
The hidden force behind AI is powering the next wave of business transformation
In a world that focuses more on data, business leaders must understand vector thinking. At first, vectors may appear as complicated as algebra was in school, but they serve as a fundamental building block. Vectors are as essential as algebra for tasks like sharing a bill or computing interest. They underpin our digital systems for decision making, customer engagement, and data protection.
They represent a radically different concept of relationships and patterns. They do not simply divide data into rigid categories. Instead, they offer a dynamic, multidimensional view of the underlying connections. Like “Similar” for two customers may mean more than demographics or purchase histories. It’s their behaviors, preferences, and habits that align distractingly. Such associations can be defined and measured accurately in a vector space. But for many modern businesses, the logic is too complex. So leaders tend to fall back in old, learned, rule-based patterns instead. And back then, fraud detection for example still used simple rules on transaction limits. We’ve evolved to recognize patterns and anomalies.
While it might have been common to block transactions that allocate 50% of your credit card limit at once just a few years ago, we are now able to analyze your retailer-specific spend history, look at average baskets of other customers at this very same retailers and do some slight logic checks such as the physical location of your previous spends.
So a $7,000 transaction for McDonald’s in Dubai might just not happen if you just spent $3 on bike rental in Amsterdam. Even $20 wouldn’t work since logical vector patterns can rule out the physical distance to be valid. Instead the $7,000 transaction for your new E-Bike at a retailer near the Amsterdam city center may just work flawlessly. Welcome to the insight of living in a world managed by vectors.
The danger of ignoring the paradigm of vectors is huge. Not mastering algebra can lead to bad financial decisions. Similarly, not knowing vectors can leave you vulnerable as a business leader. While the average customer may stay unaware of vectors as much as an average passenger in a plane is of aerodynamics, a business leader should be at least aware of what Kerosin is and how many seats are to be occupied to break even for a specific flight. You may not need to fully understand the systems you rely on. A basic understanding helps to know when to reach out to the experts. And this is exactly my aim in this little journey into the world of vectors: become aware of the basic principles and know when to ask for more to better steer and manage your business.
In the hushed hallways of research labs and tech companies, a revolution was brewing. It would change how computers understood the world. This revolution has nothing to do with processing power or storage capacity. It was all about teaching machines to understand context, meaning, and nuance in words. This uses mathematical representations called vectors. Before we can appreciate the magnitude of this shift, we first need to understand what it differs from.
Think about the way humans take in information. When we look at a cat, we don’t just process a checklist of components: whiskers, fur, four legs. Instead, our brains work through a network of relationships, contexts, and associations. We know a cat is more like a lion than a bicycle. It’s not from memorizing this fact. Our brains have naturally learned these relationships. It boils down to target_transform_sequence or equivalent. Vector representations let computers consume content in a human-like way. And we ought to understand how and why this is true. It’s as fundamental as knowing algebra in the time of an impending AI revolution.
In this brief jaunt in the vector realm, I will explain how vector-based computing works and why it’s so transformative. The code examples are only examples, so they are just for illustration and have no stand-alone functionality. You don’t have to be an engineer to understand those concepts. All you have to do is follow along, as I walk you through examples with plain language commentary explaining each one step by step, one step at a time. I don’t aim to be a world-class mathematician. I want to make vectors understandable to everyone: business leaders, managers, engineers, musicians, and others.
What are vectors, anyway?

It is not that the vector-based computing journey started recently. Its roots go back to the 1950s with the development of distributed representations in cognitive science. James McClelland and David Rumelhart, among other researchers, theorized that the brain holds concepts not as individual entities. Instead, it holds them as the compiled activity patterns of neural networks. This discovery dominated the path for contemporary vector representations.
The real breakthrough was three things coming together:
- The exponential growth in computational power,
- the development of sophisticated neural network architectures, and
- the availability of massive datasets for training.
It is the combination of these elements that makes vector-based systems theoretically possible and practically implementable at scale. AI as the mainstream of people got to know it (with the likes of chatGPT e.a.) is the direct consequence of this.
To better understand, let me put this in context: Conventional computing systems work on symbols — discrete, human-readable symbols and rules. A traditional system, for instance, might represent a customer as a record:
customer = {
'id': '12345',
'age': 34,
'purchase_history': ['electronics', 'books'],
'risk_level': 'low'
}
This representation may be readable or logical, but it misses subtle patterns and relationships. In contrast, vector representations encode information within high-dimensional space where relationships arise naturally through geometric proximity. That same customer might be represented as a 384-dimensional vector where each one of these dimensions contributes to a rich, nuanced profile. Simple code allows for 2-Dimensional customer data to be transformed into vectors. Let’s take a look at how simple this just is:
from sentence_transformers import SentenceTransformer
import numpy as np
class CustomerVectorization:
def __init__(self):
self.model = SentenceTransformer('all-MiniLM-L6-v2')
def create_customer_vector(self, customer_data):
"""
Transform customer data into a rich vector representation
that captures subtle patterns and relationships
"""
# Combine various customer attributes into a meaningful text representation
customer_text = f"""
Customer profile: {customer_data['age']} year old,
interested in {', '.join(customer_data['purchase_history'])},
risk level: {customer_data['risk_level']}
"""
# Generate base vector from text description
base_vector = self.model.encode(customer_text)
# Enrich vector with numerical features
numerical_features = np.array([
customer_data['age'] / 100, # Normalized age
len(customer_data['purchase_history']) / 10, # Purchase history length
self._risk_level_to_numeric(customer_data['risk_level'])
])
# Combine text-based and numerical features
combined_vector = np.concatenate([
base_vector,
numerical_features
])
return combined_vector
def _risk_level_to_numeric(self, risk_level):
"""Convert categorical risk level to normalized numeric value"""
risk_mapping = {'low': 0.1, 'medium': 0.5, 'high': 0.9}
return risk_mapping.get(risk_level.lower(), 0.5)
I trust that this code example has helped demonstrate how easy complex customer data can be encoded into meaningful vectors. The method seems complex at first. But, it is simple. We merge text and numerical data on customers. This gives us rich, info-dense vectors that capture each customer’s essence. What I love most about this technique is its simplicity and flexibility. Similarly to how we encoded age, purchase history, and risk levels here, you could replicate this pattern to capture any other customer attributes that boil down to the relevant base case for your use case. Just recall the credit card spending patterns we described earlier. It’s similar data being turned into vectors to have a meaning far greater than it could ever have it stayed 2-dimensional and would be used for traditional rule-based logics.
What our little code example allowed us to do, is having two very suggestive representations in one semantically rich space and one in normalized value space, mapping every record to a line in a graph that has direct comparison properties.
This allows the systems to identify complex patterns and relations that traditional data structures won’t be able to reflect adequately. With the geometric nature of vector spaces, the shape of these structures tells the stories of similarities, differences, and relationships, allowing for an inherently standardized yet flexible representation of complex data. But going from here, you will see this structure copied across other applications of vector-based customer analysis: use relevant data, aggregate it in a format we can work with, and meta representation combines heterogeneous data into a common understanding of vectors. Whether it’s recommendation systems, customer segmentation models, or predictive analytics tools, this fundamental approach to thoughtful vectorization will underpin all of it. Thus, this fundamental approach is significant to know and understand even if you consider yourself non-tech, more into the business side.
Just keep in mind — the key is considering what part of your data has meaningful signals and how to encode them in a way that preserves their relationships. It is nothing but following your business logic in another way of thinking other than algebra. A more modern, multi-dimensional way.
The Mathematics of Meaning (Kings and Queens)

All human communication delivers rich networks of meaning that our brains wire to make sense of automatically. These are meanings that we can capture mathematically, using vector-based computing; we can represent words in space so that they are points in a multi-dimensional word space. This geometrical treatment allows us to think in spatial terms about the abstract semantic relations we are interested in, as distances and directions.
For instance, this relationship “King is to Queen as Man is to Woman” is encoded in a vector space in such a way that the direction and distance between the words “King” and “Queen” are similar to those between the words “Man” and “Woman.”
Let’s take a step back to understand why this might be: the key component that makes this system work is word embeddings — numerical representations that encode words as vectors in a dense vector space. These embeddings are derived from examining co-occurrences of words across large snippets of text. Just as we learn that “dog” and “puppy” are related concepts by observing that they occur in similar contexts, embedding algorithms learn to embed these words close to each other in a vector space.
Word embeddings reveal their real power when we look at how they encode analogical relationships. Think about what we know about the relationship between “king” and “queen.” We can tell through intuition that these words are different in gender but share associations related to non-room of the palace, authority, and leadership. Through a wonderful property of vector space systems — vector arithmetic — this relationship can be captured mathematically.
One does this beautifully in the classic example:
vector('king') - vector('man') + vector('woman') ≈ vector('queen')
This equation tells us that if we have the vector for “king,” and we subtract out the “man” vector (we remove the concept of “male”), and then we add the “woman” vector (we add the concept of “female”), we get a new point in space very close to that of “queen.” That’s not some mathematical coincidence — it’s based on how the embedding space has arranged the meaning in a sort of structured way.
We can apply this idea of context in Python with pre-trained word embeddings:
import gensim.downloader as api
# Load a pre-trained model that contains word vectors learned from Google News
model = api.load('word2vec-google-news-300')
# Define our analogy words
source_pair = ('king', 'man')
target_word = 'woman'
# Find which word completes the analogy using vector arithmetic
result = model.most_similar(
positive=[target_word, source_pair[0]],
negative=[source_pair[1]],
topn=1
)
# Display the result
print(f"{source_pair[0]} is to {source_pair[1]} as {target_word} is to {result[0][0]}")
The structure of this vector space exposes many basic principles:
- Semantic similarity is present as spatial proximity. Related words congregate: the neighborhoods of ideas. “Dog,” “puppy,” and “canine” would be one such cluster; meanwhile, “cat,” “kitten,” and “feline” would create another cluster nearby.
- Relationships between words become directions in the space. The vector from “man” to “woman” encodes a gender relationship, and other such relationships (for example, “king” to “queen” or “actor” to “actress”) typically point in the same direction.
- The magnitude of vectors can carry meaning about word importance or specificity. Common words often have shorter vectors than specialized terms, reflecting their broader, less specific meanings.
Working with relationships between words in this way gave us a geometric encoding of meaning and the mathematical precision needed to reflect the nuances of natural language processing to machines. Instead of treating words as separate symbols, vector-like systems can recognize patterns, make analogies, and even uncover relationships that were never programmed.
To better grasp what was just discussed I took the liberty to have the words we mentioned before (“King, Man, Women”; “Dog, Puppy, Canine”; “Cat, Kitten, Feline”) mapped to a corresponding 2D vector. These vectors numerically represent semantic meaning.
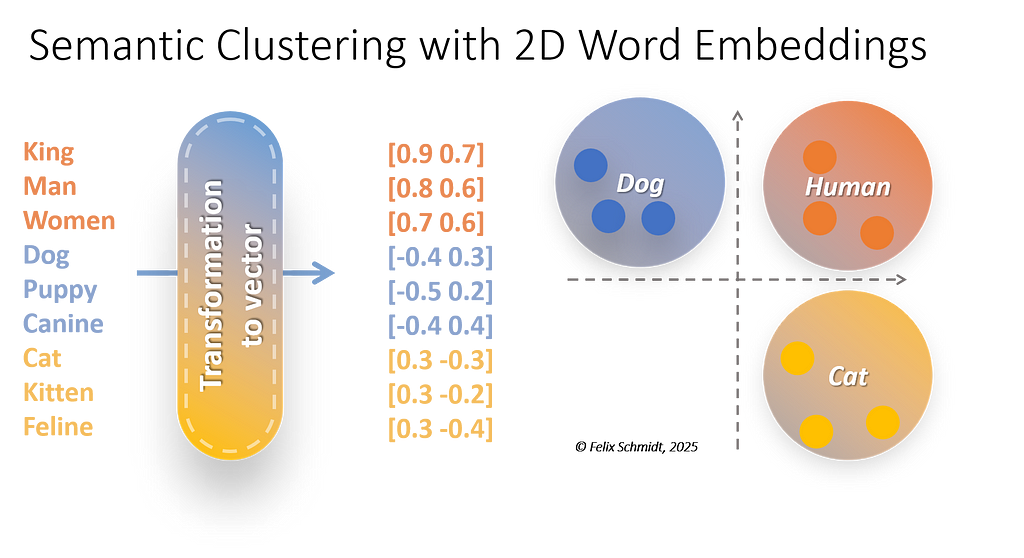
- Human-related words have high positive values on both dimensions.
- Dog-related words have negative x-values and positive y-values.
- Cat-related words have positive x-values and negative y-values.
Be aware, those values are fabricated by me to illustrate better. As shown in the 2D Space where the vectors are plotted, you can observe groups based on the positions of the dots representing the vectors. The three Dog-related words e.g. can be clustered as the “Dog” category etc. etc.
Grasping these basic principles gives us insight into both the capabilities and limitations of modern language AI, such as large language models (LLMs). Though these systems can do amazing analogical and relational gymnastics, they are ultimately cycles of geometric patterns based on the ways that words appear in proximity to one another in a body of text. An elaborate but, by definition, partial reflection of human linguistic comprehension. As such an LLM, since based on vectors, can only generate as output what it has received as input. Although that doesn’t mean it 1:1 generates only what it has been trained, we all know about the fantastic hallucination capabilities of llms, it means that LLMs, unless specifically instructed, wouldn’t come up with neologist words or new language to describe things. This basic understanding is still lacking for a lot of business leaders that expect LLMs to be miracle machines unknowledgeable about the underlying principles of vectors.
A Tale of Distances, Angles, and Dinner Parties

Now, let’s assume you’re throwing a dinner party and it’s all about Hollywood and the big movies, and you want to seat people based on what they like. You could just calculate “distance” between their preferences (genres, perhaps even hobbies?) and find out who should sit together. But deciding how you measure that distance can be the difference between compelling conversations and annoyed participants. Or awkward silences.
And yes, that company party flashback is repeating itself. Sorry for that!
The same is true in the world of vectors. The distance metric defines how “similar” two vectors look, and therefore, ultimately, how well your system performs to predict an outcome.
Euclidean Distance: Straightforward, but Limited
Euclidean distance measures the straight-line distance between two points in space, making it easy to understand:
- Euclidean distance is fine as long as vectors are physical locations.
- However, in high-dimensional spaces (like vectors representing user behavior or preferences), this metric often falls short. Differences in scale or magnitude can skew results, focusing on scale over actual similarity.
Example: Two vectors might represent your dinner guest’s preferences for how much streaming services are used:
vec1 = [5, 10, 5]
# Dinner guest A likes action, drama, and comedy as genres equally.
vec2 = [1, 2, 1]
# Dinner guest B likes the same genres but consumes less streaming overall.
While their preferences align, Euclidean distance would make them seem vastly different because of the disparity in overall activity.
But in higher-dimensional spaces, such as user behavior or textual meaning, Euclidean distance becomes increasingly less informative. It overweights magnitude, which can obscure comparisons. Consider two moviegoers: one has seen 200 action movies, the other has seen 10, but they both like the same genres. Because of their sheer activity level, the second viewer would appear much less similar to the first when using Euclidean distance though all they ever watched is Bruce Willis movies.
Cosine Similarity: Focused on Direction
The cosine similarity method takes a different approach. It focuses on the angle between vectors, not their magnitudes. It’s like comparing the path of two arrows. If they point the same way, they are aligned, no matter their lengths. This shows that it’s perfect for high-dimensional data, where we care about relationships, not scale.
- If two vectors point in the same direction, they’re considered similar (cosine similarity approx of 1).
- When opposing (so pointing in opposite directions), they differ (cosine similarity ≈ -1).
- If they’re perpendicular (at a right angle of 90° to one another), they are unrelated (cosine similarity close to 0).
This normalizing property ensures that the similarity score correctly measures alignment, regardless of how one vector is scaled in comparison to another.
Example: Returning to our streaming preferences, let’s take a look at how our dinner guest’s preferences would look like as vectors:
vec1 = [5, 10, 5]
# Dinner guest A likes action, drama, and comedy as genres equally.
vec2 = [1, 2, 1]
# Dinner guest B likes the same genres but consumes less streaming overall.
Let us discuss why cosine similarity is really effective in this case. So, when we compute cosine similarity for vec1 [5, 10, 5] and vec2 [1, 2, 1], we’re essentially trying to see the angle between these vectors.
The dot product normalizes the vectors first, dividing each component by the length of the vector. This operation “cancels” the differences in magnitude:
- So for vec1: Normalization gives us [0.41, 0.82, 0.41] or so.
- For vec2: Which resolves to [0.41, 0.82, 0.41] after normalization we will also have it.
And now we also understand why these vectors would be considered identical with regard to cosine similarity because their normalized versions are identical!
This tells us that even though dinner guest A views more total content, the proportion they allocate to any given genre perfectly mirrors dinner guest B’s preferences. It’s like saying both your guests dedicate 20% of their time to action, 60% to drama, and 20% to comedy, no matter the total hours viewed.
It’s this normalization that makes cosine similarity particularly effective for high-dimensional data such as text embeddings or user preferences.
When dealing with data of many dimensions (think hundreds or thousands of components of a vector for various features of a movie), it is often the relative significance of each dimension corresponding to the complete profile rather than the absolute values that matter most. Cosine similarity identifies precisely this arrangement of relative importance and is a powerful tool to identify meaningful relationships in complex data.
Hiking up the Euclidian Mountain Trail

In this part, we will see how different approaches to measuring similarity behave in practice, with a concrete example from the real world and some little code example. Even if you are a non-techie, the code will be easy to understand for you as well. It’s to illustrate the simplicity of it all. No fear!
How about we quickly discuss a 10-mile-long hiking trail? Two friends, Alex and Blake, write trail reviews of the same hike, but each ascribes it a different character:
The trail gained 2,000 feet in elevation over just 2 miles! Easily doable with some high spikes in between!
Alex
and
Beware, we hiked 100 straight feet up in the forest terrain at the spike! Overall, 10 beautiful miles of forest!
Blake
These descriptions can be represented as vectors:
alex_description = [2000, 2] # [elevation_gain, trail_distance]
blake_description = [100, 10] # [elevation_gain, trail_distance]
Let’s combine both similarity measures and see what it tells us:
import numpy as np
def cosine_similarity(vec1, vec2):
"""
Measures how similar the pattern or shape of two descriptions is,
ignoring differences in scale. Returns 1.0 for perfectly aligned patterns.
"""
dot_product = np.dot(vec1, vec2)
norm1 = np.linalg.norm(vec1)
norm2 = np.linalg.norm(vec2)
return dot_product / (norm1 * norm2)
def euclidean_distance(vec1, vec2):
"""
Measures the direct 'as-the-crow-flies' difference between descriptions.
Smaller numbers mean descriptions are more similar.
"""
return np.linalg.norm(np.array(vec1) - np.array(vec2))
# Alex focuses on the steep part: 2000ft elevation over 2 miles
alex_description = [2000, 2] # [elevation_gain, trail_distance]
# Blake describes the whole trail: 100ft average elevation per mile over 10 miles
blake_description = [100, 10] # [elevation_gain, trail_distance]
# Let's see how different these descriptions appear using each measure
print("Comparing how Alex and Blake described the same trail:")
print("nEuclidean distance:", euclidean_distance(alex_description, blake_description))
print("(A larger number here suggests very different descriptions)")
print("nCosine similarity:", cosine_similarity(alex_description, blake_description))
print("(A number close to 1.0 suggests similar patterns)")
# Let's also normalize the vectors to see what cosine similarity is looking at
alex_normalized = alex_description / np.linalg.norm(alex_description)
blake_normalized = blake_description / np.linalg.norm(blake_description)
print("nAlex's normalized description:", alex_normalized)
print("Blake's normalized description:", blake_normalized)
So now, running this code, something magical happens:
Comparing how Alex and Blake described the same trail:
Euclidean distance: 8.124038404635959
(A larger number here suggests very different descriptions)
Cosine similarity: 0.9486832980505138
(A number close to 1.0 suggests similar patterns)
Alex's normalized description: [0.99975 0.02236]
Blake's normalized description: [0.99503 0.09950]
This output shows why, depending on what you are measuring, the same trail may appear different or similar.
The large Euclidean distance (8.12) suggests these are very different descriptions. It’s understandable that 2000 is a lot different from 100, and 2 is a lot different from 10. It’s like taking the raw difference between these numbers without understanding their meaning.
But the high Cosine similarity (0.95) tells us something more interesting: both descriptions capture a similar pattern.
If we look at the normalized vectors, we can see it, too; both Alex and Blake are describing a trail in which elevation gain is the prominent feature. The first number in each normalized vector (elevation gain) is much larger relative to the second (trail distance). Either that or elevating them both and normalizing based on proportion — not volume — since they both share the same trait defining the trail.
Perfectly true to life: Alex and Blake hiked the same trail but focused on different parts of it when writing their review. Alex focused on the steeper section and described a 100-foot climb, and Blake described the profile of the entire trail, averaged to 200 feet per mile over 10 miles. Cosine similarity identifies these descriptions as variations of the same basic trail pattern, whereas Euclidean distance regards them as completely different trails.
This example highlights the need to select the appropriate similarity measure. Normalizing and taking cosine similarity gives many meaningful correlations that are missed by just taking distances like Euclidean in real use cases.
Real-World Impacts of Metric Choices

The metric you pick doesn’t merely change the numbers; it influences the results of complex systems. Here’s how it breaks down in various domains:
- In Recommendation Engines: When it comes to cosine similarity, we can group users who have the same tastes, even if they are doing different amounts of overall activity. A streaming service could use this to recommend movies that align with a user’s genre preferences, regardless of what is popular among a small subset of very active viewers.
- In Document Retrieval: When querying a database of documents or research papers, cosine similarity ranks documents according to whether their content is similar in meaning to the user’s query, rather than their text length. This enables systems to retrieve results that are contextually relevant to the query, even though the documents are of a wide range of sizes.
- In Fraud Detection: Patterns of behavior are often more important than pure numbers. Cosine similarity can be used to detect anomalies in spending habits, as it compares the direction of the transaction vectors — type of merchant, time of day, transaction amount, etc. — rather than the absolute magnitude.
And these differences matter because they give a sense of how systems “think”. Let’s get back to that credit card example one more time: It might, for example, identify a high-value $7,000 transaction for you new E-Bike as suspicious using Euclidean distance — even if that transaction is normal for you given you have an average spent of $20,000 a month. A cosine-based system, on the other hand, understands that the transaction is consistent with what the user typically spends their money on, thus avoiding unnecessary false notifications.
But measures like Euclidean distance and cosine similarity are not merely theoretical. They’re the blueprints on which real-world systems stand. Whether it’s recommendation engines or fraud detection, the metrics we choose will directly impact how systems make sense of relationships in data.
Vector Representations in Practice: Industry Transformations

This ability for abstraction is what makes vector representations so powerful — they transform complex and abstract field data into concepts that can be scored and actioned. These insights are catalyzing fundamental transformations in business processes, decision-making, and customer value delivery across sectors.
Next, we will explore the solution use cases we are highlighting as concrete examples to see how vectors are freeing up time to solve big problems and creating new opportunities that have a big impact. I picked an industry to show what vector-based approaches to a challenge can achieve, so here is a healthcare example from a clinical setting. Why? Because it matters to us all and is rather easy to relate to than digging into the depths of the finance system, insurances, renewable energies or chemistry.
Spotlight Healthcare: Pattern Recognition in Complex Medical Data
The healthcare industry poses a perfect storm of challenges that vector representations can uniquely solve. Think of the complexities of patient data: medical histories, genetic information, lifestyle factors, and treatment outcomes all interact in nuanced ways that traditional rule-based systems are incapable of capturing.
At Massachusetts General Hospital, researchers implemented a vector-based early detection system for sepsis, a condition in which every hour of early detection increases the chances of survival by 7.6% (see the full study at pmc.ncbi.nlm.nih.gov/articles/PMC6166236/).
In this new methodology, spontaneous neutrophil velocity profiles (SVP) are used to describe the movement patterns of neutrophils from a drop of blood. We won’t get too medically detailed here, because we’re vector-focused today, but a neutrophil is an immune cell that is kind of a first responder in what the body uses to fight off infections.
The system then encodes each neutrophil’s motion as a vector that captures not just its magnitude (i.e., speed), but also its direction. So they converted biological patterns to high-dimensional vector spaces; thus, they got subtle differences and showed that healthy individuals and sepsis patients exhibited statistically significant differences in movement. Then, these numeric vectors were processed with the help of a machine learning model that was trained to detect early signs of sepsis. The result was a diagnostic tool that reached impressive sensitivity (97%) and specificity (98%) to achieve a rapid and accurate identification of this fatal condition. Probably with cosine similarity (the paper doesn’t go into much detail, so this is pure speculation, but it would be the most suitable) that we just learned about a moment ago.
This is just one example of how medical data can be encoded into its vector representations and turned into malleable, actionable insights. This approach made it possible to re-contextualize complex relationships and, along with tread-based machine learning, worked around the limitations of previous diagnostic modalities and proved to be a potent tool for clinicians to save lives. It’s a powerful reminder that vectors aren’t merely theoretical constructs — they’re practical, life-saving solutions that are powering the future of healthcare as much as your credit card risk detection software and hopefully also your business.
Lead and understand, or face disruption. The naked truth.

With all you have read about by now: Think of a decision as small as the decision about the metrics under which data relationships are evaluated. Leaders risk making assumptions that are subtle yet disastrous. You are basically using algebra as a tool, and while getting some result, you cannot know if it is right or not: doing leadership decisions without understanding the fundamentals of vectors is like calculating using a calculator but not knowing what formulas you are using.
The good news is this doesn’t mean that business leaders have to become data scientists. Vectors are delightful because, once the core ideas have been grasped, they become very easy to work with. An understanding of a handful of concepts (for example, how vectors encode relationships, why distance metrics are important, and how embedding models function) can fundamentally change how you make high-level decisions. These tools will help you ask better questions, work with technical teams more effectively, and make sound decisions about the systems that will govern your business.
The returns on this small investment in comprehension are huge. There is much talk about personalization. Yet, few organizations use vector-based thinking in their business strategies. It could help them leverage personalization to its full potential. Such an approach would delight customers with tailored experiences and build loyalty. You could innovate in areas like fraud detection and operational efficiency, leveraging subtle patterns in data that traditional ones miss — or perhaps even save lives, as described above. Equally important, you can avoid expensive missteps that happen when leaders defer to others for key decisions without understanding what they mean.
The truth is, vectors are here now, driving a vast majority of all the hyped AI technology behind the scenes to help create the world we navigate in today and tomorrow. Companies that do not adapt their leadership to think in vectors risk falling behind a competitive landscape that becomes ever more data-driven. One who adopts this new paradigm will not just survive but will prosper in an age of never-ending AI innovation.
Now is the moment to act. Start to view the world through vectors. Study their tongue, examine their doctrine, and ask how the new could change your tactics and your lodestars. Much in the way that algebra became an essential tool for writing one’s way through practical life challenges, vectors will soon serve as the literacy of the data age. Actually they do already. It is the future of which the powerful know how to take control. The question is not if vectors will define the next era of businesses; it is whether you are prepared to lead it.
The Invisible Revolution: How Vectors Are (Re)defining Business Success was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
The hidden force behind AI is powering the next wave of business transformationA human brain containing vectors and code. By Felix SchmidtIn a world that focuses more on data, business leaders must understand vector thinking. At first, vectors may appear as complicated as algebra was in school, but they serve as a fundamental building block. Vectors are as essential as algebra for tasks like sharing a bill or computing interest. They underpin our digital systems for decision making, customer engagement, and data protection.They represent a radically different concept of relationships and patterns. They do not simply divide data into rigid categories. Instead, they offer a dynamic, multidimensional view of the underlying connections. Like “Similar” for two customers may mean more than demographics or purchase histories. It’s their behaviors, preferences, and habits that align distractingly. Such associations can be defined and measured accurately in a vector space. But for many modern businesses, the logic is too complex. So leaders tend to fall back in old, learned, rule-based patterns instead. And back then, fraud detection for example still used simple rules on transaction limits. We’ve evolved to recognize patterns and anomalies.While it might have been common to block transactions that allocate 50% of your credit card limit at once just a few years ago, we are now able to analyze your retailer-specific spend history, look at average baskets of other customers at this very same retailers and do some slight logic checks such as the physical location of your previous spends.So a $7,000 transaction for McDonald’s in Dubai might just not happen if you just spent $3 on bike rental in Amsterdam. Even $20 wouldn’t work since logical vector patterns can rule out the physical distance to be valid. Instead the $7,000 transaction for your new E-Bike at a retailer near the Amsterdam city center may just work flawlessly. Welcome to the insight of living in a world managed by vectors.The danger of ignoring the paradigm of vectors is huge. Not mastering algebra can lead to bad financial decisions. Similarly, not knowing vectors can leave you vulnerable as a business leader. While the average customer may stay unaware of vectors as much as an average passenger in a plane is of aerodynamics, a business leader should be at least aware of what Kerosin is and how many seats are to be occupied to break even for a specific flight. You may not need to fully understand the systems you rely on. A basic understanding helps to know when to reach out to the experts. And this is exactly my aim in this little journey into the world of vectors: become aware of the basic principles and know when to ask for more to better steer and manage your business.In the hushed hallways of research labs and tech companies, a revolution was brewing. It would change how computers understood the world. This revolution has nothing to do with processing power or storage capacity. It was all about teaching machines to understand context, meaning, and nuance in words. This uses mathematical representations called vectors. Before we can appreciate the magnitude of this shift, we first need to understand what it differs from.Think about the way humans take in information. When we look at a cat, we don’t just process a checklist of components: whiskers, fur, four legs. Instead, our brains work through a network of relationships, contexts, and associations. We know a cat is more like a lion than a bicycle. It’s not from memorizing this fact. Our brains have naturally learned these relationships. It boils down to target_transform_sequence or equivalent. Vector representations let computers consume content in a human-like way. And we ought to understand how and why this is true. It’s as fundamental as knowing algebra in the time of an impending AI revolution.In this brief jaunt in the vector realm, I will explain how vector-based computing works and why it’s so transformative. The code examples are only examples, so they are just for illustration and have no stand-alone functionality. You don’t have to be an engineer to understand those concepts. All you have to do is follow along, as I walk you through examples with plain language commentary explaining each one step by step, one step at a time. I don’t aim to be a world-class mathematician. I want to make vectors understandable to everyone: business leaders, managers, engineers, musicians, and others.What are vectors, anyway?Photo by Pete F on UnsplashIt is not that the vector-based computing journey started recently. Its roots go back to the 1950s with the development of distributed representations in cognitive science. James McClelland and David Rumelhart, among other researchers, theorized that the brain holds concepts not as individual entities. Instead, it holds them as the compiled activity patterns of neural networks. This discovery dominated the path for contemporary vector representations.The real breakthrough was three things coming together:The exponential growth in computational power,the development of sophisticated neural network architectures, andthe availability of massive datasets for training.It is the combination of these elements that makes vector-based systems theoretically possible and practically implementable at scale. AI as the mainstream of people got to know it (with the likes of chatGPT e.a.) is the direct consequence of this.To better understand, let me put this in context: Conventional computing systems work on symbols — discrete, human-readable symbols and rules. A traditional system, for instance, might represent a customer as a record:customer = { ‘id’: ‘12345’, ‘age’: 34, ‘purchase_history’: [‘electronics’, ‘books’], ‘risk_level’: ‘low’}This representation may be readable or logical, but it misses subtle patterns and relationships. In contrast, vector representations encode information within high-dimensional space where relationships arise naturally through geometric proximity. That same customer might be represented as a 384-dimensional vector where each one of these dimensions contributes to a rich, nuanced profile. Simple code allows for 2-Dimensional customer data to be transformed into vectors. Let’s take a look at how simple this just is:from sentence_transformers import SentenceTransformerimport numpy as npclass CustomerVectorization: def __init__(self): self.model = SentenceTransformer(‘all-MiniLM-L6-v2’) def create_customer_vector(self, customer_data): “”” Transform customer data into a rich vector representation that captures subtle patterns and relationships “”” # Combine various customer attributes into a meaningful text representation customer_text = f””” Customer profile: {customer_data[‘age’]} year old, interested in {‘, ‘.join(customer_data[‘purchase_history’])}, risk level: {customer_data[‘risk_level’]} “”” # Generate base vector from text description base_vector = self.model.encode(customer_text) # Enrich vector with numerical features numerical_features = np.array([ customer_data[‘age’] / 100, # Normalized age len(customer_data[‘purchase_history’]) / 10, # Purchase history length self._risk_level_to_numeric(customer_data[‘risk_level’]) ]) # Combine text-based and numerical features combined_vector = np.concatenate([ base_vector, numerical_features ]) return combined_vector def _risk_level_to_numeric(self, risk_level): “””Convert categorical risk level to normalized numeric value””” risk_mapping = {‘low’: 0.1, ‘medium’: 0.5, ‘high’: 0.9} return risk_mapping.get(risk_level.lower(), 0.5)I trust that this code example has helped demonstrate how easy complex customer data can be encoded into meaningful vectors. The method seems complex at first. But, it is simple. We merge text and numerical data on customers. This gives us rich, info-dense vectors that capture each customer’s essence. What I love most about this technique is its simplicity and flexibility. Similarly to how we encoded age, purchase history, and risk levels here, you could replicate this pattern to capture any other customer attributes that boil down to the relevant base case for your use case. Just recall the credit card spending patterns we described earlier. It’s similar data being turned into vectors to have a meaning far greater than it could ever have it stayed 2-dimensional and would be used for traditional rule-based logics.What our little code example allowed us to do, is having two very suggestive representations in one semantically rich space and one in normalized value space, mapping every record to a line in a graph that has direct comparison properties.This allows the systems to identify complex patterns and relations that traditional data structures won’t be able to reflect adequately. With the geometric nature of vector spaces, the shape of these structures tells the stories of similarities, differences, and relationships, allowing for an inherently standardized yet flexible representation of complex data. But going from here, you will see this structure copied across other applications of vector-based customer analysis: use relevant data, aggregate it in a format we can work with, and meta representation combines heterogeneous data into a common understanding of vectors. Whether it’s recommendation systems, customer segmentation models, or predictive analytics tools, this fundamental approach to thoughtful vectorization will underpin all of it. Thus, this fundamental approach is significant to know and understand even if you consider yourself non-tech, more into the business side.Just keep in mind — the key is considering what part of your data has meaningful signals and how to encode them in a way that preserves their relationships. It is nothing but following your business logic in another way of thinking other than algebra. A more modern, multi-dimensional way.The Mathematics of Meaning (Kings and Queens)Photo by Debbie Fan on UnsplashAll human communication delivers rich networks of meaning that our brains wire to make sense of automatically. These are meanings that we can capture mathematically, using vector-based computing; we can represent words in space so that they are points in a multi-dimensional word space. This geometrical treatment allows us to think in spatial terms about the abstract semantic relations we are interested in, as distances and directions.For instance, this relationship “King is to Queen as Man is to Woman” is encoded in a vector space in such a way that the direction and distance between the words “King” and “Queen” are similar to those between the words “Man” and “Woman.”Let’s take a step back to understand why this might be: the key component that makes this system work is word embeddings — numerical representations that encode words as vectors in a dense vector space. These embeddings are derived from examining co-occurrences of words across large snippets of text. Just as we learn that “dog” and “puppy” are related concepts by observing that they occur in similar contexts, embedding algorithms learn to embed these words close to each other in a vector space.Word embeddings reveal their real power when we look at how they encode analogical relationships. Think about what we know about the relationship between “king” and “queen.” We can tell through intuition that these words are different in gender but share associations related to non-room of the palace, authority, and leadership. Through a wonderful property of vector space systems — vector arithmetic — this relationship can be captured mathematically.One does this beautifully in the classic example:vector(‘king’) – vector(‘man’) + vector(‘woman’) ≈ vector(‘queen’)This equation tells us that if we have the vector for “king,” and we subtract out the “man” vector (we remove the concept of “male”), and then we add the “woman” vector (we add the concept of “female”), we get a new point in space very close to that of “queen.” That’s not some mathematical coincidence — it’s based on how the embedding space has arranged the meaning in a sort of structured way.We can apply this idea of context in Python with pre-trained word embeddings:import gensim.downloader as api# Load a pre-trained model that contains word vectors learned from Google Newsmodel = api.load(‘word2vec-google-news-300’)# Define our analogy wordssource_pair = (‘king’, ‘man’)target_word = ‘woman’# Find which word completes the analogy using vector arithmeticresult = model.most_similar( positive=[target_word, source_pair[0]], negative=[source_pair[1]], topn=1)# Display the resultprint(f”{source_pair[0]} is to {source_pair[1]} as {target_word} is to {result[0][0]}”)The structure of this vector space exposes many basic principles:Semantic similarity is present as spatial proximity. Related words congregate: the neighborhoods of ideas. “Dog,” “puppy,” and “canine” would be one such cluster; meanwhile, “cat,” “kitten,” and “feline” would create another cluster nearby.Relationships between words become directions in the space. The vector from “man” to “woman” encodes a gender relationship, and other such relationships (for example, “king” to “queen” or “actor” to “actress”) typically point in the same direction.The magnitude of vectors can carry meaning about word importance or specificity. Common words often have shorter vectors than specialized terms, reflecting their broader, less specific meanings.Working with relationships between words in this way gave us a geometric encoding of meaning and the mathematical precision needed to reflect the nuances of natural language processing to machines. Instead of treating words as separate symbols, vector-like systems can recognize patterns, make analogies, and even uncover relationships that were never programmed.To better grasp what was just discussed I took the liberty to have the words we mentioned before (“King, Man, Women”; “Dog, Puppy, Canine”; “Cat, Kitten, Feline”) mapped to a corresponding 2D vector. These vectors numerically represent semantic meaning.Visualization of the before-mentioned example terms as 2D word embeddings. Showing grouped categories for explanatory purposes. Data is fabricated and axes are simplified for educational purposes.Human-related words have high positive values on both dimensions.Dog-related words have negative x-values and positive y-values.Cat-related words have positive x-values and negative y-values.Be aware, those values are fabricated by me to illustrate better. As shown in the 2D Space where the vectors are plotted, you can observe groups based on the positions of the dots representing the vectors. The three Dog-related words e.g. can be clustered as the “Dog” category etc. etc.Grasping these basic principles gives us insight into both the capabilities and limitations of modern language AI, such as large language models (LLMs). Though these systems can do amazing analogical and relational gymnastics, they are ultimately cycles of geometric patterns based on the ways that words appear in proximity to one another in a body of text. An elaborate but, by definition, partial reflection of human linguistic comprehension. As such an LLM, since based on vectors, can only generate as output what it has received as input. Although that doesn’t mean it 1:1 generates only what it has been trained, we all know about the fantastic hallucination capabilities of llms, it means that LLMs, unless specifically instructed, wouldn’t come up with neologist words or new language to describe things. This basic understanding is still lacking for a lot of business leaders that expect LLMs to be miracle machines unknowledgeable about the underlying principles of vectors.A Tale of Distances, Angles, and Dinner PartiesPhoto by OurWhisky Foundation on UnsplashNow, let’s assume you’re throwing a dinner party and it’s all about Hollywood and the big movies, and you want to seat people based on what they like. You could just calculate “distance” between their preferences (genres, perhaps even hobbies?) and find out who should sit together. But deciding how you measure that distance can be the difference between compelling conversations and annoyed participants. Or awkward silences. And yes, that company party flashback is repeating itself. Sorry for that!The same is true in the world of vectors. The distance metric defines how “similar” two vectors look, and therefore, ultimately, how well your system performs to predict an outcome.Euclidean Distance: Straightforward, but LimitedEuclidean distance measures the straight-line distance between two points in space, making it easy to understand:Euclidean distance is fine as long as vectors are physical locations.However, in high-dimensional spaces (like vectors representing user behavior or preferences), this metric often falls short. Differences in scale or magnitude can skew results, focusing on scale over actual similarity.Example: Two vectors might represent your dinner guest’s preferences for how much streaming services are used:vec1 = [5, 10, 5]# Dinner guest A likes action, drama, and comedy as genres equally.vec2 = [1, 2, 1] # Dinner guest B likes the same genres but consumes less streaming overall.While their preferences align, Euclidean distance would make them seem vastly different because of the disparity in overall activity.But in higher-dimensional spaces, such as user behavior or textual meaning, Euclidean distance becomes increasingly less informative. It overweights magnitude, which can obscure comparisons. Consider two moviegoers: one has seen 200 action movies, the other has seen 10, but they both like the same genres. Because of their sheer activity level, the second viewer would appear much less similar to the first when using Euclidean distance though all they ever watched is Bruce Willis movies.Cosine Similarity: Focused on DirectionThe cosine similarity method takes a different approach. It focuses on the angle between vectors, not their magnitudes. It’s like comparing the path of two arrows. If they point the same way, they are aligned, no matter their lengths. This shows that it’s perfect for high-dimensional data, where we care about relationships, not scale.If two vectors point in the same direction, they’re considered similar (cosine similarity approx of 1).When opposing (so pointing in opposite directions), they differ (cosine similarity ≈ -1).If they’re perpendicular (at a right angle of 90° to one another), they are unrelated (cosine similarity close to 0).This normalizing property ensures that the similarity score correctly measures alignment, regardless of how one vector is scaled in comparison to another.Example: Returning to our streaming preferences, let’s take a look at how our dinner guest’s preferences would look like as vectors:vec1 = [5, 10, 5]# Dinner guest A likes action, drama, and comedy as genres equally.vec2 = [1, 2, 1] # Dinner guest B likes the same genres but consumes less streaming overall.Let us discuss why cosine similarity is really effective in this case. So, when we compute cosine similarity for vec1 [5, 10, 5] and vec2 [1, 2, 1], we’re essentially trying to see the angle between these vectors.The dot product normalizes the vectors first, dividing each component by the length of the vector. This operation “cancels” the differences in magnitude:So for vec1: Normalization gives us [0.41, 0.82, 0.41] or so.For vec2: Which resolves to [0.41, 0.82, 0.41] after normalization we will also have it.And now we also understand why these vectors would be considered identical with regard to cosine similarity because their normalized versions are identical!This tells us that even though dinner guest A views more total content, the proportion they allocate to any given genre perfectly mirrors dinner guest B’s preferences. It’s like saying both your guests dedicate 20% of their time to action, 60% to drama, and 20% to comedy, no matter the total hours viewed.It’s this normalization that makes cosine similarity particularly effective for high-dimensional data such as text embeddings or user preferences.When dealing with data of many dimensions (think hundreds or thousands of components of a vector for various features of a movie), it is often the relative significance of each dimension corresponding to the complete profile rather than the absolute values that matter most. Cosine similarity identifies precisely this arrangement of relative importance and is a powerful tool to identify meaningful relationships in complex data.Hiking up the Euclidian Mountain TrailPhoto by Christian Mikhael on UnsplashIn this part, we will see how different approaches to measuring similarity behave in practice, with a concrete example from the real world and some little code example. Even if you are a non-techie, the code will be easy to understand for you as well. It’s to illustrate the simplicity of it all. No fear!How about we quickly discuss a 10-mile-long hiking trail? Two friends, Alex and Blake, write trail reviews of the same hike, but each ascribes it a different character:The trail gained 2,000 feet in elevation over just 2 miles! Easily doable with some high spikes in between!AlexandBeware, we hiked 100 straight feet up in the forest terrain at the spike! Overall, 10 beautiful miles of forest!BlakeThese descriptions can be represented as vectors:alex_description = [2000, 2] # [elevation_gain, trail_distance]blake_description = [100, 10] # [elevation_gain, trail_distance]Let’s combine both similarity measures and see what it tells us:import numpy as npdef cosine_similarity(vec1, vec2): “”” Measures how similar the pattern or shape of two descriptions is, ignoring differences in scale. Returns 1.0 for perfectly aligned patterns. “”” dot_product = np.dot(vec1, vec2) norm1 = np.linalg.norm(vec1) norm2 = np.linalg.norm(vec2) return dot_product / (norm1 * norm2)def euclidean_distance(vec1, vec2): “”” Measures the direct ‘as-the-crow-flies’ difference between descriptions. Smaller numbers mean descriptions are more similar. “”” return np.linalg.norm(np.array(vec1) – np.array(vec2))# Alex focuses on the steep part: 2000ft elevation over 2 milesalex_description = [2000, 2] # [elevation_gain, trail_distance]# Blake describes the whole trail: 100ft average elevation per mile over 10 milesblake_description = [100, 10] # [elevation_gain, trail_distance]# Let’s see how different these descriptions appear using each measureprint(“Comparing how Alex and Blake described the same trail:”)print(“nEuclidean distance:”, euclidean_distance(alex_description, blake_description))print(“(A larger number here suggests very different descriptions)”)print(“nCosine similarity:”, cosine_similarity(alex_description, blake_description))print(“(A number close to 1.0 suggests similar patterns)”)# Let’s also normalize the vectors to see what cosine similarity is looking atalex_normalized = alex_description / np.linalg.norm(alex_description)blake_normalized = blake_description / np.linalg.norm(blake_description)print(“nAlex’s normalized description:”, alex_normalized)print(“Blake’s normalized description:”, blake_normalized)So now, running this code, something magical happens:Comparing how Alex and Blake described the same trail:Euclidean distance: 8.124038404635959(A larger number here suggests very different descriptions)Cosine similarity: 0.9486832980505138(A number close to 1.0 suggests similar patterns)Alex’s normalized description: [0.99975 0.02236]Blake’s normalized description: [0.99503 0.09950]This output shows why, depending on what you are measuring, the same trail may appear different or similar.The large Euclidean distance (8.12) suggests these are very different descriptions. It’s understandable that 2000 is a lot different from 100, and 2 is a lot different from 10. It’s like taking the raw difference between these numbers without understanding their meaning.But the high Cosine similarity (0.95) tells us something more interesting: both descriptions capture a similar pattern.If we look at the normalized vectors, we can see it, too; both Alex and Blake are describing a trail in which elevation gain is the prominent feature. The first number in each normalized vector (elevation gain) is much larger relative to the second (trail distance). Either that or elevating them both and normalizing based on proportion — not volume — since they both share the same trait defining the trail.Perfectly true to life: Alex and Blake hiked the same trail but focused on different parts of it when writing their review. Alex focused on the steeper section and described a 100-foot climb, and Blake described the profile of the entire trail, averaged to 200 feet per mile over 10 miles. Cosine similarity identifies these descriptions as variations of the same basic trail pattern, whereas Euclidean distance regards them as completely different trails.This example highlights the need to select the appropriate similarity measure. Normalizing and taking cosine similarity gives many meaningful correlations that are missed by just taking distances like Euclidean in real use cases.Real-World Impacts of Metric ChoicesPhoto by fabio on UnsplashThe metric you pick doesn’t merely change the numbers; it influences the results of complex systems. Here’s how it breaks down in various domains:In Recommendation Engines: When it comes to cosine similarity, we can group users who have the same tastes, even if they are doing different amounts of overall activity. A streaming service could use this to recommend movies that align with a user’s genre preferences, regardless of what is popular among a small subset of very active viewers.In Document Retrieval: When querying a database of documents or research papers, cosine similarity ranks documents according to whether their content is similar in meaning to the user’s query, rather than their text length. This enables systems to retrieve results that are contextually relevant to the query, even though the documents are of a wide range of sizes.In Fraud Detection: Patterns of behavior are often more important than pure numbers. Cosine similarity can be used to detect anomalies in spending habits, as it compares the direction of the transaction vectors — type of merchant, time of day, transaction amount, etc. — rather than the absolute magnitude.And these differences matter because they give a sense of how systems “think”. Let’s get back to that credit card example one more time: It might, for example, identify a high-value $7,000 transaction for you new E-Bike as suspicious using Euclidean distance — even if that transaction is normal for you given you have an average spent of $20,000 a month. A cosine-based system, on the other hand, understands that the transaction is consistent with what the user typically spends their money on, thus avoiding unnecessary false notifications.But measures like Euclidean distance and cosine similarity are not merely theoretical. They’re the blueprints on which real-world systems stand. Whether it’s recommendation engines or fraud detection, the metrics we choose will directly impact how systems make sense of relationships in data.Vector Representations in Practice: Industry TransformationsPhoto by Louis Reed on UnsplashThis ability for abstraction is what makes vector representations so powerful — they transform complex and abstract field data into concepts that can be scored and actioned. These insights are catalyzing fundamental transformations in business processes, decision-making, and customer value delivery across sectors.Next, we will explore the solution use cases we are highlighting as concrete examples to see how vectors are freeing up time to solve big problems and creating new opportunities that have a big impact. I picked an industry to show what vector-based approaches to a challenge can achieve, so here is a healthcare example from a clinical setting. Why? Because it matters to us all and is rather easy to relate to than digging into the depths of the finance system, insurances, renewable energies or chemistry.Spotlight Healthcare: Pattern Recognition in Complex Medical DataThe healthcare industry poses a perfect storm of challenges that vector representations can uniquely solve. Think of the complexities of patient data: medical histories, genetic information, lifestyle factors, and treatment outcomes all interact in nuanced ways that traditional rule-based systems are incapable of capturing.At Massachusetts General Hospital, researchers implemented a vector-based early detection system for sepsis, a condition in which every hour of early detection increases the chances of survival by 7.6% (see the full study at pmc.ncbi.nlm.nih.gov/articles/PMC6166236/).In this new methodology, spontaneous neutrophil velocity profiles (SVP) are used to describe the movement patterns of neutrophils from a drop of blood. We won’t get too medically detailed here, because we’re vector-focused today, but a neutrophil is an immune cell that is kind of a first responder in what the body uses to fight off infections.The system then encodes each neutrophil’s motion as a vector that captures not just its magnitude (i.e., speed), but also its direction. So they converted biological patterns to high-dimensional vector spaces; thus, they got subtle differences and showed that healthy individuals and sepsis patients exhibited statistically significant differences in movement. Then, these numeric vectors were processed with the help of a machine learning model that was trained to detect early signs of sepsis. The result was a diagnostic tool that reached impressive sensitivity (97%) and specificity (98%) to achieve a rapid and accurate identification of this fatal condition. Probably with cosine similarity (the paper doesn’t go into much detail, so this is pure speculation, but it would be the most suitable) that we just learned about a moment ago.This is just one example of how medical data can be encoded into its vector representations and turned into malleable, actionable insights. This approach made it possible to re-contextualize complex relationships and, along with tread-based machine learning, worked around the limitations of previous diagnostic modalities and proved to be a potent tool for clinicians to save lives. It’s a powerful reminder that vectors aren’t merely theoretical constructs — they’re practical, life-saving solutions that are powering the future of healthcare as much as your credit card risk detection software and hopefully also your business.Lead and understand, or face disruption. The naked truth.Photo by Hunters Race on UnsplashWith all you have read about by now: Think of a decision as small as the decision about the metrics under which data relationships are evaluated. Leaders risk making assumptions that are subtle yet disastrous. You are basically using algebra as a tool, and while getting some result, you cannot know if it is right or not: doing leadership decisions without understanding the fundamentals of vectors is like calculating using a calculator but not knowing what formulas you are using.The good news is this doesn’t mean that business leaders have to become data scientists. Vectors are delightful because, once the core ideas have been grasped, they become very easy to work with. An understanding of a handful of concepts (for example, how vectors encode relationships, why distance metrics are important, and how embedding models function) can fundamentally change how you make high-level decisions. These tools will help you ask better questions, work with technical teams more effectively, and make sound decisions about the systems that will govern your business.The returns on this small investment in comprehension are huge. There is much talk about personalization. Yet, few organizations use vector-based thinking in their business strategies. It could help them leverage personalization to its full potential. Such an approach would delight customers with tailored experiences and build loyalty. You could innovate in areas like fraud detection and operational efficiency, leveraging subtle patterns in data that traditional ones miss — or perhaps even save lives, as described above. Equally important, you can avoid expensive missteps that happen when leaders defer to others for key decisions without understanding what they mean.The truth is, vectors are here now, driving a vast majority of all the hyped AI technology behind the scenes to help create the world we navigate in today and tomorrow. Companies that do not adapt their leadership to think in vectors risk falling behind a competitive landscape that becomes ever more data-driven. One who adopts this new paradigm will not just survive but will prosper in an age of never-ending AI innovation.Now is the moment to act. Start to view the world through vectors. Study their tongue, examine their doctrine, and ask how the new could change your tactics and your lodestars. Much in the way that algebra became an essential tool for writing one’s way through practical life challenges, vectors will soon serve as the literacy of the data age. Actually they do already. It is the future of which the powerful know how to take control. The question is not if vectors will define the next era of businesses; it is whether you are prepared to lead it.The Invisible Revolution: How Vectors Are (Re)defining Business Success was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. business, deep-dives, machine-learning, ai, vector Towards Data Science – MediumRead More

 Add to favorites
Add to favorites
0 Comments