In short, there are lots of popular songs that were recorded in mono. Examples include:
- Elvis Presley: Thats All Right
- Chuck Berry: Johnny Be Goode
- Duke Ellington: Take the “A” Train
https://medium.com/media/cb66090595c56d12637ec8d78b01ce30/href
Even today, amateur musicians might publish their recordings in mono, either because of a lack of technical competence, or simply because they didn’t want to make an effort to create a stereo mix.
Mono-to-Stereo conversion lets us experience our favorite old recordings in a new light and also bring amateur recordings or demo tracks to live.
2. Improving or modernizing existing stereo mixes that appear sloppy or simply have fallen out of time, stylistically
Even when a stereo recording is available, we might still want to improve it. For example, many older recordings from the 60s and 70s were recorded in stereo, but with each instrument panned 100% to one side. Listen to “Soul Kitchen” by The Doors and notice how the bass and drums are panned fully to the left, the keys and guitar to the right, and the vocals in the centre. The song is great and there is a special aesthetic to it, but the stereo mix would likely not get much love from a modern audience.
https://medium.com/media/0ca3fa5add9afc69d7e7206962298039/href
Technical limitations have affected stereo sound in the past. Further, stereo mixing is not purely a craft, it is part of the artwork. Stereo mixes can be objectively okay, but still fall out of time, stylistically. A stereo conversion tool could be used to create an alternate stereo version that aligns more closely with certain stylistic preferences.
How Mono-to-Stereo AI Works
Now that we discussed how relevant mono-to-stereo technology is, you might be wondering how it works under the hood. Turns out there are different approaches to tackling this problem with AI. In the following, I want to showcase four different methods, ranging from traditional signal processing to generative AI. It does not serve as a complete list of methods, but rather as an inspiration for how this task has been solved over the last 20 years.
Traditional Signal Processing: Sound Source Formation
Before machine learning became as popular as it is today, the field of Music Information Retrieval (MIR) was dominated by smart, hand-crafted algorithms. It is no wonder that such approaches also exist for mono-to-stereo upmixing.
The fundamental idea behind a paper from 2007 (Lagrange, Martins, Tzanetakis, [1]) is simple:
If we can find the different sound sources of a recording and extract them from the signal, we can mix them back together for a realistic stereo experience.
This sounds simple, but how can we tell what the sound sources in the signal are? How do we define them so clearly that an algorithm can extract them from the signal? These questions are difficult to solve and the paper uses a variety of advanced methods to achieve this. In essence, this is the algorithm they came up with:
- Break the recording into short snippets and identify the peak frequencies (dominant notes) in each snippet
- Identify which peaks belong together (a sound source) using a clustering algorithm
- Decide where each sound source should be placed in the stereo mix (manual step)
- For each sound source, extract its assigned frequencies from the signal
- Mix all extracted sources together to form the final stereo mix.
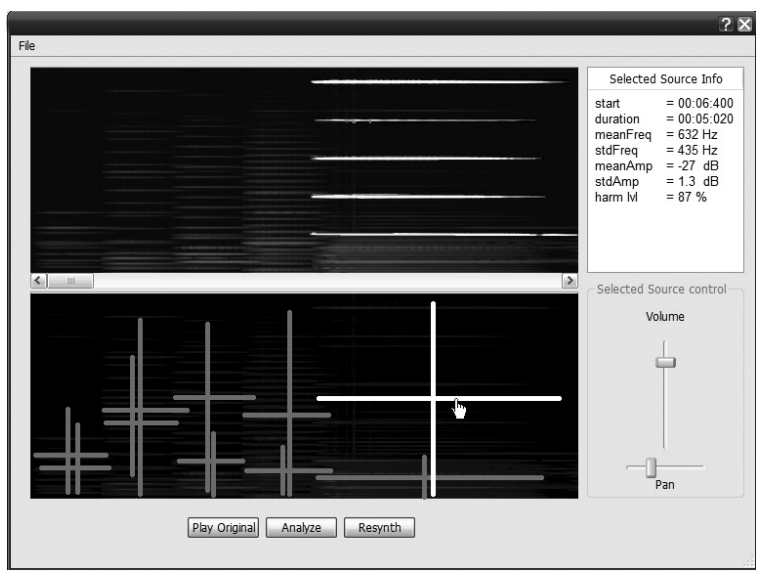
Although quite complex in the details, the intuition is quite clear: Find sources, extract them, mix them back together.
A Quick Workaround: Source Separation / Stem Splitting
A lot has happened since Lagrange’s 2007 paper. Since Deezer released their stem splitting tool Spleeter in 2019, AI-based source separation systems have become remarkably useful. Leading players such as Lalal.ai or Audioshake make a quick workaround possible:
- Separate a mono recording into its individual instrument stems using a free or commercial stem splitter
- Load the stems into a Digital Audio Workstation (DAW) and mix them together to your liking
This technique has been used in a research paper in 2011 (see [2]), but it has become much more viable since due to the recent improvements in stem separation tools.
The downside of source separation approaches is that they produce noticeable sound artifacts, because source separation itself is still not without flaws. Additionally, these approaches still require manual mixing by humans, making them only semi-automatic.
To fully automate mono-to-stereo upmixing, machine learning is required. By learning from real stereo mixes, ML system can adapt the mixing style of real human producers.
Machine Learning with Parametric Stereo

One very creative and efficient way of using machine learning for mono-to-stereo upmixing was presented at ISMIR 2023 by Serrà and colleagues [3]. This work is based on a music compression technique called parametric stereo. Stereo mixes consist of two audio channels, making it hard to integrate in low-bandwidth settings such as music streaming, radio broadcasting, or telephone connections.
Parametric stereo is a technique to create stereo sound from a single mono signal by focusing on the important spatial cues our brain uses to determine where sounds are coming from. These cues are:
- How loud a sound is in the left ear vs. the right ear (Interchannel Intensity Difference, IID)
- How in sync it is between left and right in terms of time or phase (Interchannel Time or Phase Difference)
- How similar or different the signals are in each ear (Interchannel Correlation, IC)
Using these parameters, a stereo-like experience can be created from nothing more than a mono signal.
This is the approach the researchers took to develop their mono-to-stereo upmixing model:
- Collect a large dataset of stereo music tracks
- Convert the stereo tracks to parametric stereo (mono + spatial parameters)
- Train a neural network to predict the spatial parameters given a mono recording
- To turn a new mono signal into stereo, use the trained model to infer spatial parameters from the mono signal and combine the two to a parametric stereo experience
Currently, no code or listening demos seem to be available for this paper. The authors themselves confess that “there is still a gap between professional stereo mixes and the proposed approaches” (p. 6). Still, the paper outlines a creative and efficient way to accomplish fully automated mono-to-stereo upmixing using machine learning.
Generative AI: Transformer-based Synthesis
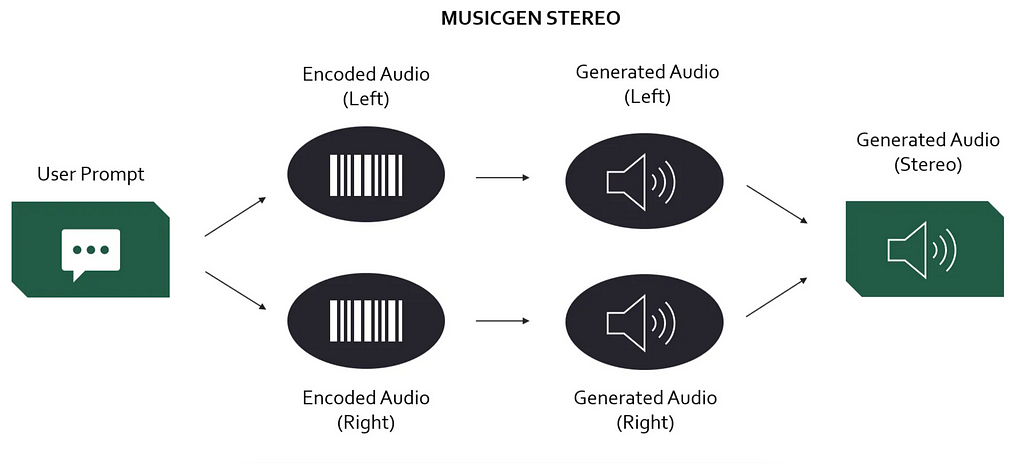
Now, we will get to the seemingly most straight-forward way to generate stereo from mono. Training a generative model to take a mono input and synthesizing both stereo output channels directly. Although conceptually simple, this is by far the most challenging approach from a technical standpoint. One second of high-resolution audio has 44.1k data points. Generating a three-minute song with stereo channels therefore means generating over 15 million data points.
With todays technologies such as convolutional neural networks, transformers, and neural audio codecs, the complexity of the task is starting to become managable. There are some papers who chose to generate stereo signal through direct neural synthesis (see [4], [5], [6]). However, only [5] train a model than can solve mono to stereo generation out of the box. My intuition is that there is room for a paper that builds a dedicated for the “simple” task of mono-to-stereo generation and focuses 100% on solving this objective. Anyone here looking for a PhD topic?
What Needs to Happen Next?

To conclude this article, I want to discuss where the field of mono-to-stereo upmixing might be going. Most importantly, I noticed that research in this domain is very sparse, compared to hype topics such as text-to-music generation. Here’s what I think the research community should focus on to bring mono-to-stereo upmixing research to the next level:
1. Openly Available Demos and Code
Only few papers are released in this research field. This makes it even more frustrating that many of them do not share their code or the results of their work with the community. Several times have I read through a fascinating paper only to find that the only way to test the output quality of the method is to understand every single formula in the paper and implement the algorithm myself from scratch.
Sharing code and creating public demos has never been as easy as it is today. Researchers should make this a priority to enable the wider audio community to understand, evaluate, and appreciate their work.
2. Going All-In on Generative AI
Traditional signal processing and machine learning are fun, but when it comes to output quality, there is no way around generative AI anymore. Text-to-music models are already producing great-sounding stereo mixes. Why is there no easy to use, state-of-the-art mono-to-stereo upmixing library available?
From what I gathered in my research, building an efficient and effective model can be done with a reasonable dataset size and minimal to moderate changes to existing model architectures and training methods. My impression is that this is a low-hanging fruit and a “just do it!” situation.
3. Making Upmixing Automated, but Controllable
Once we have a great open-source upmixing model, the next thing we need is controllability. We shouldn’t have to pick between black-box “take-it-or-leave-it” neural generations or old-school, manual mixing based on source separation. I think we could have it both.
A neural mono-to-stereo upmixing model could be trained on a massive dataset and then finetuned to adjust its stereo mixes based on a user prompt. This way, musicians could customize the style of the generated stereo based on their personal preferences.
Conclusion
Effective and openly-accessible mono-to-stereo upmixing has the potential to breathe live into old recordings or amateur productions, while also allowing us to create alternate stereo mixes of our favorite songs.
Although there have been several attempts to solve this problem, no standard method has been established. By embracing recent development in GenAI, a new generation of mono-to-stereo upmixing models could be created that makes the technology more effective and more widely available in the community.
About Me
I’m a musicologist and a data scientist, sharing my thoughts on current topics in AI & music. Here is some of my previous work related to this article:
- Images that Sound: Creating Stunning Audiovisual ART with AI
- How Meta’s AI Generates Music Based on a Reference Melody
- AI Music Source Separation: How it Works and Why it is so Hard
Find me on Medium and Linkedin!
References
[1] M. Lagrange, L. G. Martins, and G. Tzanetakis (2007): “Semiautomatic mono to stereo up-mixing using sound source formation”, in Audio Engineering Society Convention 122. Audio Engineering Society, 2007.
[2] D. Fitzgerald (2011): “Upmixing from mono-a source separation approach”, in 2011 17th International Conference on Digital Signal Processing (DSP). IEEE, 2011, pp. 1–7.
[3] J. Serrà, D. Scaini, S. Pascual, et al. (2023): “Mono-to-stereo through parametric stereo generation”: https://arxiv.org/abs/2306.14647
[4] J. Copet, F. Kreuk, I. Gat et al. (2023): “Simple and Controllable Music Generation” (revision from 30.01.2024). https://arxiv.org/abs/2306.05284
[5] Y. Zang, Y. Wang & M. Lee (2024): “Ambisonizer: Neural Upmixing as Spherical Harmonics Generation”. https://arxiv.org/pdf/2405.13428
[6] K.K. Parida, S. Srivastava & G. Sharma (2022): “Beyond Mono to Binaural: Generating Binaural Audio from Mono Audio with Depth and Cross Modal Attention”, in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2022, p. 3347–3356. Link
Mono to Stereo: How AI Is Breathing New Life into Music was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Applications and techniques for AI mono-to-stereo upmixingImage generated with DALL-E 3.Mono recordings are a snapshot of history, but they lack the spatial richness that makes music feel truly alive. With AI, we can artificially transform mono recordings to stereo or even remix existing stereo recordings. In this article, we explore the practical use cases and methods for mono-to-stereo upmixing.Mono and Stereo in the physical and digital worldPhoto by J on UnsplashWhen an orchestra plays live, sound waves travel from different instruments through the room and to your ears. This causes differences in timing (when the sound reaches your ear) and loudness (how loud the sound appears in each ear). Through this process, a musical performance becomes more than harmony, timbre, and rhythm. Each instrument sends spatial information, immersing the listener in a “here and now” experience that grips their attention and emotions.Listen to the difference between the first snippet (no spatial information), and the second snippet (clear differences between left and right ear):Headphones are strongly recommended throughout the article, but are not strictly necessary.Exampe: Monohttps://medium.com/media/f484d5274ef70332f5920662eff2d556/hrefExample: Stereohttps://medium.com/media/cd587700468d0c34ec93986671b77d6f/hrefAs you can hear, the spatial information conveyed through a recording has a strong influence on the liveliness and excitement we perceive as listeners.In digital audio, the most common formats are mono and stereo. A mono recording consists of only one audio signal that sounds exactly the same on both sides of your headphone earpieces (let’s call them channels). A stereo recording consists of two separate signals that are panned fully to the left and right channels, respectively.Example of a stereo waveform consisting of two channels. Image by the author.Now that we have experienced how stereo sound makes the listening experience much more lively and engaging and we also understand the key terminologies, we can delve deeper into what we are here for: The role of AI in mono-to-stereo conversion, also known as mono-to-stereo upmixing.Use Cases for Mono-to-Stereo UpmixingAI is not an end in itself. To justify the development and use of such advanced technology, we need practical use cases. The two primary use cases for mono-to-stereo upmixing are1. Enriching existing music in mono format to a stereo experience.Although stereo recording technology was invented in the early 1930s, it took until the 1960s for it to become the de-facto standard in recording studios and even longer to establish itself in regular households. In the late 50s, new movie releases still came with a stereo track and an additional mono track to account for theatres that were not ready to transition to stereo systems. In short, there are lots of popular songs that were recorded in mono. Examples include:Elvis Presley: Thats All RightChuck Berry: Johnny Be GoodeDuke Ellington: Take the “A” Trainhttps://medium.com/media/cb66090595c56d12637ec8d78b01ce30/hrefEven today, amateur musicians might publish their recordings in mono, either because of a lack of technical competence, or simply because they didn’t want to make an effort to create a stereo mix.Mono-to-Stereo conversion lets us experience our favorite old recordings in a new light and also bring amateur recordings or demo tracks to live.2. Improving or modernizing existing stereo mixes that appear sloppy or simply have fallen out of time, stylisticallyEven when a stereo recording is available, we might still want to improve it. For example, many older recordings from the 60s and 70s were recorded in stereo, but with each instrument panned 100% to one side. Listen to “Soul Kitchen” by The Doors and notice how the bass and drums are panned fully to the left, the keys and guitar to the right, and the vocals in the centre. The song is great and there is a special aesthetic to it, but the stereo mix would likely not get much love from a modern audience.https://medium.com/media/0ca3fa5add9afc69d7e7206962298039/hrefTechnical limitations have affected stereo sound in the past. Further, stereo mixing is not purely a craft, it is part of the artwork. Stereo mixes can be objectively okay, but still fall out of time, stylistically. A stereo conversion tool could be used to create an alternate stereo version that aligns more closely with certain stylistic preferences.How Mono-to-Stereo AI WorksNow that we discussed how relevant mono-to-stereo technology is, you might be wondering how it works under the hood. Turns out there are different approaches to tackling this problem with AI. In the following, I want to showcase four different methods, ranging from traditional signal processing to generative AI. It does not serve as a complete list of methods, but rather as an inspiration for how this task has been solved over the last 20 years.Traditional Signal Processing: Sound Source FormationBefore machine learning became as popular as it is today, the field of Music Information Retrieval (MIR) was dominated by smart, hand-crafted algorithms. It is no wonder that such approaches also exist for mono-to-stereo upmixing.The fundamental idea behind a paper from 2007 (Lagrange, Martins, Tzanetakis, [1]) is simple:If we can find the different sound sources of a recording and extract them from the signal, we can mix them back together for a realistic stereo experience.This sounds simple, but how can we tell what the sound sources in the signal are? How do we define them so clearly that an algorithm can extract them from the signal? These questions are difficult to solve and the paper uses a variety of advanced methods to achieve this. In essence, this is the algorithm they came up with:Break the recording into short snippets and identify the peak frequencies (dominant notes) in each snippetIdentify which peaks belong together (a sound source) using a clustering algorithmDecide where each sound source should be placed in the stereo mix (manual step)For each sound source, extract its assigned frequencies from the signalMix all extracted sources together to form the final stereo mix.Example of the user interface built for the study. The user goes through all the extracted sources and manually places them in the stereo mix, before resynthesizing the whole signal. Image taken from [1].Although quite complex in the details, the intuition is quite clear: Find sources, extract them, mix them back together.A Quick Workaround: Source Separation / Stem SplittingA lot has happened since Lagrange’s 2007 paper. Since Deezer released their stem splitting tool Spleeter in 2019, AI-based source separation systems have become remarkably useful. Leading players such as Lalal.ai or Audioshake make a quick workaround possible:Separate a mono recording into its individual instrument stems using a free or commercial stem splitterLoad the stems into a Digital Audio Workstation (DAW) and mix them together to your likingThis technique has been used in a research paper in 2011 (see [2]), but it has become much more viable since due to the recent improvements in stem separation tools.The downside of source separation approaches is that they produce noticeable sound artifacts, because source separation itself is still not without flaws. Additionally, these approaches still require manual mixing by humans, making them only semi-automatic.To fully automate mono-to-stereo upmixing, machine learning is required. By learning from real stereo mixes, ML system can adapt the mixing style of real human producers.Machine Learning with Parametric StereoPhoto by Zarak Khan on UnsplashOne very creative and efficient way of using machine learning for mono-to-stereo upmixing was presented at ISMIR 2023 by Serrà and colleagues [3]. This work is based on a music compression technique called parametric stereo. Stereo mixes consist of two audio channels, making it hard to integrate in low-bandwidth settings such as music streaming, radio broadcasting, or telephone connections.Parametric stereo is a technique to create stereo sound from a single mono signal by focusing on the important spatial cues our brain uses to determine where sounds are coming from. These cues are:How loud a sound is in the left ear vs. the right ear (Interchannel Intensity Difference, IID)How in sync it is between left and right in terms of time or phase (Interchannel Time or Phase Difference)How similar or different the signals are in each ear (Interchannel Correlation, IC)Using these parameters, a stereo-like experience can be created from nothing more than a mono signal.This is the approach the researchers took to develop their mono-to-stereo upmixing model:Collect a large dataset of stereo music tracksConvert the stereo tracks to parametric stereo (mono + spatial parameters)Train a neural network to predict the spatial parameters given a mono recordingTo turn a new mono signal into stereo, use the trained model to infer spatial parameters from the mono signal and combine the two to a parametric stereo experienceCurrently, no code or listening demos seem to be available for this paper. The authors themselves confess that “there is still a gap between professional stereo mixes and the proposed approaches” (p. 6). Still, the paper outlines a creative and efficient way to accomplish fully automated mono-to-stereo upmixing using machine learning.Generative AI: Transformer-based SynthesisStereo-Genration in Meta’s text-to-music model MusicGen. Image taken from another article by the author.Now, we will get to the seemingly most straight-forward way to generate stereo from mono. Training a generative model to take a mono input and synthesizing both stereo output channels directly. Although conceptually simple, this is by far the most challenging approach from a technical standpoint. One second of high-resolution audio has 44.1k data points. Generating a three-minute song with stereo channels therefore means generating over 15 million data points.With todays technologies such as convolutional neural networks, transformers, and neural audio codecs, the complexity of the task is starting to become managable. There are some papers who chose to generate stereo signal through direct neural synthesis (see [4], [5], [6]). However, only [5] train a model than can solve mono to stereo generation out of the box. My intuition is that there is room for a paper that builds a dedicated for the “simple” task of mono-to-stereo generation and focuses 100% on solving this objective. Anyone here looking for a PhD topic?What Needs to Happen Next?Photo by Samuel Spagl on UnsplashTo conclude this article, I want to discuss where the field of mono-to-stereo upmixing might be going. Most importantly, I noticed that research in this domain is very sparse, compared to hype topics such as text-to-music generation. Here’s what I think the research community should focus on to bring mono-to-stereo upmixing research to the next level:1. Openly Available Demos and CodeOnly few papers are released in this research field. This makes it even more frustrating that many of them do not share their code or the results of their work with the community. Several times have I read through a fascinating paper only to find that the only way to test the output quality of the method is to understand every single formula in the paper and implement the algorithm myself from scratch.Sharing code and creating public demos has never been as easy as it is today. Researchers should make this a priority to enable the wider audio community to understand, evaluate, and appreciate their work.2. Going All-In on Generative AITraditional signal processing and machine learning are fun, but when it comes to output quality, there is no way around generative AI anymore. Text-to-music models are already producing great-sounding stereo mixes. Why is there no easy to use, state-of-the-art mono-to-stereo upmixing library available?From what I gathered in my research, building an efficient and effective model can be done with a reasonable dataset size and minimal to moderate changes to existing model architectures and training methods. My impression is that this is a low-hanging fruit and a “just do it!” situation.3. Making Upmixing Automated, but ControllableOnce we have a great open-source upmixing model, the next thing we need is controllability. We shouldn’t have to pick between black-box “take-it-or-leave-it” neural generations or old-school, manual mixing based on source separation. I think we could have it both.A neural mono-to-stereo upmixing model could be trained on a massive dataset and then finetuned to adjust its stereo mixes based on a user prompt. This way, musicians could customize the style of the generated stereo based on their personal preferences.ConclusionEffective and openly-accessible mono-to-stereo upmixing has the potential to breathe live into old recordings or amateur productions, while also allowing us to create alternate stereo mixes of our favorite songs.Although there have been several attempts to solve this problem, no standard method has been established. By embracing recent development in GenAI, a new generation of mono-to-stereo upmixing models could be created that makes the technology more effective and more widely available in the community.About MeI’m a musicologist and a data scientist, sharing my thoughts on current topics in AI & music. Here is some of my previous work related to this article:Images that Sound: Creating Stunning Audiovisual ART with AIHow Meta’s AI Generates Music Based on a Reference MelodyAI Music Source Separation: How it Works and Why it is so HardFind me on Medium and Linkedin!References[1] M. Lagrange, L. G. Martins, and G. Tzanetakis (2007): “Semiautomatic mono to stereo up-mixing using sound source formation”, in Audio Engineering Society Convention 122. Audio Engineering Society, 2007.[2] D. Fitzgerald (2011): “Upmixing from mono-a source separation approach”, in 2011 17th International Conference on Digital Signal Processing (DSP). IEEE, 2011, pp. 1–7.[3] J. Serrà, D. Scaini, S. Pascual, et al. (2023): “Mono-to-stereo through parametric stereo generation”: https://arxiv.org/abs/2306.14647[4] J. Copet, F. Kreuk, I. Gat et al. (2023): “Simple and Controllable Music Generation” (revision from 30.01.2024). https://arxiv.org/abs/2306.05284[5] Y. Zang, Y. Wang & M. Lee (2024): “Ambisonizer: Neural Upmixing as Spherical Harmonics Generation”. https://arxiv.org/pdf/2405.13428[6] K.K. Parida, S. Srivastava & G. Sharma (2022): “Beyond Mono to Binaural: Generating Binaural Audio from Mono Audio with Depth and Cross Modal Attention”, in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2022, p. 3347–3356. LinkMono to Stereo: How AI Is Breathing New Life into Music was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. data-science, music, ai-music-production, editors-pick, artificial-intelligence Towards Data Science – MediumRead More

 Add to favorites
Add to favorites


0 Comments