Increasing growth and data complexities have made data deduplication even more relevant
Data duplication is still a problem for many organisations. Although data processing and storage systems have developed rapidly along with technological advances, the complexity of the data produced is also increasing. Moreover, with the proliferation of Big Data and the utilisation of cloud-based applications, today’s organisations must increasingly deal with fragmented data sources.

Ignoring the phenomenon of the large amount of duplicated data will have a negative impact on the organisation. Such as:
- Disruption of the decision-making process. Unclean data can bias metrics and not reflect the actual conditions. For example: if there is one customer that is actually the same, but is represented as 2 or 3 customers data in CRM, this can be a distortion when projecting revenue.
- Swelling storage costs because every bit of data basically takes up storage space.
- Disruption of customer experience. For example: if the system has to provide notifications or send emails to customers, it is very likely that customers whose data is duplicate will receive more than one notification.
- Making the AI training process less than optimal. When an organisation starts developing an AI solution, one of the requirements is to conduct training with clean data. If there is still a lot of duplicates, the data cannot be said to be clean and when forced to be used in AI training, it will potentially produce biased AI.
Given the crucial impact caused when an organisation does not attempt to reduce or eliminate data duplication, the process of data deduplication becomes increasingly relevant. It is also critical to ensure data quality. The growing sophistication and complexity of the system must be accompanied by the evolution of adequate deduplication techniques.
On this occasion, we will examine the 3 latest deduplication methods, which can be a reference for practitioners when planning the deduplication process.
Global Deduplication
It is the process of eliminating duplicate data across multiple storage locations. It is now common for organisations to store their data across multiple servers, data centers, or the cloud. Global deduplication ensures that only one copy of the data is stored.
This method works by creating a global index, which is a list of all existing data, in the form of a unique code (hash) using an algorithm such as SHA256 that represents each piece of data. When a new file is uploaded to a server (for example Server 1), the system will store a unique code for that file.
On another day when a user uploads a file to Server 2, the system will compare the unique code of the new file with the global index. If the new file is found to have the same unique code/hash as the global index, then instead of continuing to store the same file in two places, the system will replace the duplicate file stored on Server 2 with a reference/pointer that points to a copy of the file that already exists on Server 1.
With this method, storage space can clearly be saved. And if combined with Data Virtualisation technique then when the file is needed the system will take it from the original location, but all users will still feel the data is on their respective servers.
The illustration below shows how Global Deduplication works where each server only stores one copy of the original data and duplicates on other servers are replaced by references to the original file.
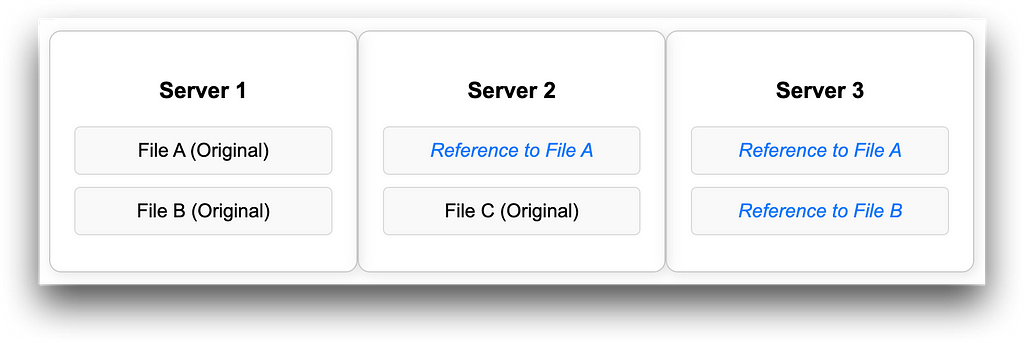
It should be noted that the Global Deduplication method does not work in real-time, but post-process. Which means the method can only be applied when the file has entered storage.
Inline Deduplication
Unlike Global Deduplication, this method works in real-time right when data is being written to the storage system. With the Inline Deduplication technique, duplicate data is immediately replaced with references without going through the physical storage process.
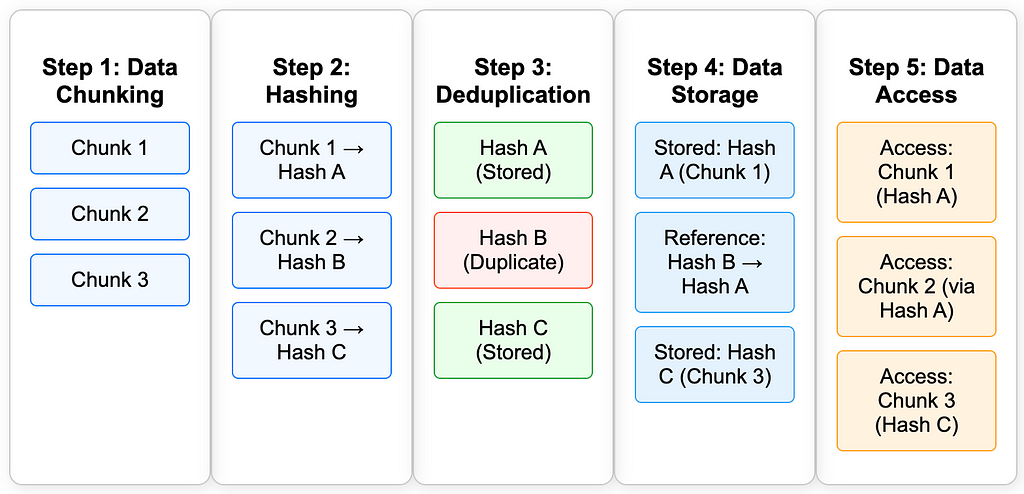
The process begins when data is about to enter the system or a file is being uploaded, the system will immediately divide the file into several small pieces or chunks. Using an algorithm such as SHA-256, each chunk will then be given a hash value as a unique code. Example:
Chunk1 -> hashA
Chunk2-> hashB
Chunk3 -> hashC
The system will then check whether any of the chunks have hashes already in the storage index. If one of the chunks is found whose unique code is already in the storage hash, the system will not re-save the physical data from the chunk, but will only store a reference to the original chunk location that was previously stored.
While each unique chunk will be stored physically.
Later, when a user wants to access the file, the system will rearrange the data from the existing chunks based on the reference, so that the complete file can be used by the user.
Inline Deduplication is widely used by cloud service providers such as Amazon S3 or Google Drive. This method is very useful for optimising storage capacity.
The simple illustration below illustrates the Inline Deduplication process, from data chunking to how data is accessed.
ML-Enhanced Deduplication
Machine learning-powered deduplication uses AI to detect and remove duplicate data, even if it is not completely identical.
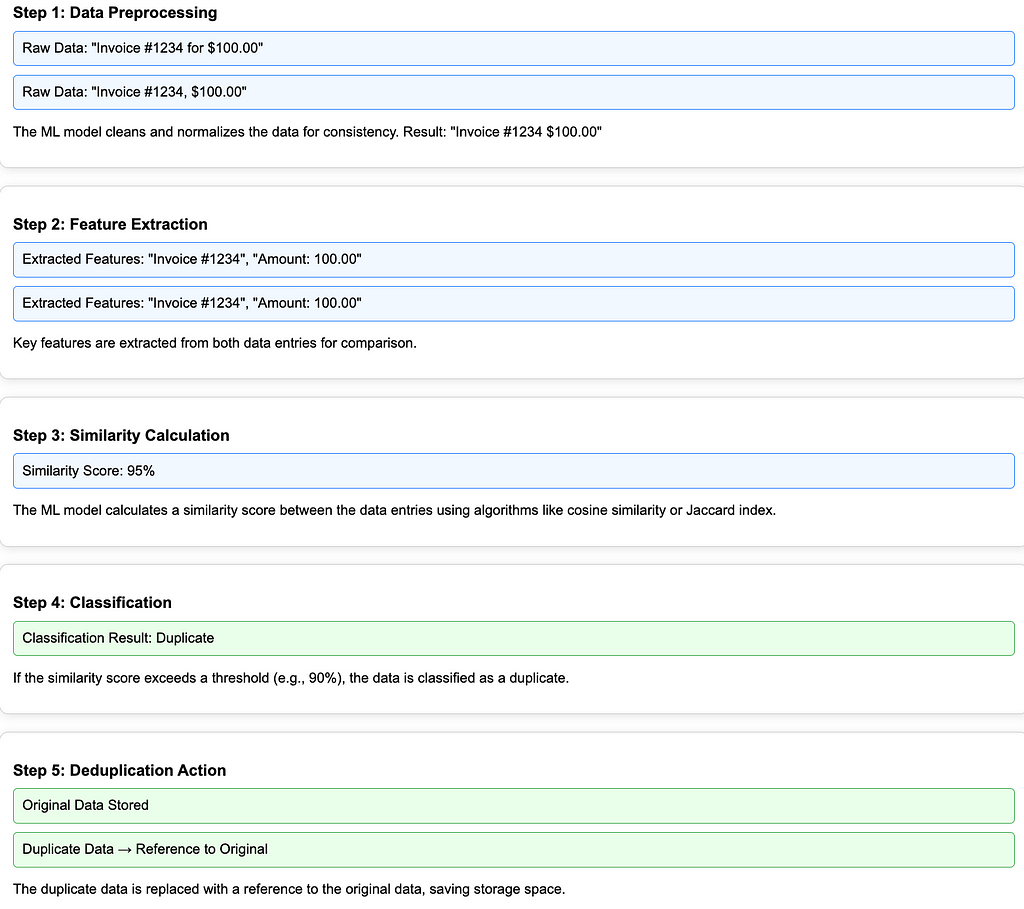
The process begins when incoming data, such as files/documents/records, are sent to the deduplication system for analysis. For example, the system receives two scanned documents that at first glance look similar but actually have subtle differences in layout or text format.
The system will then intelligently extract important features, usually in the form of metadata or visual patterns. These important features will then be analysed and compared for similarity. The similarity of a feature will be represented as a value/score. And each system/organisation can define whether data is a duplicate or not based on its similarity score. For example: only data with a similarity score above 90% can be said to be potentially duplicate.
Based on the similarity score, the system can judge whether the data is a duplicate. If stated that it is a duplicate, then steps can be taken like other duplication methods, where for duplicate data only the reference is stored.
What’s interesting about ML-enhanced Deduplication is that it allows human involvement to validate the classification that has been done by the system. So that the system can continue to get smarter based on the inputs that have been learned (feedback loop).
However, it should be noted that unlike Inline Deduplication, ML-enhanced deduplication is not suitable for use in real-time. This is due to the latency factor, where ML takes time to extract features and process data. In addition, if forced to be real-time, this method requires more intensive computing resources.
Although not real-time, the benefits it brings are still optimal, especially with its ability to handle unstructured or semi-structured data.
The following is an illustration of the steps of ML-enhanced Deduplication along with examples.
From the explanation above, it is clear that organisations have many choices of methods according to their capabilities and needs. So there is no reason to not doing deduplication, especially if the data stored or handled by the organisation is critical data that concerns the lives of many people.
Organisations should be able to use several consideration items to choose the most appropriate method. Aspects such as the purpose of deduplication, the type and volume of data, and the infrastructure capabilities of the organisation can be used for initial assessment.
It should be noted that there is flexible options that organisations can choose, such as a hybrid method of combining Inline Deduplication with the ML-enhanced counterpart. In that way, a wider benefit can be potentially obtained.
Data management regulations such as GDPR and HIPAA regulate sensitive information. Hence, organisations need to ensure that deduplication does not violate privacy policies. For example: an organisation could combine customer data from two different systems after detecting duplicates, without obtaining user consent. Organisations have to ensure this kind of thing is not happening.
Whatever the challenge is, deduplication must still be done, and organisations need to make efforts from the start. Do not wait until the data gets bigger and deduplication efforts become more expensive and complex.
Start now and reap the benefit along the way.
Understanding Deduplication Methods: Ways to Preserve the Integrity of Your Data was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Increasing growth and data complexities have made data deduplication even more relevantData duplication is still a problem for many organisations. Although data processing and storage systems have developed rapidly along with technological advances, the complexity of the data produced is also increasing. Moreover, with the proliferation of Big Data and the utilisation of cloud-based applications, today’s organisations must increasingly deal with fragmented data sources.Photo by Damir: https://www.pexels.com/photo/serene-lakeside-reflection-with-birch-trees-29167854/Ignoring the phenomenon of the large amount of duplicated data will have a negative impact on the organisation. Such as:Disruption of the decision-making process. Unclean data can bias metrics and not reflect the actual conditions. For example: if there is one customer that is actually the same, but is represented as 2 or 3 customers data in CRM, this can be a distortion when projecting revenue.Swelling storage costs because every bit of data basically takes up storage space.Disruption of customer experience. For example: if the system has to provide notifications or send emails to customers, it is very likely that customers whose data is duplicate will receive more than one notification.Making the AI training process less than optimal. When an organisation starts developing an AI solution, one of the requirements is to conduct training with clean data. If there is still a lot of duplicates, the data cannot be said to be clean and when forced to be used in AI training, it will potentially produce biased AI.Given the crucial impact caused when an organisation does not attempt to reduce or eliminate data duplication, the process of data deduplication becomes increasingly relevant. It is also critical to ensure data quality. The growing sophistication and complexity of the system must be accompanied by the evolution of adequate deduplication techniques.On this occasion, we will examine the 3 latest deduplication methods, which can be a reference for practitioners when planning the deduplication process.Global DeduplicationIt is the process of eliminating duplicate data across multiple storage locations. It is now common for organisations to store their data across multiple servers, data centers, or the cloud. Global deduplication ensures that only one copy of the data is stored.This method works by creating a global index, which is a list of all existing data, in the form of a unique code (hash) using an algorithm such as SHA256 that represents each piece of data. When a new file is uploaded to a server (for example Server 1), the system will store a unique code for that file.On another day when a user uploads a file to Server 2, the system will compare the unique code of the new file with the global index. If the new file is found to have the same unique code/hash as the global index, then instead of continuing to store the same file in two places, the system will replace the duplicate file stored on Server 2 with a reference/pointer that points to a copy of the file that already exists on Server 1.With this method, storage space can clearly be saved. And if combined with Data Virtualisation technique then when the file is needed the system will take it from the original location, but all users will still feel the data is on their respective servers.The illustration below shows how Global Deduplication works where each server only stores one copy of the original data and duplicates on other servers are replaced by references to the original file.source: AuthorIt should be noted that the Global Deduplication method does not work in real-time, but post-process. Which means the method can only be applied when the file has entered storage.Inline DeduplicationUnlike Global Deduplication, this method works in real-time right when data is being written to the storage system. With the Inline Deduplication technique, duplicate data is immediately replaced with references without going through the physical storage process.The process begins when data is about to enter the system or a file is being uploaded, the system will immediately divide the file into several small pieces or chunks. Using an algorithm such as SHA-256, each chunk will then be given a hash value as a unique code. Example:Chunk1 -> hashAChunk2-> hashBChunk3 -> hashCThe system will then check whether any of the chunks have hashes already in the storage index. If one of the chunks is found whose unique code is already in the storage hash, the system will not re-save the physical data from the chunk, but will only store a reference to the original chunk location that was previously stored.While each unique chunk will be stored physically.Later, when a user wants to access the file, the system will rearrange the data from the existing chunks based on the reference, so that the complete file can be used by the user.Inline Deduplication is widely used by cloud service providers such as Amazon S3 or Google Drive. This method is very useful for optimising storage capacity.The simple illustration below illustrates the Inline Deduplication process, from data chunking to how data is accessed.Source: AuthorML-Enhanced DeduplicationMachine learning-powered deduplication uses AI to detect and remove duplicate data, even if it is not completely identical.The process begins when incoming data, such as files/documents/records, are sent to the deduplication system for analysis. For example, the system receives two scanned documents that at first glance look similar but actually have subtle differences in layout or text format.The system will then intelligently extract important features, usually in the form of metadata or visual patterns. These important features will then be analysed and compared for similarity. The similarity of a feature will be represented as a value/score. And each system/organisation can define whether data is a duplicate or not based on its similarity score. For example: only data with a similarity score above 90% can be said to be potentially duplicate.Based on the similarity score, the system can judge whether the data is a duplicate. If stated that it is a duplicate, then steps can be taken like other duplication methods, where for duplicate data only the reference is stored.What’s interesting about ML-enhanced Deduplication is that it allows human involvement to validate the classification that has been done by the system. So that the system can continue to get smarter based on the inputs that have been learned (feedback loop).However, it should be noted that unlike Inline Deduplication, ML-enhanced deduplication is not suitable for use in real-time. This is due to the latency factor, where ML takes time to extract features and process data. In addition, if forced to be real-time, this method requires more intensive computing resources.Although not real-time, the benefits it brings are still optimal, especially with its ability to handle unstructured or semi-structured data.The following is an illustration of the steps of ML-enhanced Deduplication along with examples.Source: AuthorFrom the explanation above, it is clear that organisations have many choices of methods according to their capabilities and needs. So there is no reason to not doing deduplication, especially if the data stored or handled by the organisation is critical data that concerns the lives of many people.Organisations should be able to use several consideration items to choose the most appropriate method. Aspects such as the purpose of deduplication, the type and volume of data, and the infrastructure capabilities of the organisation can be used for initial assessment.It should be noted that there is flexible options that organisations can choose, such as a hybrid method of combining Inline Deduplication with the ML-enhanced counterpart. In that way, a wider benefit can be potentially obtained.Data management regulations such as GDPR and HIPAA regulate sensitive information. Hence, organisations need to ensure that deduplication does not violate privacy policies. For example: an organisation could combine customer data from two different systems after detecting duplicates, without obtaining user consent. Organisations have to ensure this kind of thing is not happening.Whatever the challenge is, deduplication must still be done, and organisations need to make efforts from the start. Do not wait until the data gets bigger and deduplication efforts become more expensive and complex.Start now and reap the benefit along the way.Understanding Deduplication Methods: Ways to Preserve the Integrity of Your Data was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. data-management, machine-learning, data-science, data-governance, data-infrastructure Towards Data Science – MediumRead More

 Add to favorites
Add to favorites

0 Comments