Deprioritizing quality sacrifices both software stability and velocity, leading to costly issues. Investing in quality boosts speed and outcomes.

Investing in software quality is often easier said than done. Although many engineering managers express a commitment to high-quality software, they are often cautious about allocating substantial resources toward quality-focused initiatives. Pressed by tight deadlines and competing priorities, leaders frequently face tough choices in how they allocate their team’s time and effort. As a result, investments in quality are often the first to be cut.
The tension between investing in quality and prioritizing velocity is pivotal in any engineering organization and especially with more cutting-edge data science and machine learning projects where delivering results is at the forefront. Unlike traditional software development, ML systems often require continuous updates to maintain model performance, adapt to changing data distributions, and integrate new features. Production issues in ML pipelines — such as data quality problems, model drift, or deployment failures — can disrupt these workflows and have cascading effects on business outcomes. Balancing the speed of experimentation and deployment with rigorous quality assurance is crucial for ML teams to deliver reliable, high-performing models. By applying a structured, scientific approach to quantify the cost of production issues, as outlined in this blog post, ML teams can make informed decisions about where to invest in quality improvements and optimize their development velocity.
Quality often faces a formidable rival: velocity. As pressure to meet business goals and deliver critical features intensifies, it becomes challenging to justify any approach that doesn’t directly
drive output. Many teams reduce non-coding activities to the bare minimum, focusing on unit tests while deprioritizing integration tests, delaying technical improvements, and relying on observability tools to catch production issues — hoping to address them only if they arise.
Balancing velocity and quality is rarely a straightforward choice, and this post doesn’t aim to simplify it. However, what leaders often overlook is that velocity and quality are deeply connected. By deprioritizing initiatives that improve software quality, teams may end up with releases that are both bug-ridden and slow. Any gains from pushing more features out quickly
can quickly erode, as maintenance problems and a steady influx of issues ultimately undermine the team’s velocity.
Only by understanding the full impact of quality on velocity and the expected ROI of quality initiatives can leaders make informed decisions about balancing their team’s backlog.
In this post, we will attempt to provide a model to measure the ROI of investment in two aspects of improving release quality: reducing the number of production issues, and reducing the time spent by the teams on these issues when they occur.
Escape defects, the bugs that make their way to production
Preventing regressions is probably the most direct, top-of-the-funnel measure to reduce the overhead of production issues on the team. Issues that never occurred will not weigh the team down, cause interruptions, or threaten business continuity.
As appealing as the benefits might be, there is an inflection point after which defending the code from issues can slow releases to a grinding halt. Theoretically, the team could triple the number of required code reviews, triple investment in tests, and build a rigorous load testing apparatus. It will find itself preventing more issues but also extremely slow to release any new content.
Therefore, in order to justify investing in any type of effort to prevent regressions, we need to understand the ROI better. We can try to approximate the cost saving of each 1% decrease in regressions on the overall team performance to start establishing a framework we can use to balance quality investment.
The direct gain of preventing issues is first of all with the time the team spends handling these issues. Studies show teams currently spend anywhere between 20–40% of their time working on production issues — a substantial drain on productivity.
What would be the benefit of investing in preventing issues? Using simple math we can start estimating the improvement in productivity for each issue that can be prevented in earlier stages of the development process:
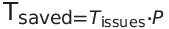
Where:
- Tsaved is the time saved through issue prevention.
- Tissues is the current time spent on production issues.
- P is the percentage of production issues that could be prevented.
This framework aids in assessing the cost vs. value of engineering investments. For example, a manager assigns two developers a week to analyze performance issues using observability data. Their efforts reduce production issues by 10%.
In a 100-developer team where 40% of time is spent on issue resolution, this translates to a 4% capacity gain, plus an additional 1.6% from reduced context switching. With 5.6% capacity reclaimed, the investment in two developers proves worthwhile, showing how this approach can guide practical decision-making.
It’s straightforward to see the direct impact of preventing every single 1% of production regressions on the team’s velocity. This represents work on production regressions that the team would not need to perform. The below table can give some context by plugging in a few values:
https://medium.com/media/0915bdd00c06d0cb29acc44656fd5d1e/href
Given this data, as an example, the direct gain in team resources for each 1% improvement for a team that spends 25% of its time dealing with production issues would be 0.25%. If the team were able to prevent 20% of production issues, it would then mean 5% back to the engineering team. While this might not sound like a sizeable enough chunk, there are other costs related to issues we can try to optimize as well for an even bigger impact.
Mean Time to Resolution (MTTR): Reducing Time Lost to Issue Resolution
In the previous example, we looked at the productivity gain achieved by preventing issues. But what about those issues that can’t be avoided? While some bugs are inevitable, we can still minimize their impact on the team’s productivity by reducing the time it takes to resolve them — known as the Mean Time to Resolution (MTTR).
Typically, resolving a bug involves several stages:
- Triage/Assessment: The team gathers relevant subject matter experts to determine the severity and urgency of the issue.
- Investigation/Root Cause Analysis (RCA): Developers dig into the problem to identify the underlying cause, often the most time-consuming phase.
- Repair/Resolution: The team implements the fix.

Among these stages, the investigation phase often represents the greatest opportunity for time savings. By adopting more efficient tools for tracing, debugging, and defect analysis, teams can streamline their RCA efforts, significantly reducing MTTR and, in turn, boosting productivity.
During triage, the team may involve subject matter experts to assess if an issue belongs in the backlog and determine its urgency. Investigation and root cause analysis (RCA) follows, where developers dig into the problem. Finally, the repair phase involves writing code to fix the issue.
Interestingly, the first two phases, especially investigation and RCA, often consume 30–50% of the total resolution time. This stage holds the greatest potential for optimization, as the key is improving how existing information is analyzed.
To measure the effect of improving the investigation time on the team velocity we can take the the percentage of time the team spends on an issue and reduce the proportional cost of the investigation stage. This can usually be accomplished by adopting better tooling for tracing, debugging, and defect analysis. We apply similar logic to the issue prevention assessment in order to get an idea of how much productivity the team could gain with each percentage of reduction in investigation time.

- Tsaved : Percentage of team time saved
- R: Reduction in investigation time
- T_investigation : Time per issue spent on investigation efforts
- T_issues : Percentage of time spent on production issues
We can test out what would be the performance gain relative to the T_investigationand T_issuesvariables. We will calculate the marginal gain for each percent of investigation time reduction R .
https://medium.com/media/b67ce8d9e57d82524141387c14930c5a/href
As these numbers begin to add up the team can achieve a significant gain. If we are able to improve investigation time by 40%, for example, in a team that spends 25% of its time dealing with production issues, we would be reclaiming another 4% of that team’s productivity.
Combining the two benefits
With these two areas of optimization under consideration, we can create a unified formula to measure the combined effect of optimizing both issue prevention and the time the team spends on issues it is not able to prevent.
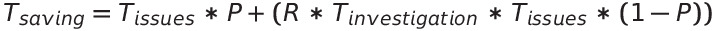
Going back to our example organization that spends 25% of the time on prod issues and 40% of the resolution time per issue on investigation, a reduction of 40% in investigation time and prevention of 20% of the issues would result in an 8.1% improvement to the team productivity. However, we are far from done.
Accounting for the hidden cost of context-switching
Each of the above naive calculations does not take into account a major penalty incurred by work being interrupted due to unplanned production issues — context switching (CS). There are numerous studies that repeatedly show that context switching is expensive. How expensive? A penalty of anywhere between 20% to 70% extra work because of interruptions and switching between several tasks. In reducing interrupted work time we can also reduce the context switching penalty.
Our original formula did not account for that important variable. A simple though naive way of doing that would be to assume that any unplanned work handling production issues incur an equivalent context-switching penalty on the backlog items already assigned to the team. If we are able to save 8% of the team velocity, that should result in an equivalent reduction of context switching working on the original planned tasks. In reducing 8% of unplanned work we have also therefore reduced the CS penalty of the equivalent 8% of planned work the team needs to complete as well.
Let’s add that to our equation:

Continuing our example, our hypothetical organization would find that the actual impact of their improvements is now a little over 11%. For a dev team of 80 engineers, that would be more than 8 developers free to do something else to contribute to the backlog.
Use the ROI calculator
To make things easier, I’ve uploaded all of the above formulas as a simple HTML calculator that you can access here:
Measuring ROI is key
Production issues are costly, but a clear ROI framework helps quantify the impact of quality improvements. Reducing Mean Time to Resolution (MTTR) through optimized triage and investigation can boost team productivity. For example, a 40% reduction in investigation time
recovers 4% of capacity and lowers the hidden cost of context-switching.
Use the ROI Calculator to evaluate quality investments and make data-driven decisions. Access it here to see how targeted improvements enhance efficiency.
References:
1. How Much Time Do Developers Spend Actually Writing Code?
2. How to write good software faster (we spend 90% of our time debugging)
3. Survey: Fixing Bugs Stealing Time from Development
4. The Real Costs of Context-Switching
Measuring the Cost of Production Issues on Development Teams was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Deprioritizing quality sacrifices both software stability and velocity, leading to costly issues. Investing in quality boosts speed and outcomes.Image by the author. (AI generated Midjourney)Investing in software quality is often easier said than done. Although many engineering managers express a commitment to high-quality software, they are often cautious about allocating substantial resources toward quality-focused initiatives. Pressed by tight deadlines and competing priorities, leaders frequently face tough choices in how they allocate their team’s time and effort. As a result, investments in quality are often the first to be cut.The tension between investing in quality and prioritizing velocity is pivotal in any engineering organization and especially with more cutting-edge data science and machine learning projects where delivering results is at the forefront. Unlike traditional software development, ML systems often require continuous updates to maintain model performance, adapt to changing data distributions, and integrate new features. Production issues in ML pipelines — such as data quality problems, model drift, or deployment failures — can disrupt these workflows and have cascading effects on business outcomes. Balancing the speed of experimentation and deployment with rigorous quality assurance is crucial for ML teams to deliver reliable, high-performing models. By applying a structured, scientific approach to quantify the cost of production issues, as outlined in this blog post, ML teams can make informed decisions about where to invest in quality improvements and optimize their development velocity.Quality often faces a formidable rival: velocity. As pressure to meet business goals and deliver critical features intensifies, it becomes challenging to justify any approach that doesn’t directlydrive output. Many teams reduce non-coding activities to the bare minimum, focusing on unit tests while deprioritizing integration tests, delaying technical improvements, and relying on observability tools to catch production issues — hoping to address them only if they arise.Balancing velocity and quality is rarely a straightforward choice, and this post doesn’t aim to simplify it. However, what leaders often overlook is that velocity and quality are deeply connected. By deprioritizing initiatives that improve software quality, teams may end up with releases that are both bug-ridden and slow. Any gains from pushing more features out quicklycan quickly erode, as maintenance problems and a steady influx of issues ultimately undermine the team’s velocity.Only by understanding the full impact of quality on velocity and the expected ROI of quality initiatives can leaders make informed decisions about balancing their team’s backlog.In this post, we will attempt to provide a model to measure the ROI of investment in two aspects of improving release quality: reducing the number of production issues, and reducing the time spent by the teams on these issues when they occur.Escape defects, the bugs that make their way to productionPreventing regressions is probably the most direct, top-of-the-funnel measure to reduce the overhead of production issues on the team. Issues that never occurred will not weigh the team down, cause interruptions, or threaten business continuity.As appealing as the benefits might be, there is an inflection point after which defending the code from issues can slow releases to a grinding halt. Theoretically, the team could triple the number of required code reviews, triple investment in tests, and build a rigorous load testing apparatus. It will find itself preventing more issues but also extremely slow to release any new content.Therefore, in order to justify investing in any type of effort to prevent regressions, we need to understand the ROI better. We can try to approximate the cost saving of each 1% decrease in regressions on the overall team performance to start establishing a framework we can use to balance quality investment.Image by the author.The direct gain of preventing issues is first of all with the time the team spends handling these issues. Studies show teams currently spend anywhere between 20–40% of their time working on production issues — a substantial drain on productivity.What would be the benefit of investing in preventing issues? Using simple math we can start estimating the improvement in productivity for each issue that can be prevented in earlier stages of the development process:Image by the author.Where:Tsaved is the time saved through issue prevention.Tissues is the current time spent on production issues.P is the percentage of production issues that could be prevented.This framework aids in assessing the cost vs. value of engineering investments. For example, a manager assigns two developers a week to analyze performance issues using observability data. Their efforts reduce production issues by 10%.In a 100-developer team where 40% of time is spent on issue resolution, this translates to a 4% capacity gain, plus an additional 1.6% from reduced context switching. With 5.6% capacity reclaimed, the investment in two developers proves worthwhile, showing how this approach can guide practical decision-making.It’s straightforward to see the direct impact of preventing every single 1% of production regressions on the team’s velocity. This represents work on production regressions that the team would not need to perform. The below table can give some context by plugging in a few values:https://medium.com/media/0915bdd00c06d0cb29acc44656fd5d1e/hrefGiven this data, as an example, the direct gain in team resources for each 1% improvement for a team that spends 25% of its time dealing with production issues would be 0.25%. If the team were able to prevent 20% of production issues, it would then mean 5% back to the engineering team. While this might not sound like a sizeable enough chunk, there are other costs related to issues we can try to optimize as well for an even bigger impact.Mean Time to Resolution (MTTR): Reducing Time Lost to Issue ResolutionIn the previous example, we looked at the productivity gain achieved by preventing issues. But what about those issues that can’t be avoided? While some bugs are inevitable, we can still minimize their impact on the team’s productivity by reducing the time it takes to resolve them — known as the Mean Time to Resolution (MTTR).Typically, resolving a bug involves several stages:Triage/Assessment: The team gathers relevant subject matter experts to determine the severity and urgency of the issue.Investigation/Root Cause Analysis (RCA): Developers dig into the problem to identify the underlying cause, often the most time-consuming phase.Repair/Resolution: The team implements the fix.Image by the author.Among these stages, the investigation phase often represents the greatest opportunity for time savings. By adopting more efficient tools for tracing, debugging, and defect analysis, teams can streamline their RCA efforts, significantly reducing MTTR and, in turn, boosting productivity.During triage, the team may involve subject matter experts to assess if an issue belongs in the backlog and determine its urgency. Investigation and root cause analysis (RCA) follows, where developers dig into the problem. Finally, the repair phase involves writing code to fix the issue.Interestingly, the first two phases, especially investigation and RCA, often consume 30–50% of the total resolution time. This stage holds the greatest potential for optimization, as the key is improving how existing information is analyzed.To measure the effect of improving the investigation time on the team velocity we can take the the percentage of time the team spends on an issue and reduce the proportional cost of the investigation stage. This can usually be accomplished by adopting better tooling for tracing, debugging, and defect analysis. We apply similar logic to the issue prevention assessment in order to get an idea of how much productivity the team could gain with each percentage of reduction in investigation time.Image by the author.Tsaved : Percentage of team time savedR: Reduction in investigation timeT_investigation : Time per issue spent on investigation effortsT_issues : Percentage of time spent on production issuesWe can test out what would be the performance gain relative to the T_investigationand T_issuesvariables. We will calculate the marginal gain for each percent of investigation time reduction R .https://medium.com/media/b67ce8d9e57d82524141387c14930c5a/hrefAs these numbers begin to add up the team can achieve a significant gain. If we are able to improve investigation time by 40%, for example, in a team that spends 25% of its time dealing with production issues, we would be reclaiming another 4% of that team’s productivity.Combining the two benefitsWith these two areas of optimization under consideration, we can create a unified formula to measure the combined effect of optimizing both issue prevention and the time the team spends on issues it is not able to prevent.Image by the author.Going back to our example organization that spends 25% of the time on prod issues and 40% of the resolution time per issue on investigation, a reduction of 40% in investigation time and prevention of 20% of the issues would result in an 8.1% improvement to the team productivity. However, we are far from done.Accounting for the hidden cost of context-switchingEach of the above naive calculations does not take into account a major penalty incurred by work being interrupted due to unplanned production issues — context switching (CS). There are numerous studies that repeatedly show that context switching is expensive. How expensive? A penalty of anywhere between 20% to 70% extra work because of interruptions and switching between several tasks. In reducing interrupted work time we can also reduce the context switching penalty.Our original formula did not account for that important variable. A simple though naive way of doing that would be to assume that any unplanned work handling production issues incur an equivalent context-switching penalty on the backlog items already assigned to the team. If we are able to save 8% of the team velocity, that should result in an equivalent reduction of context switching working on the original planned tasks. In reducing 8% of unplanned work we have also therefore reduced the CS penalty of the equivalent 8% of planned work the team needs to complete as well.Let’s add that to our equation:Image by the author.Continuing our example, our hypothetical organization would find that the actual impact of their improvements is now a little over 11%. For a dev team of 80 engineers, that would be more than 8 developers free to do something else to contribute to the backlog.Use the ROI calculatorTo make things easier, I’ve uploaded all of the above formulas as a simple HTML calculator that you can access here:ROI CalculatorMeasuring ROI is keyProduction issues are costly, but a clear ROI framework helps quantify the impact of quality improvements. Reducing Mean Time to Resolution (MTTR) through optimized triage and investigation can boost team productivity. For example, a 40% reduction in investigation timerecovers 4% of capacity and lowers the hidden cost of context-switching.Use the ROI Calculator to evaluate quality investments and make data-driven decisions. Access it here to see how targeted improvements enhance efficiency.References:1. How Much Time Do Developers Spend Actually Writing Code?2. How to write good software faster (we spend 90% of our time debugging)3. Survey: Fixing Bugs Stealing Time from Development4. The Real Costs of Context-SwitchingMeasuring the Cost of Production Issues on Development Teams was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. best-practices, machine-learning, programming, quality-assurance, software-engineering Towards Data Science – MediumRead More

 Add to favorites
Add to favorites


0 Comments