
Building more efficient AI
TLDR: Data-centric AI can create more efficient and accurate models. I experimented with data pruning on MNIST¹ to classify handwritten digits.
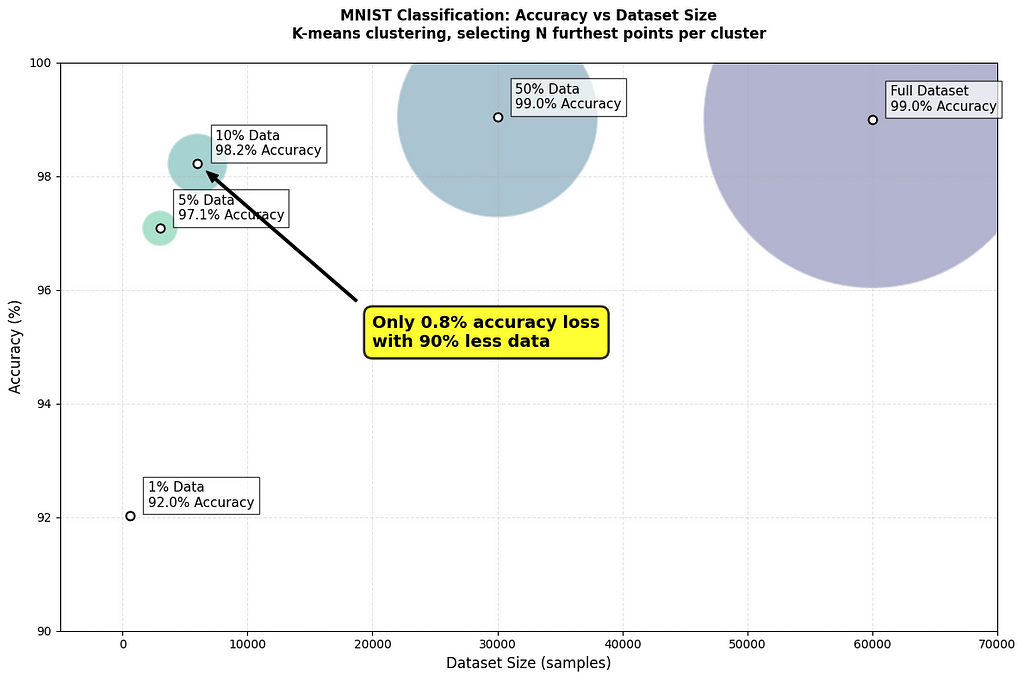
What if I told you that using just 50% of your training data could achieve better results than using the full dataset?
In my recent experiments with the MNIST dataset¹, that’s exactly what happened.
Even more surprisingly, using just 10% of well selected data still achieved over 98% accuracy.
Data Pruning Results
The plot above shows the model’s accuracy compared to the training dataset size when using the most effective pruning method I tested.
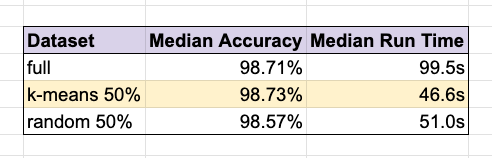
- Using 50% of the data with the “furthest-from-centroid” selection strategy achieved a median accuracy of 98.73%, slightly better than training on the full dataset (98.71%) with no data pruning.
- Even with just 10% of the data, the best run using “furthest-from-centroid” had 98.2% accuracy.
- Random sampling 10% of the dataset still hit 97.59% accuracy on it’s best run, without any selection strategy.
Overall, I found this fascinating. But it really leads me to question — how much data does AI really need?
What is Furthest-from-Centroid?
I tested several data pruning strategies.
The best-performing strategy was surprisingly simple:
- Group similar images into clusters using k-means.
- For each cluster, find its center point (centroid).
- Select the images that are furthest from their cluster’s center.
Think of each cluster as a group of similar-looking digits.
Instead of picking the most “typical” digit from each group, this method picks the unusual ones — the digits that are still recognizable but written in unique ways.
These outliers help the model learn more robust decision boundaries.
Why Furthest-from-Centroid Works
- Information Gain: Each selected example provides unique information about the decision boundary.
- Diversity: Captures varied writing styles and edge cases.
- Reduced Redundancy: Eliminates nearly identical examples that don’t add new information.
When you have abundant data, the marginal value of another typical example is low. Instead, focusing on boundary cases helps define decision boundaries better.
Here’s what the “furthest-from-centroid” samples look like compared to typical examples:




Notice how the selected samples capture more varied writing styles and edge cases.
In some examples like cluster 1, 3, and 8 the furthest point does just look like a more varied example of the prototypical center.
Cluster 6 is an interesting point, showcasing how some images are difficult even for a human to guess what it is. But you can still make out how this could be in a cluster with the centroid as an 8.
The Theory Behind Data Pruning
Recent research on neural scaling laws helps to explain why data pruning using a “furthest-from-centroid” approach works, especially on the MNIST dataset.
Data Redundancy
Many training examples in large datasets are highly redundant.
Think about MNIST: how many nearly identical ‘7’s do we really need? The key to data pruning isn’t having more examples — it’s having the right examples.
Selection Strategy vs Dataset Size
One of the most interesting findings from the above paper is how the optimal data selection strategy changes based on your dataset size:
- With “a lot” of data : Select harder, more diverse examples (furthest from cluster centers).
- With scarce data: Select easier, more typical examples (closest to cluster centers).
This explains why our “furthest-from-centroid” strategy worked so well.
With MNIST’s 60,000 training examples, we were in the “abundant data” regime where selecting diverse, challenging examples proved most beneficial.
The Full Experiment
Inspiration and Goals
I was inspired by these two recent papers (and the fact that I’m a data engineer):
- Beyond neural scaling laws: beating power law scaling via data pruning
- The MiniPile Challenge for Data-Efficient Language Models
Both explore various ways we can use data selection strategies to train performant models on less data.
Methodology
I used LeNet-5 as my model architecture.
Then using one of the strategies below I pruned the training dataset of MNIST and trained a model. Testing was done against the full test set.
Due to time constraints, I only ran 5 tests per experiment.
Full code and results available here on GitHub.
Strategy #1: Baseline, Full Dataset
- Standard LeNet-5 architecture
- Trained using 100% of training data
Strategy #2: Random Sampling
- Randomly sample individual images from the training dataset
Strategy #3: K-means Clustering with Different Selection Strategies
Here’s how this worked:
- Preprocess the images with PCA to reduce the dimensionality. This just means each image was reduced from 784 values (28×28 pixels) into only 50 values. PCA does this while retaining the most important patterns and removing redundant information.
- Cluster using k-means. The number of clusters was fixed at 50 and 500 in different tests. My poor CPU couldn’t handle much beyond 500 given all the experiments.
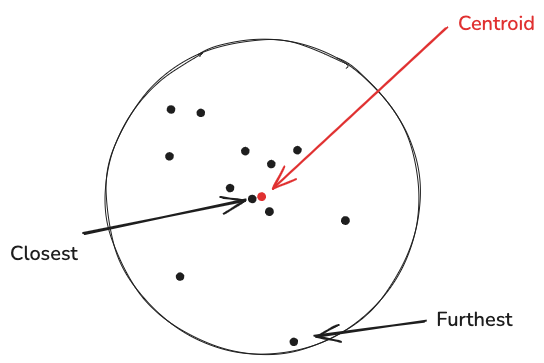
- I then tested different selection methods once the data was cluster:
- Closest-to-centroid — these represent a “typical” example of the cluster.
- Furthest-from-centroid — more representative of edge cases.
- Random from each cluster — randomly select within each cluster.
Technical Implementation Lessons Learned
- PCA reduced noise and computation time. At first I was just flattening the images. The results and compute both improved using PCA so I kept it for the full experiment.
- I switched from standard K-means to MiniBatchKMeans clustering for better speed. The standard algorithm was too slow for my CPU given all the tests.
- Setting up a proper test harness was key. Moving experiment configs to a YAML, automatically saving results to a file, and having o1 write my visualization code made life much easier.
Full Results
Median Accuracy & Run Time
Here are the median results, comparing our baseline LeNet-5 trained on the full dataset with two different strategies that used 50% of the dataset.
Accuracy vs Run Time Full Results
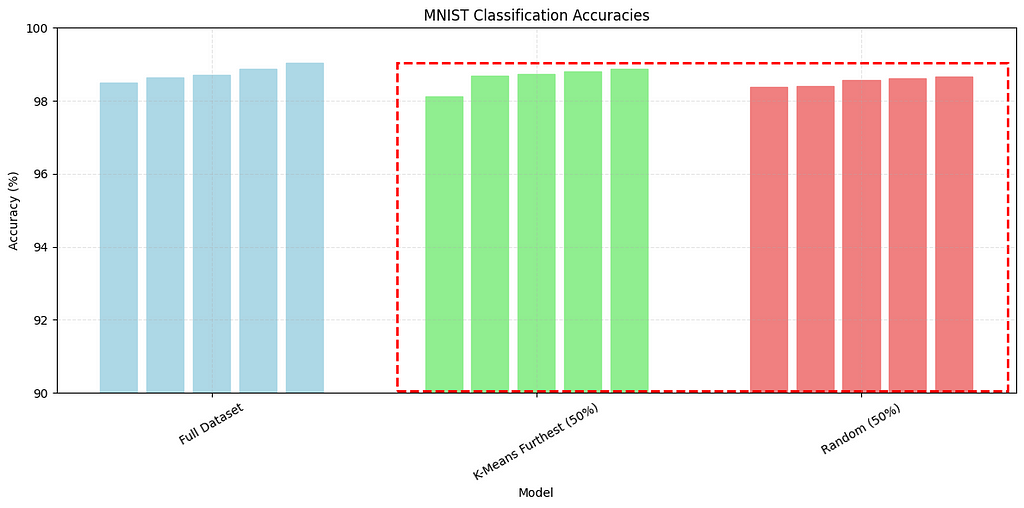
The below charts show the results of my four pruning strategies compared to the baseline in red.
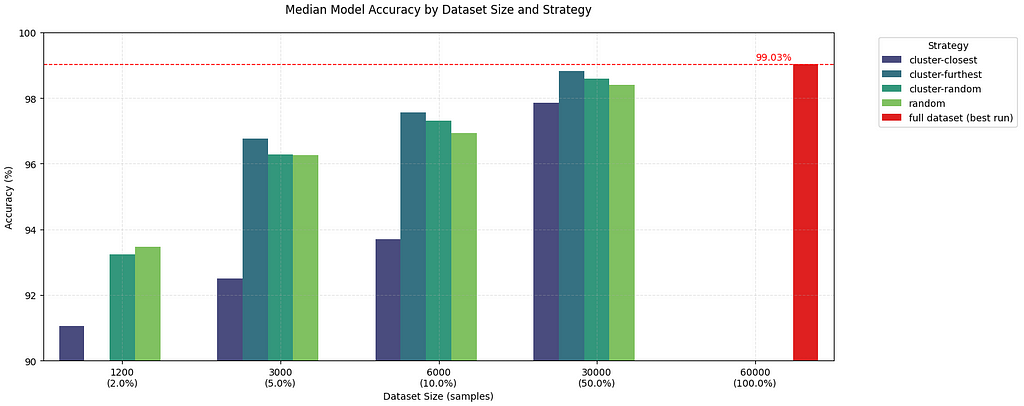
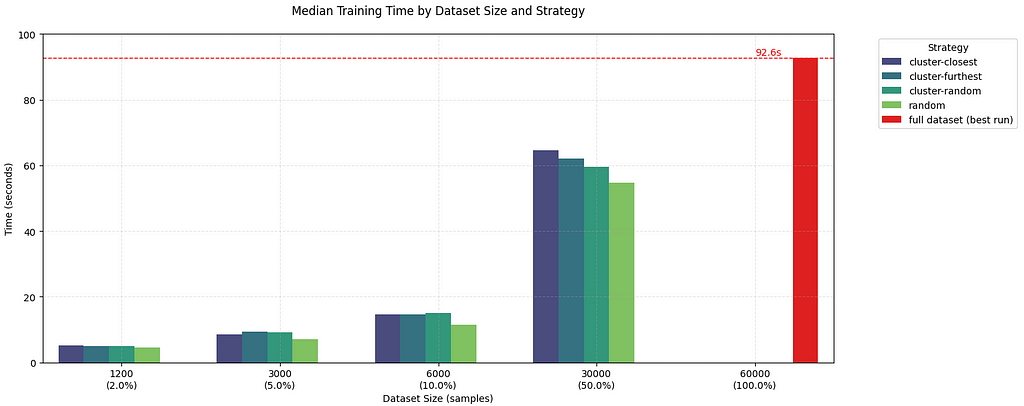
Key findings across multiple runs:
- Furthest-from-centroid consistently outperformed other methods
- There definitely is a sweet spot between compute time and and model accuracy if you want to find it for your use case. More work needs to be done here.
I’m still shocked that just randomly reducing the dataset gives acceptable results if efficiency is what you’re after.
Next Steps
Future Plans
- Test this on my second brain. I want to fine tune a LLM on my full Obsidian and test data pruning along with hierarchical summarization.
- Explore other embedding methods for clustering. I can try training an auto-encoder to embed the images rather than use PCA.
- Test this on more complex and larger datasets (CIFAR-10, ImageNet).
- Experiment with how model architecture impacts the performance of data pruning strategies.
Conclusion
These findings suggest we need to rethink our approach to dataset curation:
- More data isn’t always better — there seems to be diminishing returns to bigger data/ bigger models.
- Strategic pruning can actually improve results.
- The optimal strategy depends on your starting dataset size.
As people start sounding the alarm that we are running out of data, I can’t help but wonder if less data is actually the key to useful, cost-effective models.
I intend to continue exploring the space, please reach out if you find this interesting — happy to connect and talk more 🙂
I’m a Staff Data Engineer working on an Applied AI Research team building foundational time series models.
If you’d like to follow my work work or get in touch head to my blog.
References
- LeCun, Y., Cortes, C., & Burges, C. J. (2010). MNIST handwritten digit database. ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist or https://huggingface.co/datasets/ylecun/mnist
The MNIST dataset is used under the Creative Commons Attribution-Share Alike 3.0 license.
Data Pruning MNIST: How I Hit 99% Accuracy Using Half the Data was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Building more efficient AITLDR: Data-centric AI can create more efficient and accurate models. I experimented with data pruning on MNIST¹ to classify handwritten digits.Best runs for “furthest-from-centroid” selection compared to full dataset. Image by author.What if I told you that using just 50% of your training data could achieve better results than using the full dataset?In my recent experiments with the MNIST dataset¹, that’s exactly what happened.Even more surprisingly, using just 10% of well selected data still achieved over 98% accuracy.Data Pruning ResultsThe plot above shows the model’s accuracy compared to the training dataset size when using the most effective pruning method I tested.Using 50% of the data with the “furthest-from-centroid” selection strategy achieved a median accuracy of 98.73%, slightly better than training on the full dataset (98.71%) with no data pruning.Even with just 10% of the data, the best run using “furthest-from-centroid” had 98.2% accuracy.Random sampling 10% of the dataset still hit 97.59% accuracy on it’s best run, without any selection strategy.Overall, I found this fascinating. But it really leads me to question — how much data does AI really need?What is Furthest-from-Centroid?I tested several data pruning strategies.The best-performing strategy was surprisingly simple:Group similar images into clusters using k-means.For each cluster, find its center point (centroid).Select the images that are furthest from their cluster’s center.Think of each cluster as a group of similar-looking digits.Instead of picking the most “typical” digit from each group, this method picks the unusual ones — the digits that are still recognizable but written in unique ways.These outliers help the model learn more robust decision boundaries.Why Furthest-from-Centroid WorksInformation Gain: Each selected example provides unique information about the decision boundary.Diversity: Captures varied writing styles and edge cases.Reduced Redundancy: Eliminates nearly identical examples that don’t add new information.When you have abundant data, the marginal value of another typical example is low. Instead, focusing on boundary cases helps define decision boundaries better.Here’s what the “furthest-from-centroid” samples look like compared to typical examples:Centroid Image and Furthest-from-centroid Image of various clusters. Images from the MNIST dataset, reproduced by the author.Notice how the selected samples capture more varied writing styles and edge cases.In some examples like cluster 1, 3, and 8 the furthest point does just look like a more varied example of the prototypical center.Cluster 6 is an interesting point, showcasing how some images are difficult even for a human to guess what it is. But you can still make out how this could be in a cluster with the centroid as an 8.The Theory Behind Data PruningRecent research on neural scaling laws helps to explain why data pruning using a “furthest-from-centroid” approach works, especially on the MNIST dataset.Data RedundancyMany training examples in large datasets are highly redundant.Think about MNIST: how many nearly identical ‘7’s do we really need? The key to data pruning isn’t having more examples — it’s having the right examples.Selection Strategy vs Dataset SizeOne of the most interesting findings from the above paper is how the optimal data selection strategy changes based on your dataset size:With “a lot” of data : Select harder, more diverse examples (furthest from cluster centers).With scarce data: Select easier, more typical examples (closest to cluster centers).This explains why our “furthest-from-centroid” strategy worked so well.With MNIST’s 60,000 training examples, we were in the “abundant data” regime where selecting diverse, challenging examples proved most beneficial.The Full ExperimentInspiration and GoalsI was inspired by these two recent papers (and the fact that I’m a data engineer):Beyond neural scaling laws: beating power law scaling via data pruningThe MiniPile Challenge for Data-Efficient Language ModelsBoth explore various ways we can use data selection strategies to train performant models on less data.MethodologyI used LeNet-5 as my model architecture.Then using one of the strategies below I pruned the training dataset of MNIST and trained a model. Testing was done against the full test set.Due to time constraints, I only ran 5 tests per experiment.Full code and results available here on GitHub.Strategy #1: Baseline, Full DatasetStandard LeNet-5 architectureTrained using 100% of training dataStrategy #2: Random SamplingRandomly sample individual images from the training datasetStrategy #3: K-means Clustering with Different Selection StrategiesHere’s how this worked:Preprocess the images with PCA to reduce the dimensionality. This just means each image was reduced from 784 values (28×28 pixels) into only 50 values. PCA does this while retaining the most important patterns and removing redundant information.Cluster using k-means. The number of clusters was fixed at 50 and 500 in different tests. My poor CPU couldn’t handle much beyond 500 given all the experiments.I then tested different selection methods once the data was cluster:Closest-to-centroid — these represent a “typical” example of the cluster.Furthest-from-centroid — more representative of edge cases.Random from each cluster — randomly select within each cluster.Example of Clustering Selection. Image by author.Technical Implementation Lessons LearnedPCA reduced noise and computation time. At first I was just flattening the images. The results and compute both improved using PCA so I kept it for the full experiment.I switched from standard K-means to MiniBatchKMeans clustering for better speed. The standard algorithm was too slow for my CPU given all the tests.Setting up a proper test harness was key. Moving experiment configs to a YAML, automatically saving results to a file, and having o1 write my visualization code made life much easier.Full ResultsMedian Accuracy & Run TimeHere are the median results, comparing our baseline LeNet-5 trained on the full dataset with two different strategies that used 50% of the dataset.Median Results. Image by author.Median Accuracies. Image by author.Accuracy vs Run Time Full ResultsThe below charts show the results of my four pruning strategies compared to the baseline in red.Median Accuracy across Data Pruning methods. Image by author.Median Run time across Data Pruning methods. Image by author.Key findings across multiple runs:Furthest-from-centroid consistently outperformed other methodsThere definitely is a sweet spot between compute time and and model accuracy if you want to find it for your use case. More work needs to be done here.I’m still shocked that just randomly reducing the dataset gives acceptable results if efficiency is what you’re after.Next StepsFuture PlansTest this on my second brain. I want to fine tune a LLM on my full Obsidian and test data pruning along with hierarchical summarization.Explore other embedding methods for clustering. I can try training an auto-encoder to embed the images rather than use PCA.Test this on more complex and larger datasets (CIFAR-10, ImageNet).Experiment with how model architecture impacts the performance of data pruning strategies.ConclusionThese findings suggest we need to rethink our approach to dataset curation:More data isn’t always better — there seems to be diminishing returns to bigger data/ bigger models.Strategic pruning can actually improve results.The optimal strategy depends on your starting dataset size.As people start sounding the alarm that we are running out of data, I can’t help but wonder if less data is actually the key to useful, cost-effective models.I intend to continue exploring the space, please reach out if you find this interesting — happy to connect and talk more :)I’m a Staff Data Engineer working on an Applied AI Research team building foundational time series models.If you’d like to follow my work work or get in touch head to my blog.ReferencesLeCun, Y., Cortes, C., & Burges, C. J. (2010). MNIST handwritten digit database. ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist or https://huggingface.co/datasets/ylecun/mnistThe MNIST dataset is used under the Creative Commons Attribution-Share Alike 3.0 license.Data Pruning MNIST: How I Hit 99% Accuracy Using Half the Data was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. data-science, machine-learning, data-engineering, neural-networks, ai Towards Data Science – MediumRead More

 Add to favorites
Add to favorites
0 Comments