Testing new Snowflake functionality with a 30k records dataset

Working with data, I keep running into the same problem more and more often. On one hand, we have growing requirements for data privacy and confidentiality; on the other — the need to make quick, data-driven decisions. Add to this the modern business reality: freelancers, consultants, short-term projects.
As a decision maker, I face a dilemma: I need analysis right now, the internal team is overloaded, and I can’t just hand over confidential data to every external analyst.
And this is where synthetic data comes in.
But wait — I don’t want to write another theoretical article about what synthetic data is. There are enough of those online already. Instead, I’ll show you a specific comparison: 30 thousand real Shopify transactions versus their synthetic counterpart.
What exactly did I check?
- How faithfully does synthetic data reflect real trends?
- Where are the biggest discrepancies?
- When can we trust synthetic data, and when should we be cautious?
This won’t be another “how to generate synthetic data” guide (though I’ll show the code too). I’m focusing on what really matters — whether this data is actually useful and what its limitations are.
I’m a practitioner — less theory, more specifics. Let’s begin.
Data Overview
When testing synthetic data, you need a solid reference point. In our case, we’re working with real transaction data from a growing e-commerce business:
- 30,000 transactions spanning 6 years
- Clear growth trend year over year
- Mix of high and low-volume sales months
- Diverse geographical spread, with one dominant market
For practical testing, I focused on transaction-level data such as order values, dates, and basic geographic information. Most assessments require only essential business information, without personal or product specifics.
The procedure was simple: export raw Shopify data, analyze it to maintain only the most important information, produce synthetic data in Snowflake, then compare the two datasets side by side. One can think of it as generating a “digital twin” of your business data, with comparable trends but entirely anonymized.
[Technical note: If you’re interested in the detailed data preparation process, including R code and Snowflake setup, check the appendix at the end of this article.]
Monthly Revenue Analysis
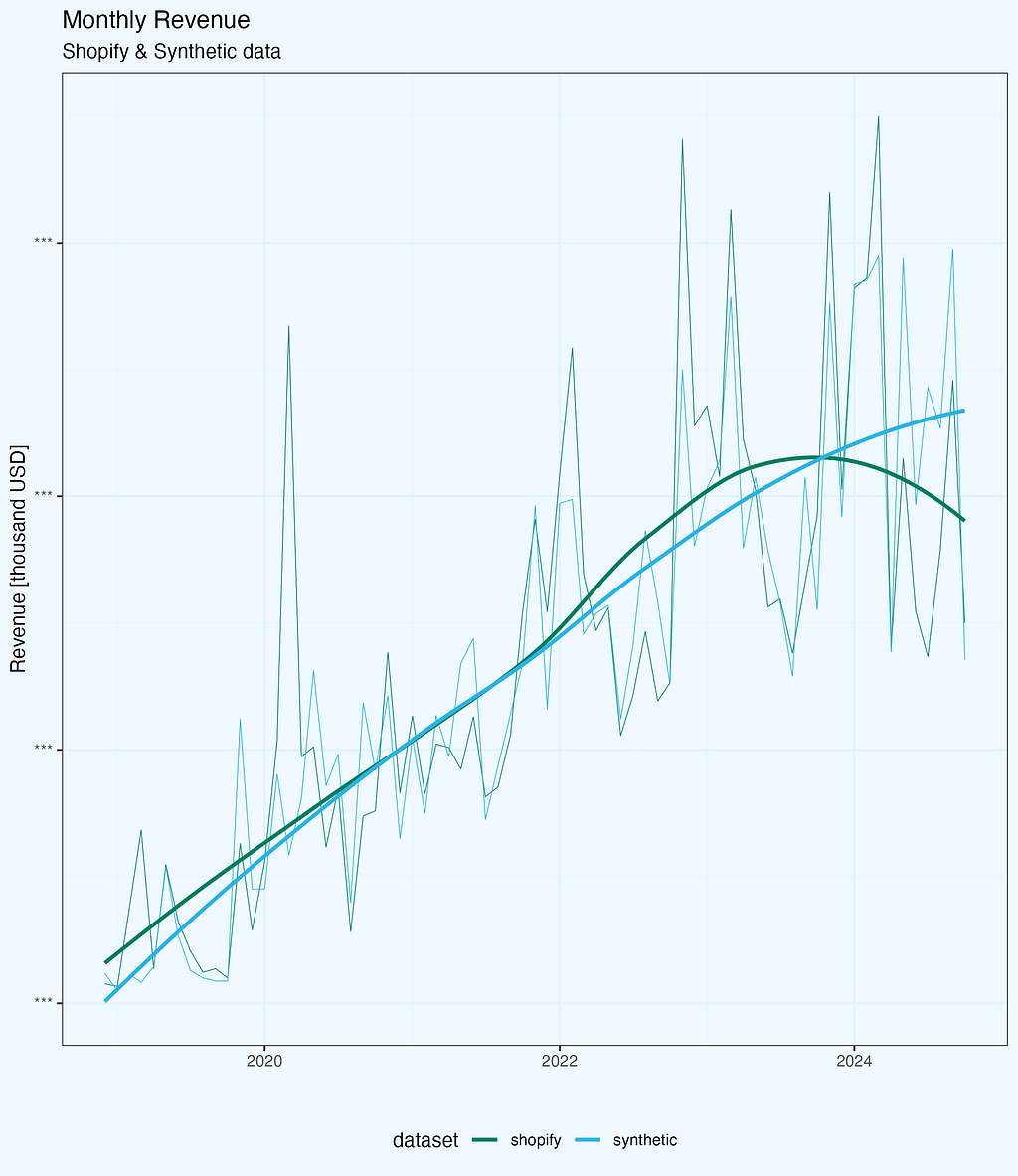
The first test for any synthetic dataset is how well it captures core business metrics. Let’s start with monthly revenue — arguably the most important metric for any business (for sure in top 3).
Looking at the raw trends (Figure 1), both datasets follow a similar pattern: steady growth over the years with seasonal fluctuations. The synthetic data captures the general trend well, including the business’s growth trajectory. However, when we dig deeper into the differences, some interesting patterns emerge.
To quantify these differences, I calculated a monthly delta:
Δ % = (Synthetic - Shopify) / Shopify
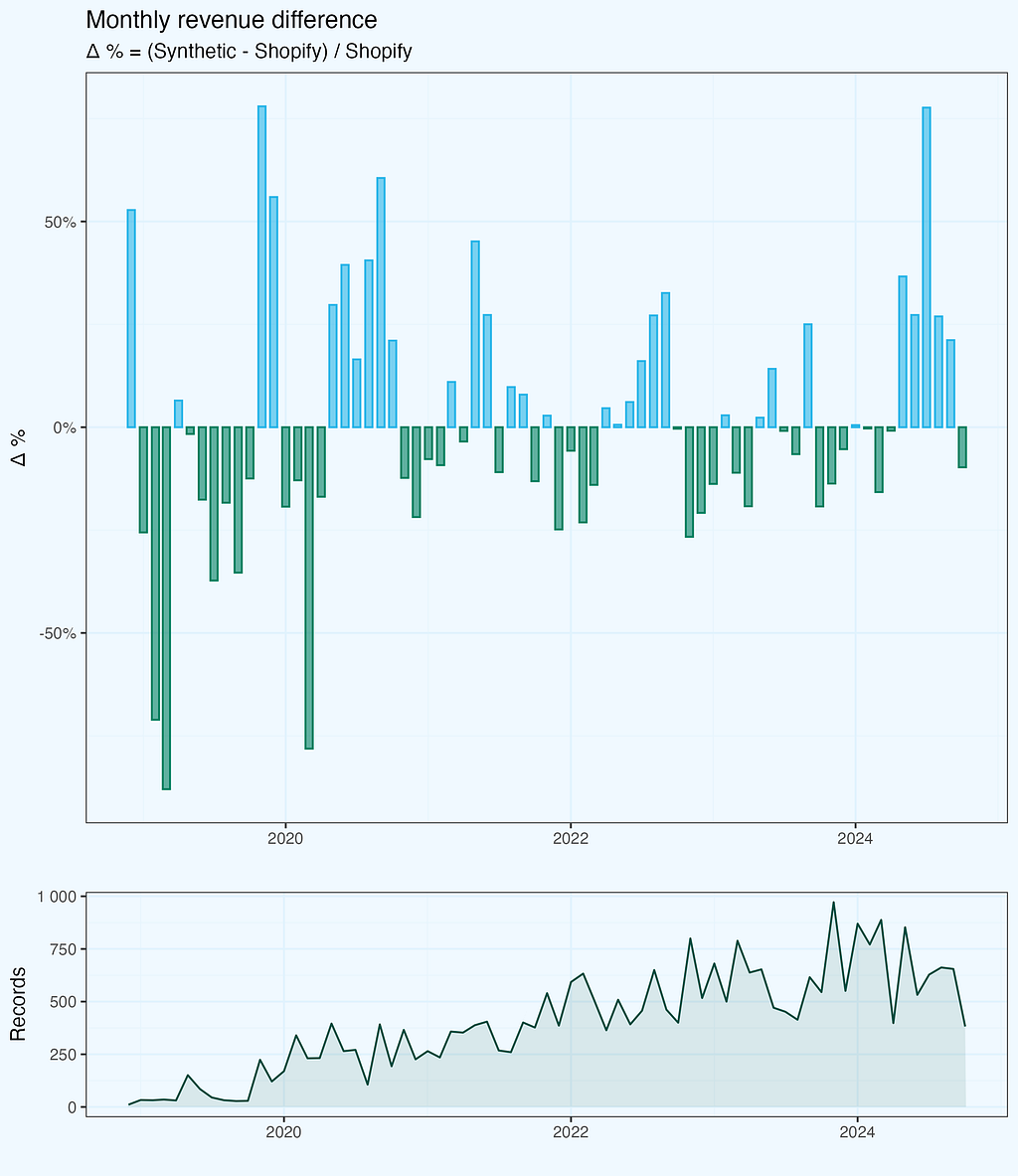
We see from the plot, that monthly revenue delta varies — sometimes original is bigger, and sometimes synthetic. But the bars seem to be symmetrical and also the differences are getting smaller with time. I added number of records (transactions) per month, maybe it has some impact? Let’s dig a bit deeper.
The deltas are indeed quite well balanced, and if we look at the cumulative revenue lines, they are very well aligned, without large variations. I am skipping this chart.
Sample Size Impact
The deltas are getting smaller, and we intuitively feel it is because of larger number of records. Let us check it — next plot shows absolute values of revenue deltas as a function of records per month. While the number of records does grow with time, the X axis is not exactly time — it’s the records.
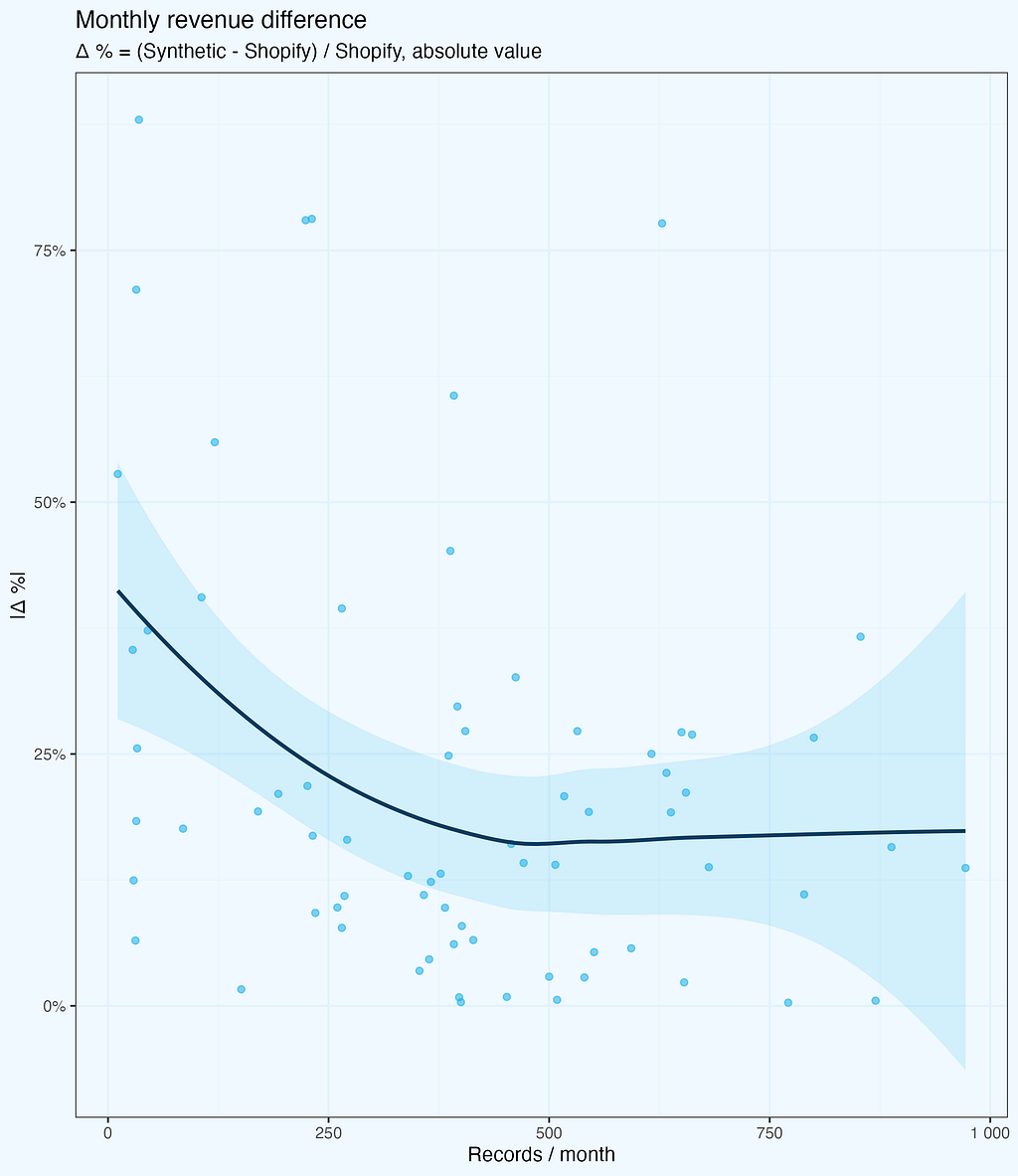
The deltas (absolute values) do decrease, as the number of records per month is higher — as we expected. But there is one more thing, quite intriguing, and not that obvious, at least at first glance. Above around 500 records per month, the deltas do not fall further, they stay at (in average) more or less same level.
While this specific number is derived from our dataset and might vary for different business types or data structures, the pattern itself is important: there exists a threshold where synthetic data stability improves significantly. Below this threshold, we see high variance; above it, the differences stabilize but don’t disappear entirely — synthetic data maintains some variation by design, which actually helps with privacy protection.
There is a noise, which makes monthly values randomized, also with larger samples. All, while preserves consistency on higher aggregates (yearly, or cumulative). And while reproducing overall trend very well.
It would be quite interesting to see similar chart for other metrics and datasets.
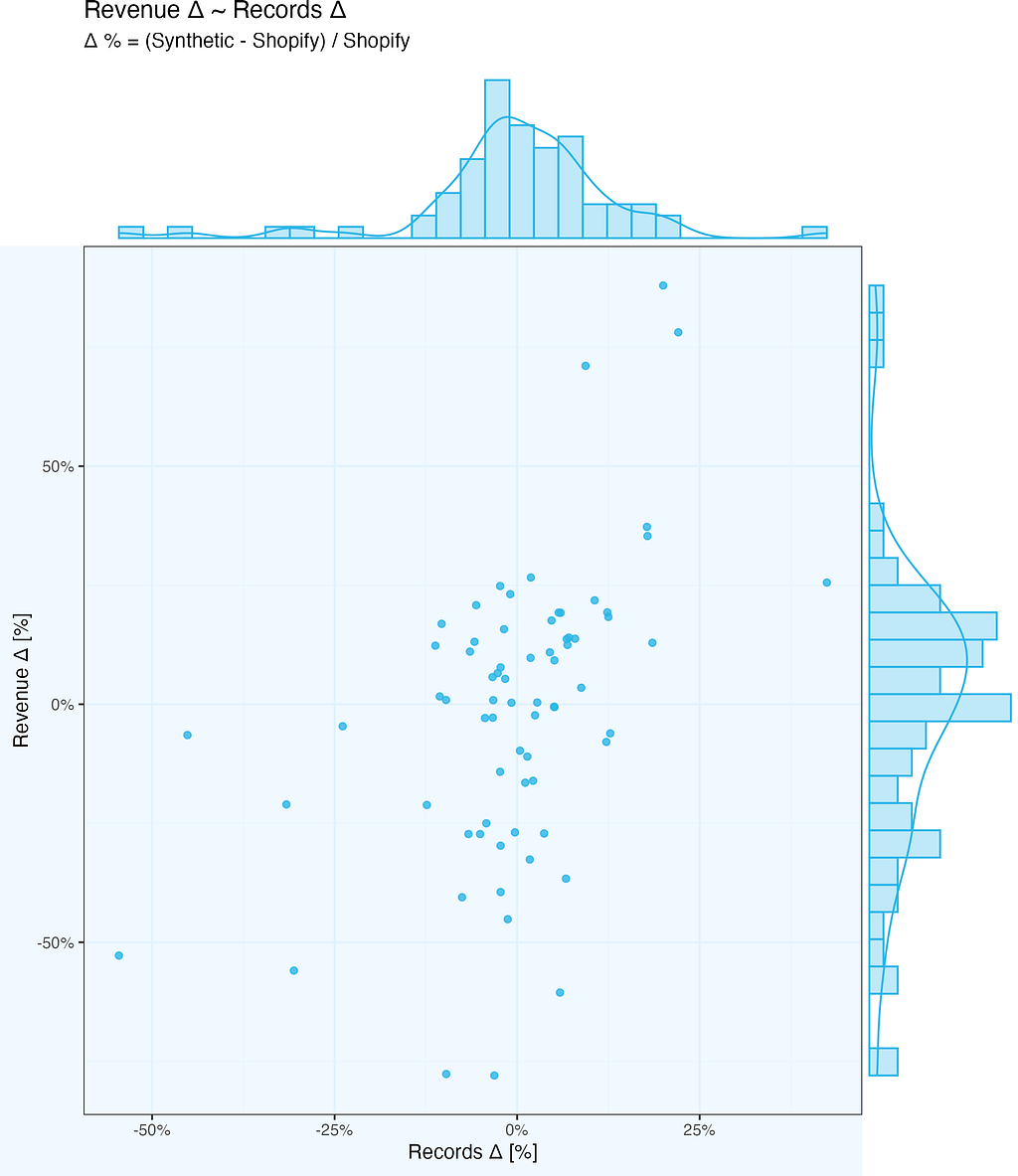
We already know revenue delta depends on number of records, but is it just that more records in a given month, the higher the revenue of synthetic data? Let us find out …
So we want to check how revenue delta depends on number of records delta. And we mean by delta Synthetic-Shopify, whether it is monthly revenue or monthly number of records.
The chart below shows exactly this relationship. There is some (light) correlation – if number of records per month differ substantially between Synthetic and Shopify, or vice-versa (high delta values), the revenue delta follows. But it is far from simple linear relationship – there is extra noise there as well.
Dimensional Analysis
When generating synthetic data, we often need to preserve not just overall metrics, but also their distribution across different dimensions like geography. I kept country and state columns in our test dataset to see how synthetic data handles dimensional analysis.
The results reveal two important aspects:
- The reliability of synthetic data strongly depends on the sample size within each dimension
- Dependencies between dimensions are not preserved
Looking at revenue by country:
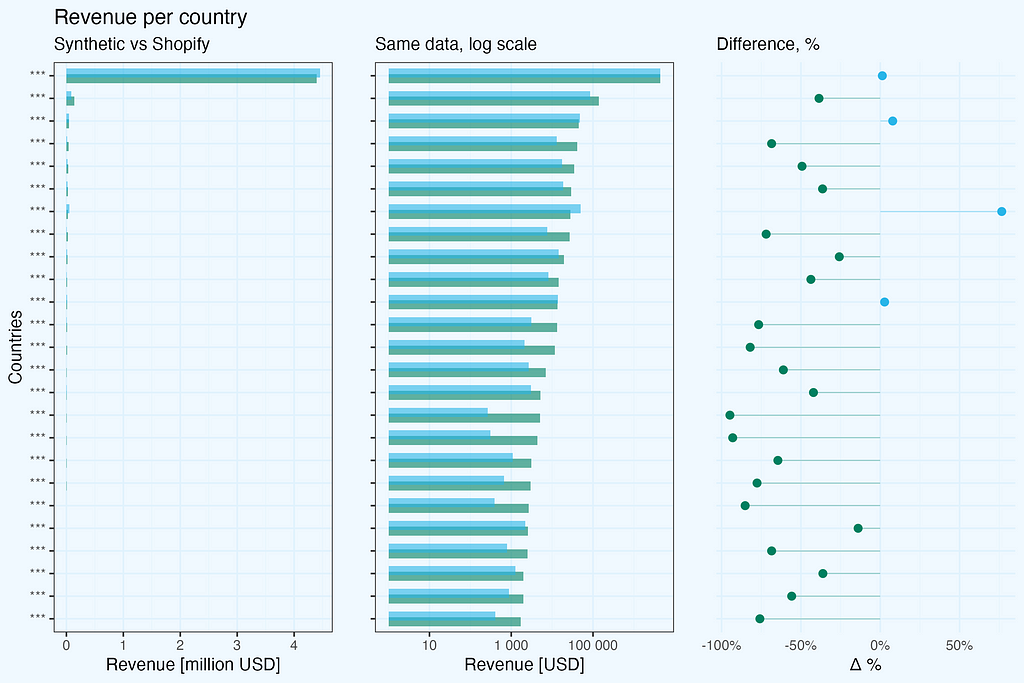
For the dominant market with thousands of transactions, the synthetic data provides a reliable representation — revenue totals are comparable between real and synthetic datasets. However, for countries with fewer transactions, the differences become significant.
A critical observation about dimensional relationships: in the original dataset, state information appears only for US transactions, with empty values for other countries. However, in the synthetic data, this relationship is lost — we see randomly generated values in both country and state columns, including states assigned to other countries, not US. This highlights an important limitation: synthetic data generation does not maintain logical relationships between dimensions.
There is, however, a practical way to overcome this country-state dependency issue. Before generating synthetic data, we could preprocess our input by concatenating country and state into a single dimension (e.g., ‘US-California’, ‘US-New York’, while keeping just ‘Germany’ or ‘France’ for non-US transactions). This simple preprocessing step would preserve the business logic of states being US-specific and prevent the generation of invalid country-state combinations in the synthetic data.
This has important practical implications:
- Synthetic data works well for high-volume segments
- Be cautious when analyzing smaller segments
- Always check sample sizes before drawing conclusions
- Be aware that logical relationships between dimensions may be lost, consider pre-aggregation of some columns
- Consider additional data validation if dimensional integrity is crucial
Transaction value distribution
One of the most interesting findings in this analysis comes from examining transaction value distributions. Looking at these distributions year by year reveals both the strengths and limitations of synthetic data.

The original Shopify data shows what you’d typically expect in e-commerce: highly asymmetric distribution with a long tail towards higher values, and distinct peaks corresponding to popular single-product transactions, showing clear bestseller patterns.
The synthetic data tells an interesting story: it maintains very well the overall shape of the distribution, but the distinct peaks from bestseller products are smoothed out. The distribution becomes more “theoretical”, losing some real-world specifics.
This smoothing effect isn’t necessarily a bad thing. In fact, it might be preferable in some cases:
- For general business modeling and forecasting
- When you want to avoid overfitting to specific product patterns
- If you’re looking for underlying trends rather than specific product effects
However, if you’re specifically interested in bestseller analysis or single-product transaction patterns, you’ll need to factor in this limitation of synthetic data.
Knowing, the goal is product analysis, we’d prepare original dataset differently.
To quantify how well the synthetic data matches the real distribution, we’ll look at statistical validation in the next section.
Statistical Validation (K-S Test)
Let’s validate our observations with the Kolmogorov-Smirnov test — a standard statistical method for comparing two distributions.

The findings are positive, but what do these figures mean in practice? The Kolmogorov-Smirnov test compares two distributions and returns two essential metrics: D = 0.012201 (smaller is better, with 0 indicating identical distributions), and p-value = 0.0283 (below the normal 0.05 level, indicating statistically significant differences).
While the p-value indicates some variations between distributions, the very low D statistic (nearly to 0) verifies the plot’s findings: a near-perfect match in the middle, with just slight differences at the extremities. The synthetic data captures crucial patterns while keeping enough variance to ensure anonymity, making it suitable for commercial analytics.
In practical terms, this means:
- The synthetic data provides an excellent match in the most important mid-range of transaction values
- The match is particularly strong where we have the most data points
- Differences appear mainly in edge cases, which is expected and even desirable from a privacy perspective
- The statistical validation confirms our visual observations from the distribution plots
This kind of statistical validation is crucial before deciding to use synthetic data for any specific analysis. In our case, the results suggest that the synthetic dataset is reliable for most business analytics purposes, especially when focusing on typical transaction patterns rather than extreme values.
Conclusions
Let’s summarize our journey from real Shopify transactions to their synthetic counterpart.
Overall business trends and patterns are maintained, including transactions value distributions. Spikes are ironed out, resulting in more theoretical distributions, while maintaining key characteristics.
Sample size matters, by design. Going too granular we will get noise, preserving confidentiality (in addition to removing all PII of course).
Dependencies between columns are not preserved (country-state), but there is an easy walk around, so I think it is not a real issue.
It is important to understand how the generated dataset will be used — what kind of analysis we expect, so that we can take it into account while reshaping the original dataset.
The synthetic dataset will work perfectly for applications testing, but we should manually check edge cases, as these might be missed during generation.
In our Shopify case, the synthetic data proved reliable enough for most business analytics scenarios, especially when working with larger samples and focusing on general patterns rather than specific product-level analysis.
Future Work
This analysis focused on transactions, as one of key metrics and an easy case to start with.
We can proceed with products analysis and also explore multi-table scenarios.
It is also worth to develop internal guidelines how to use synthetic data, including check and limitations.
Appendix: Data Preparation and Methodology
You can scroll through this section, as it is quite technical on how to prepare data.
Raw Data Export
Instead of relying on pre-aggregated Shopify reports, I went straight for the raw transaction data. At Alta Media, this is our standard approach — we prefer working with raw data to maintain full control over the analysis process.
The export process from Shopify is straightforward but not immediate:
- Request raw transaction data export from the admin panel
- Wait for email with download links
- Download multiple ZIP files containing CSV data
Data Reshaping
I used R for exploratory data analysis, processing, and visualization. The code snippets are in R, copied from my working scripts, but of course one can use other languages to achieve the same final data frame.
The initial dataset had dozens of columns, so the first step was to select only the relevant ones for our synthetic data experiment.
Code formatting is adjusted, so that we don’t have horizontal scroll.
#-- 0. libs
pacman::p_load(data.table, stringr, digest)
#-- 1.1 load data; the csv files are what we get as a
# full export from Shopify
xs1_dt <- fread(file = "shopify_raw/orders_export_1.csv")
xs2_dt <- fread(file = "shopify_raw/orders_export_2.csv")
xs3_dt <- fread(file = "shopify_raw/orders_export_3.csv")
#-- 1.2 check all columns, limit them to essential (for this analysis)
# and bind into one data.table
xs1_dt |> colnames()
# there are 79 columns in full export, so we select a subset,
# relevant for this analysis
sel_cols <- c(
"Name", "Email", "Paid at", "Fulfillment Status", "Accepts Marketing",
"Currency", "Subtotal",
"Lineitem quantity", "Lineitem name", "Lineitem price", "Lineitem sku",
"Discount Amount", "Billing Province", "Billing Country")
We need one data frame, so we need to combine three files. Since we use data.table package, the syntax is very simple. And we pipe combined dataset to trim columns, keeping only selected ones.
xs_dt <- data.table::rbindlist(
l = list(xs1_dt, xs2_dt, xs3_dt),
use.names = T, fill = T, idcol = T) %>% .[, ..sel_cols]
Let’s also change column names to single string, replacing spaces with underscore “_” — we don’t need to deal with extra quotations in SQL.
#-- 2. data prep
#-- 2.1 replace spaces in column names, for easier handling
sel_cols_new <- sel_cols |>
stringr::str_replace(pattern = " ", replacement = "_")
setnames(xs_dt, old = sel_cols, new = sel_cols_new)
I also change transaction id from character “#1234”, to numeric “1234”. I create a new column, so we can easily compare if transformation went as expected.
xs_dt[, `:=` (Transaction_id = stringr::str_remove(Name, pattern = "#") |>
as.integer())]
Of course you can also overwrite.
Extra experimentation
Since this was an experiment with Snowflake’s synthetic data generation, I made some additional preparations. The Shopify export contains actual customer emails, which would be masked in Snowflake while generating synthetic data, but I hashed them anyway.
So I hashed these emails using MD5 and created an additional column with numerical hashes. This was purely experimental — I wanted to see how Snowflake handles different types of unique identifiers.
By default, Snowflake masks text-based unique identifiers as it considers them personally identifiable information. For a real application, we’d want to remove any data that could potentially identify customers.
new_cols <- c("Email_hash", "e_number")
xs_dt[, (new_cols) := .(digest::digest(Email, algo = "md5"),
digest::digest2int(Email, seed = 0L)), .I]
I was also curious how logical column will be handled, so I changed type of a binary column, which has “yes/no” values.
#-- 2.3 change Accepts_Marketing to logical column
xs_dt[, `:=` (Accepts_Marketing_lgcl = fcase(
Accepts_Marketing == "yes", TRUE,
Accepts_Marketing == "no", FALSE,
default = NA))]
Filter transactions
The dataset contains records per each item, while for this particular analysis we need only transactions.
xs_dt[Transaction_id == 31023, .SD, .SDcols = c(
"Transaction_id", "Paid_at", "Currency", "Subtotal", "Discount_Amount",
"Lineitem_quantity", "Lineitem_price", "Billing_Country")]

Final subset of columns and filtering records with total amount paid.
trans_sel_cols <- c(
"Transaction_id", "Email_hash", "e_number", "Paid_at", "Subtotal",
"Currency", "Billing_Province", "Billing_Country",
"Fulfillment_Status", "Accepts_Marketing_lgcl")
xst_dt <- xs_dt[!is.na(Paid_at), ..trans_sel_cols]
Export dataset
Once we have a dataset, we nee to export it as a csv file. I export full dataset, and I also produce a 5% sample, which I use for initial test run in Snowflake.
#-- full dataset
xst_dt |> fwrite(file = "data/transactions_a.csv")
#-- a 5% sample
xst_5pct_dt <- xst_dt[sample(.N, .N * .05)]
xst_5pct_dt |> fwrite(file = "data/transactions_a_5pct.csv")
And also saving in Rds format, so I don’t need to repeat all the preparatory steps (which are scripted, so they are executed in seconds anyway).
#-- 3.3 save Rds file
list(xs_dt = xs_dt, xst_dt = xst_dt, xst_5pct_dt = xst_5pct_dt) |>
saveRDS(file = "data/xs_lst.Rds")
Appendix: Data generation in Snowflake
Once we have our dataset, prepared according to our needs, generation of it’s synthetic “sibling” is straightforward. One needs to upload the data, run generation, and export results. For details follow Snowflake guidelines. Anyway, I will add here short summary, for complteness of this article.
First, we need to make some preparations — role, database and warehouse.
USE ROLE ACCOUNTADMIN;
CREATE OR REPLACE ROLE data_engineer;
CREATE OR REPLACE DATABASE syndata_db;
CREATE OR REPLACE WAREHOUSE syndata_wh WITH
WAREHOUSE_SIZE = 'MEDIUM'
WAREHOUSE_TYPE = 'SNOWPARK-OPTIMIZED';
GRANT OWNERSHIP ON DATABASE syndata_db TO ROLE data_engineer;
GRANT USAGE ON WAREHOUSE syndata_wh TO ROLE data_engineer;
GRANT ROLE data_engineer TO USER "PIOTR";
USE ROLE data_engineer;
Create schema and stage, if not defined yet.
CREATE SCHEMA syndata_db.experimental;
CREATE STAGE syn_upload
DIRECTORY = ( ENABLE = true )
COMMENT = 'import files';
Upload csv files(s) to stage, and then import them to table(s).
Then, run generation of synthetic data. I like having a small “pilot”, somethiong like 5% records to make initial check if it goes through. It is a time saver (and costs too), in case of more complicated cases, where we might need some SQL adjustment. In this case it is rather pro-forma.
-- generate synthetic
-- small file, 5% records
call snowflake.data_privacy.generate_synthetic_data({
'datasets':[
{
'input_table': 'syndata_db.experimental.transactions_a_5pct',
'output_table': 'syndata_db.experimental.transactions_a_5pct_synth'
}
],
'replace_output_tables':TRUE
});
It is good to inspect what we have as a result — checking tables directly in Snowflake.
And then run a full dataset.
-- large file, all records
call snowflake.data_privacy.generate_synthetic_data({
'datasets':[
{
'input_table': 'syndata_db.experimental.transactions_a',
'output_table': 'syndata_db.experimental.transactions_a_synth'
}
],
'replace_output_tables':TRUE
});
The execution time is non-linear, for the full dataset it is way, way faster than what data volume would suggest.
Now we export files.
Some preparations:
-- export files to unload stage
CREATE STAGE syn_unload
DIRECTORY = ( ENABLE = true )
COMMENT = 'export files';
CREATE OR REPLACE FILE FORMAT my_csv_unload_format
TYPE = 'CSV'
FIELD_DELIMITER = ','
FIELD_OPTIONALLY_ENCLOSED_BY = '"';
And export (small and full dataset):
COPY INTO @syn_unload/transactions_a_5pct_synth
FROM syndata_db.experimental.transactions_a_5pct_synth
FILE_FORMAT = my_csv_unload_format
HEADER = TRUE;
COPY INTO @syn_unload/transactions_a_synth
FROM syndata_db.experimental.transactions_a_synth
FILE_FORMAT = my_csv_unload_format
HEADER = TRUE;
So now we have both original Shopify dataset and Synthetic. Time to analyze, compare, and make some plots.
Appendix: Data comparison & charting
For this analysis, I used R for both data processing and visualization. The choice of tools, however, is secondary — the key is having a systematic approach to data preparation and validation. Whether you use R, Python, or other tools, the important steps remain the same:
- Clean and standardize the input data
- Validate the transformations
- Create reproducible analysis
- Document key decisions
The detailed code and visualization techniques could indeed be a topic for another article.
If you’re interested in specific aspects of the implementation, feel free to reach out.
Synthetic Data in Practice: A Shopify Case Study was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Testing new Snowflake functionality with a 30k records datasetImage created with DALL·E, based on author’s promptWorking with data, I keep running into the same problem more and more often. On one hand, we have growing requirements for data privacy and confidentiality; on the other — the need to make quick, data-driven decisions. Add to this the modern business reality: freelancers, consultants, short-term projects.As a decision maker, I face a dilemma: I need analysis right now, the internal team is overloaded, and I can’t just hand over confidential data to every external analyst.And this is where synthetic data comes in.But wait — I don’t want to write another theoretical article about what synthetic data is. There are enough of those online already. Instead, I’ll show you a specific comparison: 30 thousand real Shopify transactions versus their synthetic counterpart.What exactly did I check?How faithfully does synthetic data reflect real trends?Where are the biggest discrepancies?When can we trust synthetic data, and when should we be cautious?This won’t be another “how to generate synthetic data” guide (though I’ll show the code too). I’m focusing on what really matters — whether this data is actually useful and what its limitations are.I’m a practitioner — less theory, more specifics. Let’s begin.Data OverviewWhen testing synthetic data, you need a solid reference point. In our case, we’re working with real transaction data from a growing e-commerce business:30,000 transactions spanning 6 yearsClear growth trend year over yearMix of high and low-volume sales monthsDiverse geographical spread, with one dominant marketAll charts created by author, using his own R codeFor practical testing, I focused on transaction-level data such as order values, dates, and basic geographic information. Most assessments require only essential business information, without personal or product specifics.The procedure was simple: export raw Shopify data, analyze it to maintain only the most important information, produce synthetic data in Snowflake, then compare the two datasets side by side. One can think of it as generating a “digital twin” of your business data, with comparable trends but entirely anonymized.[Technical note: If you’re interested in the detailed data preparation process, including R code and Snowflake setup, check the appendix at the end of this article.]Monthly Revenue AnalysisThe first test for any synthetic dataset is how well it captures core business metrics. Let’s start with monthly revenue — arguably the most important metric for any business (for sure in top 3).Looking at the raw trends (Figure 1), both datasets follow a similar pattern: steady growth over the years with seasonal fluctuations. The synthetic data captures the general trend well, including the business’s growth trajectory. However, when we dig deeper into the differences, some interesting patterns emerge.To quantify these differences, I calculated a monthly delta:Δ % = (Synthetic – Shopify) / ShopifyWe see from the plot, that monthly revenue delta varies — sometimes original is bigger, and sometimes synthetic. But the bars seem to be symmetrical and also the differences are getting smaller with time. I added number of records (transactions) per month, maybe it has some impact? Let’s dig a bit deeper.The deltas are indeed quite well balanced, and if we look at the cumulative revenue lines, they are very well aligned, without large variations. I am skipping this chart.Sample Size ImpactThe deltas are getting smaller, and we intuitively feel it is because of larger number of records. Let us check it — next plot shows absolute values of revenue deltas as a function of records per month. While the number of records does grow with time, the X axis is not exactly time — it’s the records.The deltas (absolute values) do decrease, as the number of records per month is higher — as we expected. But there is one more thing, quite intriguing, and not that obvious, at least at first glance. Above around 500 records per month, the deltas do not fall further, they stay at (in average) more or less same level.While this specific number is derived from our dataset and might vary for different business types or data structures, the pattern itself is important: there exists a threshold where synthetic data stability improves significantly. Below this threshold, we see high variance; above it, the differences stabilize but don’t disappear entirely — synthetic data maintains some variation by design, which actually helps with privacy protection.There is a noise, which makes monthly values randomized, also with larger samples. All, while preserves consistency on higher aggregates (yearly, or cumulative). And while reproducing overall trend very well.It would be quite interesting to see similar chart for other metrics and datasets.We already know revenue delta depends on number of records, but is it just that more records in a given month, the higher the revenue of synthetic data? Let us find out …So we want to check how revenue delta depends on number of records delta. And we mean by delta Synthetic-Shopify, whether it is monthly revenue or monthly number of records.The chart below shows exactly this relationship. There is some (light) correlation – if number of records per month differ substantially between Synthetic and Shopify, or vice-versa (high delta values), the revenue delta follows. But it is far from simple linear relationship – there is extra noise there as well.Dimensional AnalysisWhen generating synthetic data, we often need to preserve not just overall metrics, but also their distribution across different dimensions like geography. I kept country and state columns in our test dataset to see how synthetic data handles dimensional analysis.The results reveal two important aspects:The reliability of synthetic data strongly depends on the sample size within each dimensionDependencies between dimensions are not preservedLooking at revenue by country:For the dominant market with thousands of transactions, the synthetic data provides a reliable representation — revenue totals are comparable between real and synthetic datasets. However, for countries with fewer transactions, the differences become significant.A critical observation about dimensional relationships: in the original dataset, state information appears only for US transactions, with empty values for other countries. However, in the synthetic data, this relationship is lost — we see randomly generated values in both country and state columns, including states assigned to other countries, not US. This highlights an important limitation: synthetic data generation does not maintain logical relationships between dimensions.There is, however, a practical way to overcome this country-state dependency issue. Before generating synthetic data, we could preprocess our input by concatenating country and state into a single dimension (e.g., ‘US-California’, ‘US-New York’, while keeping just ‘Germany’ or ‘France’ for non-US transactions). This simple preprocessing step would preserve the business logic of states being US-specific and prevent the generation of invalid country-state combinations in the synthetic data.This has important practical implications:Synthetic data works well for high-volume segmentsBe cautious when analyzing smaller segmentsAlways check sample sizes before drawing conclusionsBe aware that logical relationships between dimensions may be lost, consider pre-aggregation of some columnsConsider additional data validation if dimensional integrity is crucialTransaction value distributionOne of the most interesting findings in this analysis comes from examining transaction value distributions. Looking at these distributions year by year reveals both the strengths and limitations of synthetic data.The original Shopify data shows what you’d typically expect in e-commerce: highly asymmetric distribution with a long tail towards higher values, and distinct peaks corresponding to popular single-product transactions, showing clear bestseller patterns.The synthetic data tells an interesting story: it maintains very well the overall shape of the distribution, but the distinct peaks from bestseller products are smoothed out. The distribution becomes more “theoretical”, losing some real-world specifics.This smoothing effect isn’t necessarily a bad thing. In fact, it might be preferable in some cases:For general business modeling and forecastingWhen you want to avoid overfitting to specific product patternsIf you’re looking for underlying trends rather than specific product effectsHowever, if you’re specifically interested in bestseller analysis or single-product transaction patterns, you’ll need to factor in this limitation of synthetic data.Knowing, the goal is product analysis, we’d prepare original dataset differently.To quantify how well the synthetic data matches the real distribution, we’ll look at statistical validation in the next section.Statistical Validation (K-S Test)Let’s validate our observations with the Kolmogorov-Smirnov test — a standard statistical method for comparing two distributions.The findings are positive, but what do these figures mean in practice? The Kolmogorov-Smirnov test compares two distributions and returns two essential metrics: D = 0.012201 (smaller is better, with 0 indicating identical distributions), and p-value = 0.0283 (below the normal 0.05 level, indicating statistically significant differences).While the p-value indicates some variations between distributions, the very low D statistic (nearly to 0) verifies the plot’s findings: a near-perfect match in the middle, with just slight differences at the extremities. The synthetic data captures crucial patterns while keeping enough variance to ensure anonymity, making it suitable for commercial analytics.In practical terms, this means:The synthetic data provides an excellent match in the most important mid-range of transaction valuesThe match is particularly strong where we have the most data pointsDifferences appear mainly in edge cases, which is expected and even desirable from a privacy perspectiveThe statistical validation confirms our visual observations from the distribution plotsThis kind of statistical validation is crucial before deciding to use synthetic data for any specific analysis. In our case, the results suggest that the synthetic dataset is reliable for most business analytics purposes, especially when focusing on typical transaction patterns rather than extreme values.ConclusionsLet’s summarize our journey from real Shopify transactions to their synthetic counterpart.Overall business trends and patterns are maintained, including transactions value distributions. Spikes are ironed out, resulting in more theoretical distributions, while maintaining key characteristics.Sample size matters, by design. Going too granular we will get noise, preserving confidentiality (in addition to removing all PII of course).Dependencies between columns are not preserved (country-state), but there is an easy walk around, so I think it is not a real issue.It is important to understand how the generated dataset will be used — what kind of analysis we expect, so that we can take it into account while reshaping the original dataset.The synthetic dataset will work perfectly for applications testing, but we should manually check edge cases, as these might be missed during generation.In our Shopify case, the synthetic data proved reliable enough for most business analytics scenarios, especially when working with larger samples and focusing on general patterns rather than specific product-level analysis.Future WorkThis analysis focused on transactions, as one of key metrics and an easy case to start with.We can proceed with products analysis and also explore multi-table scenarios.It is also worth to develop internal guidelines how to use synthetic data, including check and limitations.Appendix: Data Preparation and MethodologyYou can scroll through this section, as it is quite technical on how to prepare data.Raw Data ExportInstead of relying on pre-aggregated Shopify reports, I went straight for the raw transaction data. At Alta Media, this is our standard approach — we prefer working with raw data to maintain full control over the analysis process.The export process from Shopify is straightforward but not immediate:Request raw transaction data export from the admin panelWait for email with download linksDownload multiple ZIP files containing CSV dataData ReshapingI used R for exploratory data analysis, processing, and visualization. The code snippets are in R, copied from my working scripts, but of course one can use other languages to achieve the same final data frame.The initial dataset had dozens of columns, so the first step was to select only the relevant ones for our synthetic data experiment.Code formatting is adjusted, so that we don’t have horizontal scroll.#– 0. libspacman::p_load(data.table, stringr, digest)#– 1.1 load data; the csv files are what we get as a # full export from Shopifyxs1_dt <- fread(file = “shopify_raw/orders_export_1.csv”)xs2_dt <- fread(file = “shopify_raw/orders_export_2.csv”)xs3_dt <- fread(file = “shopify_raw/orders_export_3.csv”)#– 1.2 check all columns, limit them to essential (for this analysis) # and bind into one data.tablexs1_dt |> colnames()# there are 79 columns in full export, so we select a subset, # relevant for this analysissel_cols <- c(“Name”, “Email”, “Paid at”, “Fulfillment Status”, “Accepts Marketing”, “Currency”, “Subtotal”, “Lineitem quantity”, “Lineitem name”, “Lineitem price”, “Lineitem sku”, “Discount Amount”, “Billing Province”, “Billing Country”)We need one data frame, so we need to combine three files. Since we use data.table package, the syntax is very simple. And we pipe combined dataset to trim columns, keeping only selected ones.xs_dt <- data.table::rbindlist( l = list(xs1_dt, xs2_dt, xs3_dt), use.names = T, fill = T, idcol = T) %>% .[, ..sel_cols]Let’s also change column names to single string, replacing spaces with underscore “_” — we don’t need to deal with extra quotations in SQL.#– 2. data prep#– 2.1 replace spaces in column names, for easier handlingsel_cols_new <- sel_cols |> stringr::str_replace(pattern = ” “, replacement = “_”)setnames(xs_dt, old = sel_cols, new = sel_cols_new)I also change transaction id from character “#1234”, to numeric “1234”. I create a new column, so we can easily compare if transformation went as expected.xs_dt[, `:=` (Transaction_id = stringr::str_remove(Name, pattern = “#”) |> as.integer())]Of course you can also overwrite.Extra experimentationSince this was an experiment with Snowflake’s synthetic data generation, I made some additional preparations. The Shopify export contains actual customer emails, which would be masked in Snowflake while generating synthetic data, but I hashed them anyway.So I hashed these emails using MD5 and created an additional column with numerical hashes. This was purely experimental — I wanted to see how Snowflake handles different types of unique identifiers.By default, Snowflake masks text-based unique identifiers as it considers them personally identifiable information. For a real application, we’d want to remove any data that could potentially identify customers.new_cols <- c(“Email_hash”, “e_number”)xs_dt[, (new_cols) := .(digest::digest(Email, algo = “md5”), digest::digest2int(Email, seed = 0L)), .I]I was also curious how logical column will be handled, so I changed type of a binary column, which has “yes/no” values.#– 2.3 change Accepts_Marketing to logical columnxs_dt[, `:=` (Accepts_Marketing_lgcl = fcase( Accepts_Marketing == “yes”, TRUE, Accepts_Marketing == “no”, FALSE, default = NA))]Filter transactionsThe dataset contains records per each item, while for this particular analysis we need only transactions.xs_dt[Transaction_id == 31023, .SD, .SDcols = c( “Transaction_id”, “Paid_at”, “Currency”, “Subtotal”, “Discount_Amount”, “Lineitem_quantity”, “Lineitem_price”, “Billing_Country”)]Final subset of columns and filtering records with total amount paid.trans_sel_cols <- c( “Transaction_id”, “Email_hash”, “e_number”, “Paid_at”, “Subtotal”, “Currency”, “Billing_Province”, “Billing_Country”, “Fulfillment_Status”, “Accepts_Marketing_lgcl”)xst_dt <- xs_dt[!is.na(Paid_at), ..trans_sel_cols]Export datasetOnce we have a dataset, we nee to export it as a csv file. I export full dataset, and I also produce a 5% sample, which I use for initial test run in Snowflake.#– full datasetxst_dt |> fwrite(file = “data/transactions_a.csv”)#– a 5% samplexst_5pct_dt <- xst_dt[sample(.N, .N * .05)]xst_5pct_dt |> fwrite(file = “data/transactions_a_5pct.csv”)And also saving in Rds format, so I don’t need to repeat all the preparatory steps (which are scripted, so they are executed in seconds anyway).#– 3.3 save Rds filelist(xs_dt = xs_dt, xst_dt = xst_dt, xst_5pct_dt = xst_5pct_dt) |> saveRDS(file = “data/xs_lst.Rds”)Appendix: Data generation in SnowflakeOnce we have our dataset, prepared according to our needs, generation of it’s synthetic “sibling” is straightforward. One needs to upload the data, run generation, and export results. For details follow Snowflake guidelines. Anyway, I will add here short summary, for complteness of this article.First, we need to make some preparations — role, database and warehouse.USE ROLE ACCOUNTADMIN;CREATE OR REPLACE ROLE data_engineer;CREATE OR REPLACE DATABASE syndata_db;CREATE OR REPLACE WAREHOUSE syndata_wh WITH WAREHOUSE_SIZE = ‘MEDIUM’ WAREHOUSE_TYPE = ‘SNOWPARK-OPTIMIZED’;GRANT OWNERSHIP ON DATABASE syndata_db TO ROLE data_engineer;GRANT USAGE ON WAREHOUSE syndata_wh TO ROLE data_engineer;GRANT ROLE data_engineer TO USER “PIOTR”;USE ROLE data_engineer;Create schema and stage, if not defined yet.CREATE SCHEMA syndata_db.experimental;CREATE STAGE syn_upload DIRECTORY = ( ENABLE = true ) COMMENT = ‘import files’;Upload csv files(s) to stage, and then import them to table(s).Then, run generation of synthetic data. I like having a small “pilot”, somethiong like 5% records to make initial check if it goes through. It is a time saver (and costs too), in case of more complicated cases, where we might need some SQL adjustment. In this case it is rather pro-forma.– generate synthetic– small file, 5% recordscall snowflake.data_privacy.generate_synthetic_data({ ‘datasets’:[ { ‘input_table’: ‘syndata_db.experimental.transactions_a_5pct’, ‘output_table’: ‘syndata_db.experimental.transactions_a_5pct_synth’ } ], ‘replace_output_tables’:TRUE});It is good to inspect what we have as a result — checking tables directly in Snowflake.And then run a full dataset.– large file, all recordscall snowflake.data_privacy.generate_synthetic_data({ ‘datasets’:[ { ‘input_table’: ‘syndata_db.experimental.transactions_a’, ‘output_table’: ‘syndata_db.experimental.transactions_a_synth’ } ], ‘replace_output_tables’:TRUE});The execution time is non-linear, for the full dataset it is way, way faster than what data volume would suggest.Now we export files.Some preparations:– export files to unload stageCREATE STAGE syn_unload DIRECTORY = ( ENABLE = true ) COMMENT = ‘export files’;CREATE OR REPLACE FILE FORMAT my_csv_unload_format TYPE = ‘CSV’ FIELD_DELIMITER = ‘,’ FIELD_OPTIONALLY_ENCLOSED_BY = ‘”‘;And export (small and full dataset):COPY INTO @syn_unload/transactions_a_5pct_synth FROM syndata_db.experimental.transactions_a_5pct_synthFILE_FORMAT = my_csv_unload_formatHEADER = TRUE;COPY INTO @syn_unload/transactions_a_synth FROM syndata_db.experimental.transactions_a_synthFILE_FORMAT = my_csv_unload_formatHEADER = TRUE;So now we have both original Shopify dataset and Synthetic. Time to analyze, compare, and make some plots.Appendix: Data comparison & chartingFor this analysis, I used R for both data processing and visualization. The choice of tools, however, is secondary — the key is having a systematic approach to data preparation and validation. Whether you use R, Python, or other tools, the important steps remain the same:Clean and standardize the input dataValidate the transformationsCreate reproducible analysisDocument key decisionsThe detailed code and visualization techniques could indeed be a topic for another article.If you’re interested in specific aspects of the implementation, feel free to reach out.Synthetic Data in Practice: A Shopify Case Study was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. snowflake, rstats, synthetic-data, data-privacy, hands-on-tutorials Towards Data Science – MediumRead More

 Add to favorites
Add to favorites

0 Comments