Exploring the Power of Lamini Memory Tuning

Accuracy is often critical for LLM applications, especially in cases such as API calling or summarisation of financial reports. Fortunately, there are ways to enhance precision. The best practices to improve accuracy include the following steps:
- You can start simply with prompt engineering techniques — adding more detailed instructions, using few-shot prompting, or asking the model to think step-by-step.
- If accuracy is still insufficient, you can incorporate a self-reflection step, for example, to return errors from the API calls and ask the LLM to correct mistakes.
- The next option is to provide the most relevant context to the LLM using RAG (Retrieval-Augmented Generation) to boost precision further.
We’ve explored this approach in my previous TDS article, “From Prototype to Production: Enhancing LLM Accuracy”. In that project, we built an SQL Agent and went from 0% valid SQL queries to 70% accuracy. However, there are limits to what we can achieve with prompt. To break through this barrier and reach the next frontier of accuracy, we need to adopt more advanced techniques.
The most promising option is fine-tuning. With fine-tuning, we can move from relying solely on information in prompts to embedding additional information directly into the model’s weights.
Fine-tuning
Let’s start by understanding what fine-tuning is. Fine-tuning is the process of refining pre-trained models by training them on smaller, task-specific datasets to enhance their performance in particular applications. Basic models are initially trained on vast amounts of data, which allows them to develop a broad understanding of language. Fine-tuning, however, tailors these models to specialized tasks, transforming them from general-purpose systems into highly targeted tools. For example, instruction fine-tuning taught GPT-2 to chat and follow instructions, and that’s how ChatGPT emerged.
Basic LLMs are initially trained to predict the next token based on vast text corpora. Fine-tuning typically adopts a supervised approach, where the model is presented with specific questions and corresponding answers, allowing it to adjust its weights to improve accuracy.
Historically, fine-tuning required updating all model weights, a method known as full fine-tuning. This process was computationally expensive since it required storing all the model weights, states, gradients and forward activations in memory. To address these challenges, parameter-efficient fine-tuning techniques were introduced. PEFT methods update only the small set of the model parameters while keeping the rest frozen. Among these methods, one of the most widely adopted is LoRA (Low-Rank Adaptation), which significantly reduces the computational cost without compromising performance.
Pros & cons
Before considering fine-tuning, it’s essential to weigh its advantages and limitations.
Advantages:
- Fine-tuning enables the model to learn and retain significantly more information than can be provided through prompts alone.
- It usually gives higher accuracy, often exceeding 90%.
- During inference, it can reduce costs by enabling the use of smaller, task-specific models instead of larger, general-purpose ones.
- Fine-tuned small models can often be deployed on-premises, eliminating reliance on cloud providers such as OpenAI or Anthropic. This approach reduces costs, enhances privacy, and minimizes dependency on external infrastructure.
Disadvantages:
- Fine-tuning requires upfront investments for model training and data preparation.
- It requires specific technical knowledge and may involve a steep learning curve.
- The quality of results depends heavily on the availability of high-quality training data.
Since this project is focused on gaining knowledge, we will proceed with fine-tuning. However, in real-world scenarios, it’s important to evaluate whether the benefits of fine-tuning justify all the associated costs and efforts.
Execution
The next step is to plan how we will approach fine-tuning. After listening to the “Improving Accuracy of LLM Applications” course, I’ve decided to try the Lamini platform for the following reasons:
- It offers a simple one-line API call to fine-tune the model. It’s especially convenient since we’re just starting to learn a new technique.
- Although it’s not free and can be quite expensive for toy projects (at $1 per tuning step), they offer free credits upon registration, which are sufficient for initial testing.
- Lamini has implemented a new approach, Lamini Memory Tuning, which promises zero loss of factual accuracy while preserving general capabilities. This is a significant claim, and it’s worth testing out. We will discuss this approach in more detail shortly.
Of course, there are lots of other fine-tuning options you can consider:
- The Llama documentation provides numerous recipes for fine-tuning, which can be executed on a cloud server or even locally for smaller models.
- There are many step-by-step guides available online, including the tutorial on how to fine-tune Llama on Kaggle from DataCamp.
- You can fine-tune not only open-sourced models. OpenAI also offers the capability to fine-tune their models.
Lamini Memory Tuning
As I mentioned earlier, Lamini released a new approach to fine-tuning, and I believe it’s worth discussing it in more detail.
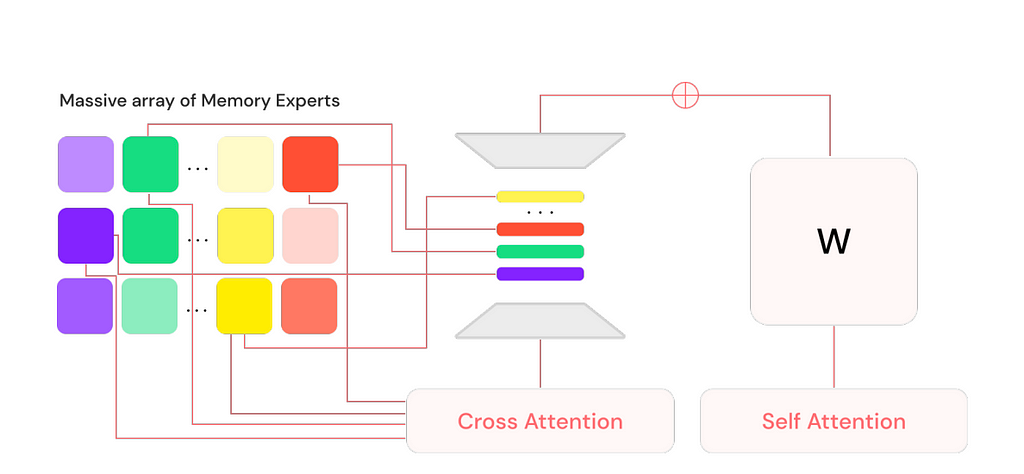
Lamini introduced the Mixture of Memory Experts (MoME) approach, which enables LLMs to learn a vast amount of factual information with almost zero loss, all while maintaining generalization capabilities and requiring a feasible amount of computational resources.
To achieve this, Lamini extended a pre-trained LLM by adding a large number (on the order of 1 million) of LoRA adapters along with a cross-attention layer. Each LoRA adapter is a memory expert, functioning as a type of memory for the model. These memory experts specialize in different aspects, ensuring that the model retains faithful and accurate information from the data it was tuned on. Inspired by information retrieval, these million memory experts are equivalent to indices from which the model intelligently retrieves and routes.
At inference time, the model retrieves a subset of the most relevant experts at each layer and merges back into the base model to generate a response to the user query.
Lamini Memory Tuning is said to be capable of achieving 95% accuracy. The key difference from traditional instruction fine-tuning is that instead of optimizing for average error across all tasks, this approach focuses on achieving zero error for the facts the model is specifically trained to remember.

So, this approach allows an LLM to preserve its ability to generalize with average error on everything else while recalling the important facts nearly perfectly.
For further details, you can refer to the research paper “Banishing LLM Hallucinations Requires Rethinking Generalization” by Li et al. (2024)
Lamini Memory Tuning holds great promise — let’s see if it delivers on its potential in practice.
Setup
As always, let’s begin by setting everything up. As we discussed, we’ll be using Lamini to fine-tune Llama, so the first step is to install the Lamini package.
pip install lamini
Additionally, we need to set up the Lamini API Key on their website and specify it as an environment variable.
export LAMINI_API_KEY="<YOUR-LAMINI-API-KEY>"
As I mentioned above, we will be improving the SQL Agent, so we need a database. For this example, we’ll continue using ClickHouse, but feel free to choose any database that suits your needs. You can find more details on the ClickHouse setup and the database schema in the previous article.
Creating a training dataset
To fine-tune an LLM, we first need a dataset — in our case, a set of pairs of questions and answers (SQL queries). The task of putting together a dataset might seem daunting, but luckily, we can leverage LLMs to do it.
The key factors to consider while preparing the dataset:
- The quality of the data is crucial, as we will ask the model to remember these facts.
- Diversity in the examples is important so that a model can learn how to handle different cases.
- It’s preferable to use real data rather than synthetically generated data since it better represents real-life questions.
- The usual minimum size for a fine-tuning dataset is around 1,000 examples, but the more high-quality data, the better.
Generating examples
All the information required to create question-and-answer pairs is present in the database schema, so it will be a feasible task for an LLM to generate examples. Additionally, I have a representative set of Q&A pairs that I used for RAG approach, which we can present to the LLM as examples of valid queries (using the few-shot prompting technique). Let’s load the RAG dataset.
# loading a set of examples
with open('rag_set.json', 'r') as f:
rag_set = json.loads(f.read())
rag_set_df = pd.DataFrame(rag_set)
rag_set_df['qa_fmt'] = list(map(
lambda x, y: "question: %s, sql_query: %s" % (x, y),
rag_set_df.question,
rag_set_df.sql_query
))
The idea is to iteratively provide the LLM with the schema information and a set of random examples (to ensure diversity in the questions) and ask it to generate a new, similar, but different Q&A pair.
Let’s create a system prompt that includes all the necessary details about the database schema.
generate_dataset_system_prompt = '''
You are a senior data analyst with more than 10 years of experience writing complex SQL queries.
There are two tables in the database you're working with with the following schemas.
Table: ecommerce.users
Description: customers of the online shop
Fields:
- user_id (integer) - unique identifier of customer, for example, 1000004 or 3000004
- country (string) - country of residence, for example, "Netherlands" or "United Kingdom"
- is_active (integer) - 1 if customer is still active and 0 otherwise
- age (integer) - customer age in full years, for example, 31 or 72
Table: ecommerce.sessions
Description: sessions for online shop
Fields:
- user_id (integer) - unique identifier of customer, for example, 1000004 or 3000004
- session_id (integer) - unique identifier of session, for example, 106 or 1023
- action_date (date) - session start date, for example, "2021-01-03" or "2024-12-02"
- session_duration (integer) - duration of session in seconds, for example, 125 or 49
- os (string) - operation system that customer used, for example, "Windows" or "Android"
- browser (string) - browser that customer used, for example, "Chrome" or "Safari"
- is_fraud (integer) - 1 if session is marked as fraud and 0 otherwise
- revenue (float) - income in USD (the sum of purchased items), for example, 0.0 or 1506.7
Write a query in ClickHouse SQL to answer the following question.
Add "format TabSeparatedWithNames" at the end of the query to get data from ClickHouse database in the right format.
'''
The next step is to create a template for the user query.
generate_dataset_qa_tmpl = '''
Considering the following examples, please, write question
and SQL query to answer it, that is similar but different to provided below.
Examples of questions and SQL queries to answer them:
{examples}
'''
Since we need a high-quality dataset, I prefer using a more advanced model — GPT-4o— rather than Llama. As usual, I’ll initialize the model and create a dummy tool for structured output.
from langchain_core.tools import tool
@tool
def generate_question_and_answer(comments: str, question: str, sql_query: str) -> str:
"""Returns the new question and SQL query
Args:
comments (str): 1-2 sentences about the new question and answer pair,
question (str): new question
sql_query (str): SQL query in ClickHouse syntax to answer the question
"""
pass
from langchain_openai import ChatOpenAI
generate_qa_llm = ChatOpenAI(model="gpt-4o", temperature = 0.5)
.bind_tools([generate_question_and_answer])
Now, let’s combine everything into a function that will generate a Q&A pair and create a set of examples.
# helper function to combine system + user prompts
def get_openai_prompt(question, system):
messages = [
("system", system),
("human", question)
]
return messages
def generate_qa():
# selecting 3 random examples
sample_set_df = rag_set_df.sample(3)
examples = 'nn'.join(sample_set_df.qa_fmt.values)
# constructing prompt
prompt = get_openai_prompt(
generate_dataset_qa_tmpl.format(examples = examples),
generate_dataset_system_prompt)
# calling LLM
qa_res = generate_qa_llm.invoke(prompt)
try:
rec = qa_res.tool_calls[0]['args']
rec['examples'] = examples
return rec
except:
pass
# executing function
qa_tmp = []
for i in tqdm.tqdm(range(2000)):
qa_tmp.append(generate_qa())
new_qa_df = pd.DataFrame(qa_tmp)
I generated 2,000 examples, but in reality, I used a much smaller dataset for this toy project. Therefore, I recommend limiting the number of examples to 200–300.
Cleaning the dataset
As we know, “garbage in, garbage out”, so an essential step before fine-tuning is cleaning the data generated by the LLM.
The first — and most obvious — check is to ensure that each SQL query is valid.
def is_valid_output(s):
if s.startswith('Database returned the following error:'):
return 'error'
if len(s.strip().split('n')) >= 1000:
return 'too many rows'
return 'ok'
new_qa_df['output'] = new_qa_df.sql_query.map(get_clickhouse_data)
new_qa_df['is_valid_output'] = new_qa_df.output.map(is_valid_output)
There are no invalid SQL queries, but some questions return over 1,000 rows.

Although these cases are valid, we’re focusing on an OLAP scenario with aggregated stats, so I’ve retained only queries that return 100 or fewer rows.
new_qa_df['output_rows'] = new_qa_df.output.map(
lambda x: len(x.strip().split('n')))
filt_new_qa_df = new_qa_df[new_qa_df.output_rows <= 100]
I also eliminated cases with empty output — queries that return no rows or only the header.
filt_new_qa_df = filt_new_qa_df[filt_new_qa_df.output_rows > 1]
Another important check is for duplicate questions. The same question with different answers could confuse the model, as it won’t be able to tune to both solutions simultaneously. And in fact, we have such cases.
filt_new_qa_df = filt_new_qa_df[['question', 'sql_query']].drop_duplicates()
filt_new_qa_df['question'].value_counts().head(10)

To resolve these duplicates, I’ve kept only one answer for each question.
filt_new_qa_df = filt_new_qa_df.drop_duplicates('question')
Although I generated around 2,000 examples, I’ve decided to use a smaller dataset of 200 question-and-answer pairs. Fine-tuning with a larger dataset would require more tuning steps and be more expensive.
sample_dataset_df = pd.read_csv('small_sample_for_finetuning.csv', sep = 't')
You can find the final training dataset on GitHub.
Now that our training dataset is ready, we can move on to the most exciting part — fine-tuning.
Fine-tuning
The first iteration
The next step is to generate the sets of requests and responses for the LLM that we will use to fine-tune the model.
Since we’ll be working with the Llama model, let’s create a helper function to construct a prompt for it.
def get_llama_prompt(user_message, system_message=""):
system_prompt = ""
if system_message != "":
system_prompt = (
f"<|start_header_id|>system<|end_header_id|>nn{system_message}"
f"<|eot_id|>"
)
prompt = (f"<|begin_of_text|>{system_prompt}"
f"<|start_header_id|>user<|end_header_id|>nn"
f"{user_message}"
f"<|eot_id|>"
f"<|start_header_id|>assistant<|end_header_id|>nn"
)
return prompt
For requests, we will use the following system prompt, which includes all the necessary information about the data schema.
generate_query_system_prompt = '''
You are a senior data analyst with more than 10 years of experience writing complex SQL queries.
There are two tables in the database you're working with with the following schemas.
Table: ecommerce.users
Description: customers of the online shop
Fields:
- user_id (integer) - unique identifier of customer, for example, 1000004 or 3000004
- country (string) - country of residence, for example, "Netherlands" or "United Kingdom"
- is_active (integer) - 1 if customer is still active and 0 otherwise
- age (integer) - customer age in full years, for example, 31 or 72
Table: ecommerce.sessions
Description: sessions of usage the online shop
Fields:
- user_id (integer) - unique identifier of customer, for example, 1000004 or 3000004
- session_id (integer) - unique identifier of session, for example, 106 or 1023
- action_date (date) - session start date, for example, "2021-01-03" or "2024-12-02"
- session_duration (integer) - duration of session in seconds, for example, 125 or 49
- os (string) - operation system that customer used, for example, "Windows" or "Android"
- browser (string) - browser that customer used, for example, "Chrome" or "Safari"
- is_fraud (integer) - 1 if session is marked as fraud and 0 otherwise
- revenue (float) - income in USD (the sum of purchased items), for example, 0.0 or 1506.7
Write a query in ClickHouse SQL to answer the following question.
Add "format TabSeparatedWithNames" at the end of the query to get data from ClickHouse database in the right format.
Answer questions following the instructions and providing all the needed information and sharing your reasoning.
'''
Let’s create the responses in the format suitable for Lamini fine-tuning. We need to prepare a list of dictionaries with input and output keys.
formatted_responses = []
for rec in sample_dataset_df.to_dict('records'):
formatted_responses.append(
{
'input': get_llama_prompt(rec['question'],
generate_query_system_prompt),
'output': rec['sql_query']
}
)
Now, we are fully prepared for fine-tuning. We just need to select a model and initiate the process. We will be fine-tuning the Llama 3.1 8B model.
from lamini import Lamini
llm = Lamini(model_name="meta-llama/Meta-Llama-3.1-8B-Instruct")
finetune_args = {
"max_steps": 50,
"learning_rate": 0.0001
}
llm.train(
data_or_dataset_id=formatted_responses,
finetune_args=finetune_args,
)
We can specify several hyperparameters, and you can find all the details in the Lamini documentation. For now, I’ve passed only the most essential ones to the function:
- max_steps: This determines the number of tuning steps. The documentation recommends using 50 steps for experimentation to get initial results without spending too much money.
- learning_rate: This parameter determines the step size of each iteration while moving toward a minimum of a loss function (Wikipedia). The default is 0.0009, but based on the guidance, I’ve decided to use a smaller value.
Now, we just need to wait for 10–15 minutes while the model trains, and then we can test it.
finetuned_llm = Lamini(model_name='<model_id>')
# you can find Model ID in the Lamini interface
question = '''How many customers made purchase in December 2024?'''
prompt = get_llama_prompt(question, generate_query_system_prompt)
finetuned_llm.generate(prompt, max_new_tokens=200)
# select uniqExact(s.user_id) as customers
# from ecommerce.sessions s join ecommerce.users u
# on s.user_id = u.user_id
# where (toStartOfMonth(action_date) = '2024-12-01') and (revenue > 0)
# format TabSeparatedWithNames
It’s worth noting that we’re using Lamini for inference as well and will have to pay for it. You can find up-to-date information about the costs here.
At first glance, the result looks promising, but we need a more robust accuracy evaluation to confirm it.
Additionally, it’s worth noting that since we’ve fine-tuned the model for our specific task, it now consistently returns SQL queries, meaning we may no longer need to use tool calls for structured output.
Evaluating the quality
We’ve discussed LLM accuracy evaluation in detail in my previous article, so here I’ll provide a brief recap.
We use a golden set of question-and-answer pairs to evaluate the model’s quality. Since this is a toy example, I’ve limited the set to just 10 pairs, which you can review on GitHub.
The evaluation process consists of two parts:
- SQL Query Validity: First, we check that the SQL query is valid, meaning ClickHouse doesn’t return errors during execution.
- Query Correctness: Next, we ensure that the generated query is correct. We compare the outputs of the generated and true queries using LLMs to verify that they provide semantically identical results.
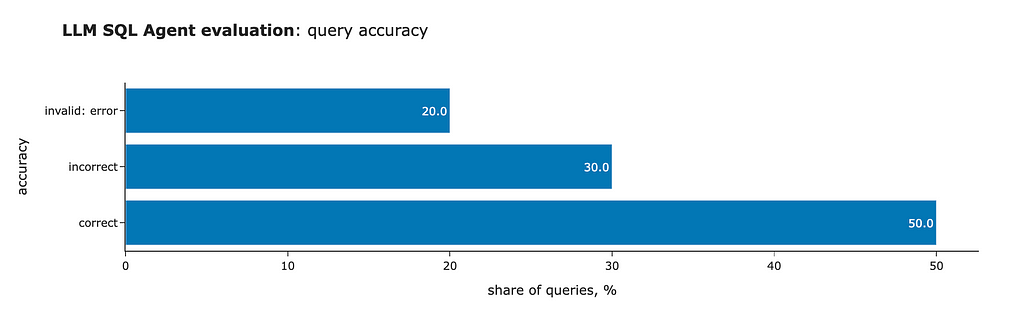
The initial results are far from ideal, but they are significantly better than the base Llama model (which produced zero valid SQL queries). Here’s what we found:
- ClickHouse returned errors for two queries.
- Three queries were executed, but the results were incorrect.
- Five queries were correct.
No surprises — there’s no silver bullet, and it’s always an iterative process. Let’s investigate what went wrong.
Diving into the errors
The approach is straightforward. Let’s examine the errors one by one to understand why we got these results and how we can fix them. We’ll start with the first unsuccessful example.
Question: Which country had the highest number of first-time users in 2024?
Golden query:
select
country,
count(distinct user_id) as users
from
(
select user_id, min(action_date) as first_date
from ecommerce.sessions
group by user_id
having toStartOfYear(first_date) = '2024-01-01'
) as t
inner join ecommerce.users as u
on t.user_id = u.user_id
group by country
order by users desc
limit 1
format TabSeparatedWithNames
Generated query:
select
country,
count(distinct u.user_id) as first_time_users
from ecommerce.sessions s
join ecommerce.users u
on s.user_id = u.user_id
where (toStartOfYear(action_date) = '2024-01-01')
and (s.session_id = 1)
group by country
order by first_time_users desc
limit 1
format TabSeparatedWithNames
The query is valid, but it returns an incorrect result. The issue lies in the model’s assumption that the first session for each user will always have session_id = 1. Since Lamini Memory Tuning allows the model to learn facts from the training data, let’s investigate why the model made this assumption. Likely, it’s in our data.
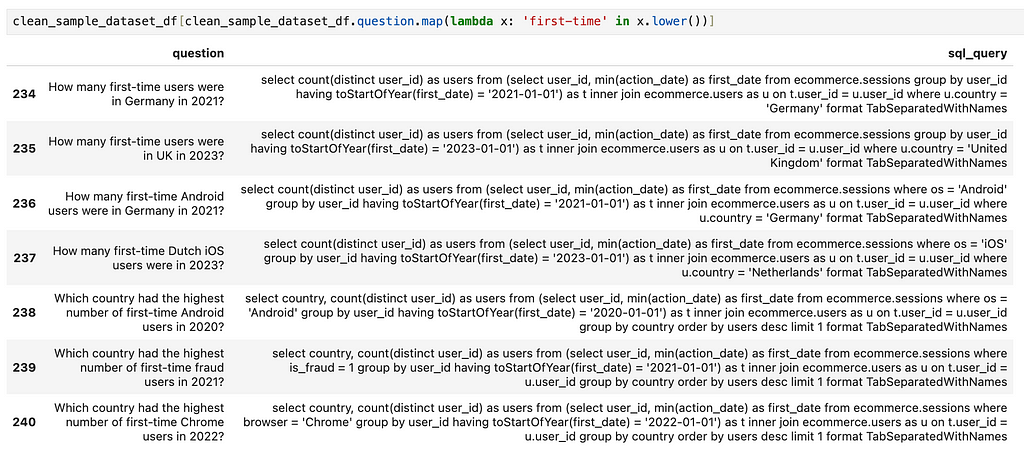
Let’s review all the examples that mention first. I’ll use broad and simple search criteria to get a high-level view.
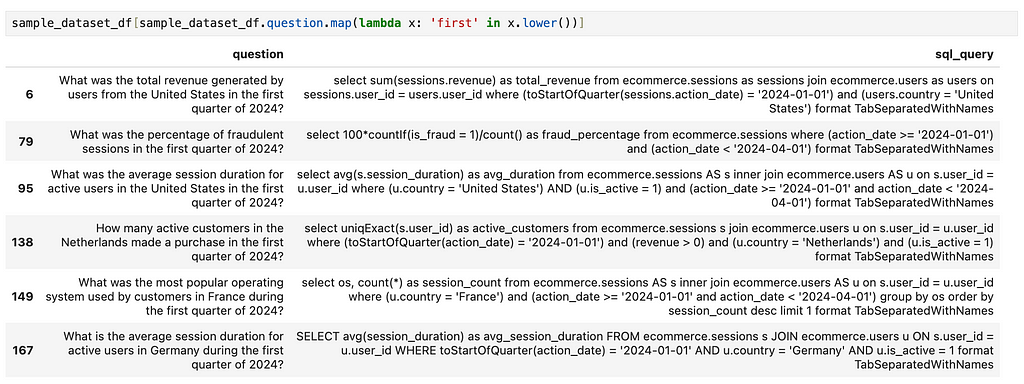
As we can see, there are no examples mentioning first-time users — only references to the first quarter. It’s no surprise that the model wasn’t able to capture this concept. The solution is straightforward: we just need to add a set of examples with questions and answers specifically about first-time users.
Let’s move on to the next problematic case.
Question: What was the fraud rate in 2023, expressed as a percentage?
Golden query:
select
100*uniqExactIf(user_id, is_fraud = 1)/uniqExact(user_id) as fraud_rate
from ecommerce.sessions
where (toStartOfYear(action_date) = '2023-01-01')
format TabSeparatedWithNames
Generated query:
select
100*countIf(is_fraud = 1)/count() as fraud_rate
from ecommerce.sessions
where (toStartOfYear(action_date) = '2023-01-01')
format TabSeparatedWithNames
Here’s another misconception: we assumed that the fraud rate is based on the share of users, while the model calculated it based on the share of sessions.
Let’s check the examples related to the fraud rate in the data. There are two cases: one calculates the share of users, while the other calculates the share of sessions.

To fix this issue, I corrected the incorrect answer and added more accurate examples involving fraud rate calculations.

I’d like to discuss another incorrect case, as it will highlight an important aspect of the process of resolving these issues.
Question: What are the median and interquartile range (IQR) of purchase revenue for each country?
Golden query:
select
country,
median(revenue) as median_revenue,
quantile(0.25)(revenue) as percentile_25_revenue,
quantile(0.75)(revenue) as percentile_75_revenue
from ecommerce.sessions AS s
inner join ecommerce.users AS u
on u.user_id = s.user_id
where (revenue > 0)
group by country
format TabSeparatedWithNames
Generated query:
select
country,
median(revenue) as median_revenue,
quantile(0.25)(revenue) as percentile_25_revenue,
quantile(0.75)(revenue) as percentile_75_revenue
from ecommerce.sessions s join ecommerce.users u
on s.user_id = u.user_id
group by country
format TabSeparatedWithNames
When inspecting the problem, it’s crucial to focus on the model’s misconceptions or incorrect assumptions. For example, in this case, there may be a temptation to add examples similar to those in the golden dataset, but that would be too specific. Instead, we should address the actual root cause of the model’s misconception:
- It understood the concepts of median and IQR quite well.
- The split by country is also correct.
- However, it misinterpreted the concept of “purchase revenue”, including sessions where there was no purchase at all (revenue = 0).
So, we need to ensure that our datasets contain enough information related to purchase revenue. Let’s take a look at what we have now. There’s only one example, and it’s incorrect.

Let’s fix this example and add more cases of purchase revenue calculations.

Using a similar approach, I’ve added more examples for the two remaining incorrect queries and compiled an updated, cleaned version of the training dataset. You can find it on GitHub. With this, our data is ready to the next iteration.
Another iteration of fine-tuning
Before diving into fine-tuning, it’s essential to double-check the quality of the training dataset by ensuring that all SQL queries are valid.
clean_sample_dataset_df = pd.read_csv(
'small_sample_for_finetuning_cleaned.csv', sep = 't',
on_bad_lines = 'warn')
clean_sample_dataset_df['output'] = clean_sample_dataset_df.sql_query
.map(lambda x: get_clickhouse_data(str(x)))
clean_sample_dataset_df['is_valid_output'] = clean_sample_dataset_df['output']
.map(is_valid_output)
print(clean_sample_dataset_df.is_valid_output.value_counts())
# is_valid_output
# ok 241
clean_formatted_responses = []
for rec in clean_sample_dataset_df.to_dict('records'):
clean_formatted_responses.append(
{
'input': get_llama_prompt(
rec['question'],
generate_query_system_prompt),
'output': rec['sql_query']
}
)
Now that we’re confident in the data, we can proceed with fine-tuning. This time, I’ve decided to train it for 150 steps to achieve better accuracy.
finetune_args = {
"max_steps": 150,
"learning_rate": 0.0001
}
llm = Lamini(model_name="meta-llama/Meta-Llama-3.1-8B-Instruct")
llm.train(
data_or_dataset_id=clean_formatted_responses,
finetune_args=finetune_args
)
After waiting a bit longer than last time, we now have a new fine-tuned model with nearly zero loss after 150 tuning steps.
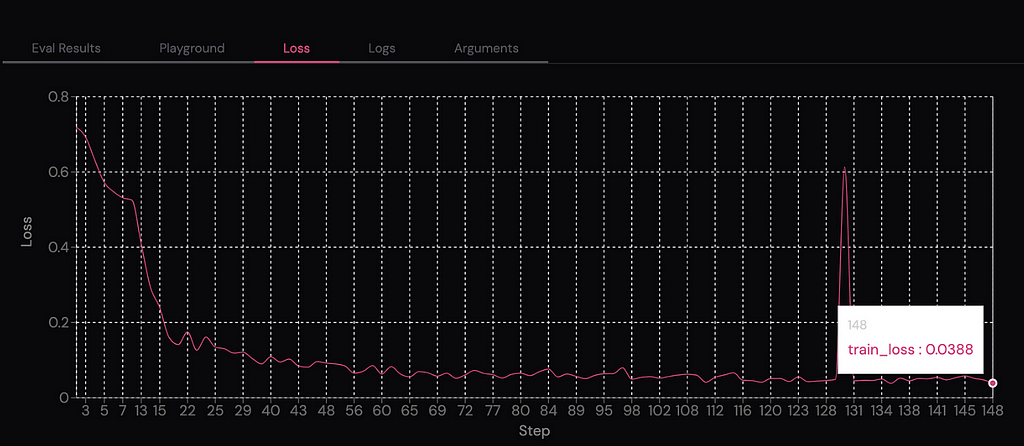
We can run the evaluation again and see much better results. So, our approach is working.
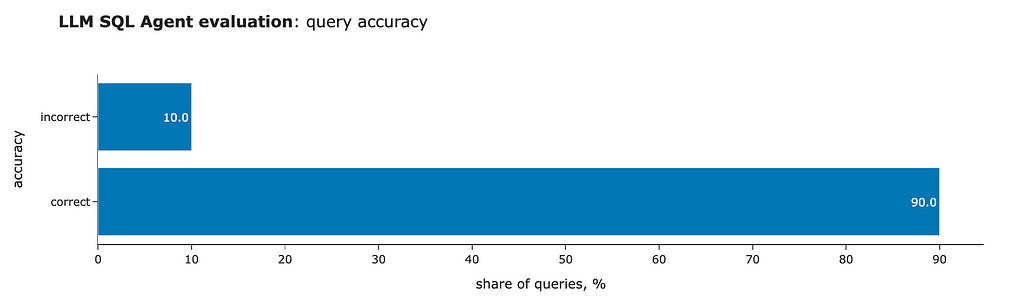
The result is astonishing, but it’s still worth examining the incorrect example to understand what went wrong. We got an incorrect result for the question we discussed earlier: “What are the median and interquartile range (IQR) of purchase revenue for each country?” However, this time, the model generated a query that is exactly identical to the one in the golden set.
select
country,
median(revenue) as median_revenue,
quantile(0.25)(revenue) as percentile_25_revenue,
quantile(0.75)(revenue) as percentile_75_revenue
from ecommerce.sessions AS s
inner join ecommerce.users AS u
on u.user_id = s.user_id
where (s.revenue > 0)
group by country
format TabSeparatedWithNames
So, the issue actually lies in our evaluation. In fact, if you try to execute this query multiple times, you’ll notice that the results are slightly different each time. The root cause is that the quantile function in ClickHouse computes approximate values using reservoir sampling, which is why we’re seeing varying results. We could have used quantileExact instead to get more consistent numbers.
That said, this means that fine-tuning has allowed us to achieve 100% accuracy. Even though our toy golden dataset consists of just 10 questions, this is a tremendous achievement. We’ve progressed all the way from zero valid queries with vanilla Llama to 70% accuracy with RAG and self-reflection, and now, thanks to Lamini Memory Tuning, we’ve reached 100% accuracy.
You can find the full code on GitHub.
Summary
In this article, we continued exploring techniques to improve LLM accuracy:
- After trying RAG and self-reflection in the previous article, we moved on to a more advanced technique — fine-tuning.
- We experimented with Memory Tuning developed by Lamini, which enables a model to remember a large volume of facts with near-zero errors.
- In our example, Memory Tuning performed exceptionally well, and we achieved 100% accuracy on our evaluation set of 10 questions.
Thank you a lot for reading this article. I hope this article was insightful for you. If you have any follow-up questions or comments, please leave them in the comments section.
Reference
All the images are produced by the author unless otherwise stated.
This article is inspired by the “Improving Accuracy of LLM Applications” short course from DeepLearning.AI.
Disclaimer: I am not affiliated with Lamini in any way. The views expressed in this article are solely my own, based on independent testing and evaluation of the Lamini platform. This post is intended for educational purposes and does not constitute an endorsement of any specific tool or service.
The Next Frontier in LLM Accuracy was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Exploring the Power of Lamini Memory TuningImage generated by DALL-E 3Accuracy is often critical for LLM applications, especially in cases such as API calling or summarisation of financial reports. Fortunately, there are ways to enhance precision. The best practices to improve accuracy include the following steps:You can start simply with prompt engineering techniques — adding more detailed instructions, using few-shot prompting, or asking the model to think step-by-step.If accuracy is still insufficient, you can incorporate a self-reflection step, for example, to return errors from the API calls and ask the LLM to correct mistakes.The next option is to provide the most relevant context to the LLM using RAG (Retrieval-Augmented Generation) to boost precision further.We’ve explored this approach in my previous TDS article, “From Prototype to Production: Enhancing LLM Accuracy”. In that project, we built an SQL Agent and went from 0% valid SQL queries to 70% accuracy. However, there are limits to what we can achieve with prompt. To break through this barrier and reach the next frontier of accuracy, we need to adopt more advanced techniques.The most promising option is fine-tuning. With fine-tuning, we can move from relying solely on information in prompts to embedding additional information directly into the model’s weights.Fine-tuningLet’s start by understanding what fine-tuning is. Fine-tuning is the process of refining pre-trained models by training them on smaller, task-specific datasets to enhance their performance in particular applications. Basic models are initially trained on vast amounts of data, which allows them to develop a broad understanding of language. Fine-tuning, however, tailors these models to specialized tasks, transforming them from general-purpose systems into highly targeted tools. For example, instruction fine-tuning taught GPT-2 to chat and follow instructions, and that’s how ChatGPT emerged.Basic LLMs are initially trained to predict the next token based on vast text corpora. Fine-tuning typically adopts a supervised approach, where the model is presented with specific questions and corresponding answers, allowing it to adjust its weights to improve accuracy.Historically, fine-tuning required updating all model weights, a method known as full fine-tuning. This process was computationally expensive since it required storing all the model weights, states, gradients and forward activations in memory. To address these challenges, parameter-efficient fine-tuning techniques were introduced. PEFT methods update only the small set of the model parameters while keeping the rest frozen. Among these methods, one of the most widely adopted is LoRA (Low-Rank Adaptation), which significantly reduces the computational cost without compromising performance.Pros & consBefore considering fine-tuning, it’s essential to weigh its advantages and limitations.Advantages:Fine-tuning enables the model to learn and retain significantly more information than can be provided through prompts alone.It usually gives higher accuracy, often exceeding 90%.During inference, it can reduce costs by enabling the use of smaller, task-specific models instead of larger, general-purpose ones.Fine-tuned small models can often be deployed on-premises, eliminating reliance on cloud providers such as OpenAI or Anthropic. This approach reduces costs, enhances privacy, and minimizes dependency on external infrastructure.Disadvantages:Fine-tuning requires upfront investments for model training and data preparation.It requires specific technical knowledge and may involve a steep learning curve.The quality of results depends heavily on the availability of high-quality training data.Since this project is focused on gaining knowledge, we will proceed with fine-tuning. However, in real-world scenarios, it’s important to evaluate whether the benefits of fine-tuning justify all the associated costs and efforts.ExecutionThe next step is to plan how we will approach fine-tuning. After listening to the “Improving Accuracy of LLM Applications” course, I’ve decided to try the Lamini platform for the following reasons:It offers a simple one-line API call to fine-tune the model. It’s especially convenient since we’re just starting to learn a new technique.Although it’s not free and can be quite expensive for toy projects (at $1 per tuning step), they offer free credits upon registration, which are sufficient for initial testing.Lamini has implemented a new approach, Lamini Memory Tuning, which promises zero loss of factual accuracy while preserving general capabilities. This is a significant claim, and it’s worth testing out. We will discuss this approach in more detail shortly.Of course, there are lots of other fine-tuning options you can consider:The Llama documentation provides numerous recipes for fine-tuning, which can be executed on a cloud server or even locally for smaller models.There are many step-by-step guides available online, including the tutorial on how to fine-tune Llama on Kaggle from DataCamp.You can fine-tune not only open-sourced models. OpenAI also offers the capability to fine-tune their models.Lamini Memory TuningAs I mentioned earlier, Lamini released a new approach to fine-tuning, and I believe it’s worth discussing it in more detail.Lamini introduced the Mixture of Memory Experts (MoME) approach, which enables LLMs to learn a vast amount of factual information with almost zero loss, all while maintaining generalization capabilities and requiring a feasible amount of computational resources.To achieve this, Lamini extended a pre-trained LLM by adding a large number (on the order of 1 million) of LoRA adapters along with a cross-attention layer. Each LoRA adapter is a memory expert, functioning as a type of memory for the model. These memory experts specialize in different aspects, ensuring that the model retains faithful and accurate information from the data it was tuned on. Inspired by information retrieval, these million memory experts are equivalent to indices from which the model intelligently retrieves and routes.At inference time, the model retrieves a subset of the most relevant experts at each layer and merges back into the base model to generate a response to the user query.Figure from the paper by Li et al. 2024 | sourceLamini Memory Tuning is said to be capable of achieving 95% accuracy. The key difference from traditional instruction fine-tuning is that instead of optimizing for average error across all tasks, this approach focuses on achieving zero error for the facts the model is specifically trained to remember.Figure from the paper by Li et al. 2024 | sourceSo, this approach allows an LLM to preserve its ability to generalize with average error on everything else while recalling the important facts nearly perfectly.For further details, you can refer to the research paper “Banishing LLM Hallucinations Requires Rethinking Generalization” by Li et al. (2024)Lamini Memory Tuning holds great promise — let’s see if it delivers on its potential in practice.SetupAs always, let’s begin by setting everything up. As we discussed, we’ll be using Lamini to fine-tune Llama, so the first step is to install the Lamini package.pip install laminiAdditionally, we need to set up the Lamini API Key on their website and specify it as an environment variable.export LAMINI_API_KEY=”<YOUR-LAMINI-API-KEY>”As I mentioned above, we will be improving the SQL Agent, so we need a database. For this example, we’ll continue using ClickHouse, but feel free to choose any database that suits your needs. You can find more details on the ClickHouse setup and the database schema in the previous article.Creating a training datasetTo fine-tune an LLM, we first need a dataset — in our case, a set of pairs of questions and answers (SQL queries). The task of putting together a dataset might seem daunting, but luckily, we can leverage LLMs to do it.The key factors to consider while preparing the dataset:The quality of the data is crucial, as we will ask the model to remember these facts.Diversity in the examples is important so that a model can learn how to handle different cases.It’s preferable to use real data rather than synthetically generated data since it better represents real-life questions.The usual minimum size for a fine-tuning dataset is around 1,000 examples, but the more high-quality data, the better.Generating examplesAll the information required to create question-and-answer pairs is present in the database schema, so it will be a feasible task for an LLM to generate examples. Additionally, I have a representative set of Q&A pairs that I used for RAG approach, which we can present to the LLM as examples of valid queries (using the few-shot prompting technique). Let’s load the RAG dataset.# loading a set of exampleswith open(‘rag_set.json’, ‘r’) as f: rag_set = json.loads(f.read())rag_set_df = pd.DataFrame(rag_set)rag_set_df[‘qa_fmt’] = list(map( lambda x, y: “question: %s, sql_query: %s” % (x, y), rag_set_df.question, rag_set_df.sql_query))The idea is to iteratively provide the LLM with the schema information and a set of random examples (to ensure diversity in the questions) and ask it to generate a new, similar, but different Q&A pair.Let’s create a system prompt that includes all the necessary details about the database schema.generate_dataset_system_prompt = ”’You are a senior data analyst with more than 10 years of experience writing complex SQL queries. There are two tables in the database you’re working with with the following schemas. Table: ecommerce.users Description: customers of the online shopFields: – user_id (integer) – unique identifier of customer, for example, 1000004 or 3000004- country (string) – country of residence, for example, “Netherlands” or “United Kingdom”- is_active (integer) – 1 if customer is still active and 0 otherwise- age (integer) – customer age in full years, for example, 31 or 72Table: ecommerce.sessions Description: sessions for online shopFields: – user_id (integer) – unique identifier of customer, for example, 1000004 or 3000004- session_id (integer) – unique identifier of session, for example, 106 or 1023- action_date (date) – session start date, for example, “2021-01-03” or “2024-12-02”- session_duration (integer) – duration of session in seconds, for example, 125 or 49- os (string) – operation system that customer used, for example, “Windows” or “Android”- browser (string) – browser that customer used, for example, “Chrome” or “Safari”- is_fraud (integer) – 1 if session is marked as fraud and 0 otherwise- revenue (float) – income in USD (the sum of purchased items), for example, 0.0 or 1506.7Write a query in ClickHouse SQL to answer the following question. Add “format TabSeparatedWithNames” at the end of the query to get data from ClickHouse database in the right format. ”’The next step is to create a template for the user query.generate_dataset_qa_tmpl = ”’Considering the following examples, please, write question and SQL query to answer it, that is similar but different to provided below.Examples of questions and SQL queries to answer them: {examples}”’Since we need a high-quality dataset, I prefer using a more advanced model — GPT-4o— rather than Llama. As usual, I’ll initialize the model and create a dummy tool for structured output.from langchain_core.tools import tool@tooldef generate_question_and_answer(comments: str, question: str, sql_query: str) -> str: “””Returns the new question and SQL query Args: comments (str): 1-2 sentences about the new question and answer pair, question (str): new question sql_query (str): SQL query in ClickHouse syntax to answer the question “”” passfrom langchain_openai import ChatOpenAIgenerate_qa_llm = ChatOpenAI(model=”gpt-4o”, temperature = 0.5) .bind_tools([generate_question_and_answer])Now, let’s combine everything into a function that will generate a Q&A pair and create a set of examples.# helper function to combine system + user promptsdef get_openai_prompt(question, system): messages = [ (“system”, system), (“human”, question) ] return messagesdef generate_qa(): # selecting 3 random examples sample_set_df = rag_set_df.sample(3) examples = ‘nn’.join(sample_set_df.qa_fmt.values) # constructing prompt prompt = get_openai_prompt( generate_dataset_qa_tmpl.format(examples = examples), generate_dataset_system_prompt) # calling LLM qa_res = generate_qa_llm.invoke(prompt) try: rec = qa_res.tool_calls[0][‘args’] rec[‘examples’] = examples return rec except: pass# executing functionqa_tmp = []for i in tqdm.tqdm(range(2000)): qa_tmp.append(generate_qa())new_qa_df = pd.DataFrame(qa_tmp)I generated 2,000 examples, but in reality, I used a much smaller dataset for this toy project. Therefore, I recommend limiting the number of examples to 200–300.Cleaning the datasetAs we know, “garbage in, garbage out”, so an essential step before fine-tuning is cleaning the data generated by the LLM.The first — and most obvious — check is to ensure that each SQL query is valid.def is_valid_output(s): if s.startswith(‘Database returned the following error:’): return ‘error’ if len(s.strip().split(‘n’)) >= 1000: return ‘too many rows’ return ‘ok’new_qa_df[‘output’] = new_qa_df.sql_query.map(get_clickhouse_data)new_qa_df[‘is_valid_output’] = new_qa_df.output.map(is_valid_output)There are no invalid SQL queries, but some questions return over 1,000 rows.Although these cases are valid, we’re focusing on an OLAP scenario with aggregated stats, so I’ve retained only queries that return 100 or fewer rows.new_qa_df[‘output_rows’] = new_qa_df.output.map( lambda x: len(x.strip().split(‘n’)))filt_new_qa_df = new_qa_df[new_qa_df.output_rows <= 100]I also eliminated cases with empty output — queries that return no rows or only the header.filt_new_qa_df = filt_new_qa_df[filt_new_qa_df.output_rows > 1]Another important check is for duplicate questions. The same question with different answers could confuse the model, as it won’t be able to tune to both solutions simultaneously. And in fact, we have such cases.filt_new_qa_df = filt_new_qa_df[[‘question’, ‘sql_query’]].drop_duplicates()filt_new_qa_df[‘question’].value_counts().head(10)To resolve these duplicates, I’ve kept only one answer for each question.filt_new_qa_df = filt_new_qa_df.drop_duplicates(‘question’) Although I generated around 2,000 examples, I’ve decided to use a smaller dataset of 200 question-and-answer pairs. Fine-tuning with a larger dataset would require more tuning steps and be more expensive.sample_dataset_df = pd.read_csv(‘small_sample_for_finetuning.csv’, sep = ‘t’)You can find the final training dataset on GitHub.Now that our training dataset is ready, we can move on to the most exciting part — fine-tuning.Fine-tuningThe first iterationThe next step is to generate the sets of requests and responses for the LLM that we will use to fine-tune the model.Since we’ll be working with the Llama model, let’s create a helper function to construct a prompt for it.def get_llama_prompt(user_message, system_message=””): system_prompt = “” if system_message != “”: system_prompt = ( f”<|start_header_id|>system<|end_header_id|>nn{system_message}” f”<|eot_id|>” ) prompt = (f”<|begin_of_text|>{system_prompt}” f”<|start_header_id|>user<|end_header_id|>nn” f”{user_message}” f”<|eot_id|>” f”<|start_header_id|>assistant<|end_header_id|>nn” ) return prompt For requests, we will use the following system prompt, which includes all the necessary information about the data schema.generate_query_system_prompt = ”’You are a senior data analyst with more than 10 years of experience writing complex SQL queries. There are two tables in the database you’re working with with the following schemas. Table: ecommerce.users Description: customers of the online shopFields: – user_id (integer) – unique identifier of customer, for example, 1000004 or 3000004- country (string) – country of residence, for example, “Netherlands” or “United Kingdom”- is_active (integer) – 1 if customer is still active and 0 otherwise- age (integer) – customer age in full years, for example, 31 or 72Table: ecommerce.sessions Description: sessions of usage the online shopFields: – user_id (integer) – unique identifier of customer, for example, 1000004 or 3000004- session_id (integer) – unique identifier of session, for example, 106 or 1023- action_date (date) – session start date, for example, “2021-01-03” or “2024-12-02”- session_duration (integer) – duration of session in seconds, for example, 125 or 49- os (string) – operation system that customer used, for example, “Windows” or “Android”- browser (string) – browser that customer used, for example, “Chrome” or “Safari”- is_fraud (integer) – 1 if session is marked as fraud and 0 otherwise- revenue (float) – income in USD (the sum of purchased items), for example, 0.0 or 1506.7Write a query in ClickHouse SQL to answer the following question. Add “format TabSeparatedWithNames” at the end of the query to get data from ClickHouse database in the right format. Answer questions following the instructions and providing all the needed information and sharing your reasoning. ”’Let’s create the responses in the format suitable for Lamini fine-tuning. We need to prepare a list of dictionaries with input and output keys.formatted_responses = []for rec in sample_dataset_df.to_dict(‘records’): formatted_responses.append( { ‘input’: get_llama_prompt(rec[‘question’], generate_query_system_prompt), ‘output’: rec[‘sql_query’] } )Now, we are fully prepared for fine-tuning. We just need to select a model and initiate the process. We will be fine-tuning the Llama 3.1 8B model.from lamini import Laminillm = Lamini(model_name=”meta-llama/Meta-Llama-3.1-8B-Instruct”)finetune_args = { “max_steps”: 50, “learning_rate”: 0.0001}llm.train( data_or_dataset_id=formatted_responses, finetune_args=finetune_args,) We can specify several hyperparameters, and you can find all the details in the Lamini documentation. For now, I’ve passed only the most essential ones to the function:max_steps: This determines the number of tuning steps. The documentation recommends using 50 steps for experimentation to get initial results without spending too much money.learning_rate: This parameter determines the step size of each iteration while moving toward a minimum of a loss function (Wikipedia). The default is 0.0009, but based on the guidance, I’ve decided to use a smaller value.Now, we just need to wait for 10–15 minutes while the model trains, and then we can test it.finetuned_llm = Lamini(model_name='<model_id>’)# you can find Model ID in the Lamini interfacequestion = ”’How many customers made purchase in December 2024?”’prompt = get_llama_prompt(question, generate_query_system_prompt)finetuned_llm.generate(prompt, max_new_tokens=200)# select uniqExact(s.user_id) as customers # from ecommerce.sessions s join ecommerce.users u # on s.user_id = u.user_id # where (toStartOfMonth(action_date) = ‘2024-12-01’) and (revenue > 0) # format TabSeparatedWithNamesIt’s worth noting that we’re using Lamini for inference as well and will have to pay for it. You can find up-to-date information about the costs here.At first glance, the result looks promising, but we need a more robust accuracy evaluation to confirm it.Additionally, it’s worth noting that since we’ve fine-tuned the model for our specific task, it now consistently returns SQL queries, meaning we may no longer need to use tool calls for structured output.Evaluating the qualityWe’ve discussed LLM accuracy evaluation in detail in my previous article, so here I’ll provide a brief recap.We use a golden set of question-and-answer pairs to evaluate the model’s quality. Since this is a toy example, I’ve limited the set to just 10 pairs, which you can review on GitHub.The evaluation process consists of two parts:SQL Query Validity: First, we check that the SQL query is valid, meaning ClickHouse doesn’t return errors during execution.Query Correctness: Next, we ensure that the generated query is correct. We compare the outputs of the generated and true queries using LLMs to verify that they provide semantically identical results.The initial results are far from ideal, but they are significantly better than the base Llama model (which produced zero valid SQL queries). Here’s what we found:ClickHouse returned errors for two queries.Three queries were executed, but the results were incorrect.Five queries were correct.No surprises — there’s no silver bullet, and it’s always an iterative process. Let’s investigate what went wrong.Diving into the errorsThe approach is straightforward. Let’s examine the errors one by one to understand why we got these results and how we can fix them. We’ll start with the first unsuccessful example.Question: Which country had the highest number of first-time users in 2024?Golden query:select country, count(distinct user_id) as users from ( select user_id, min(action_date) as first_date from ecommerce.sessions group by user_id having toStartOfYear(first_date) = ‘2024-01-01’ ) as t inner join ecommerce.users as u on t.user_id = u.user_id group by country order by users desc limit 1 format TabSeparatedWithNames Generated query:select country, count(distinct u.user_id) as first_time_users from ecommerce.sessions s join ecommerce.users u on s.user_id = u.user_id where (toStartOfYear(action_date) = ‘2024-01-01’) and (s.session_id = 1) group by country order by first_time_users desc limit 1 format TabSeparatedWithNames The query is valid, but it returns an incorrect result. The issue lies in the model’s assumption that the first session for each user will always have session_id = 1. Since Lamini Memory Tuning allows the model to learn facts from the training data, let’s investigate why the model made this assumption. Likely, it’s in our data.Let’s review all the examples that mention first. I’ll use broad and simple search criteria to get a high-level view.As we can see, there are no examples mentioning first-time users — only references to the first quarter. It’s no surprise that the model wasn’t able to capture this concept. The solution is straightforward: we just need to add a set of examples with questions and answers specifically about first-time users.Let’s move on to the next problematic case.Question: What was the fraud rate in 2023, expressed as a percentage?Golden query:select 100*uniqExactIf(user_id, is_fraud = 1)/uniqExact(user_id) as fraud_rate from ecommerce.sessions where (toStartOfYear(action_date) = ‘2023-01-01’) format TabSeparatedWithNames Generated query:select 100*countIf(is_fraud = 1)/count() as fraud_rate from ecommerce.sessions where (toStartOfYear(action_date) = ‘2023-01-01’) format TabSeparatedWithNames Here’s another misconception: we assumed that the fraud rate is based on the share of users, while the model calculated it based on the share of sessions.Let’s check the examples related to the fraud rate in the data. There are two cases: one calculates the share of users, while the other calculates the share of sessions.To fix this issue, I corrected the incorrect answer and added more accurate examples involving fraud rate calculations.I’d like to discuss another incorrect case, as it will highlight an important aspect of the process of resolving these issues.Question: What are the median and interquartile range (IQR) of purchase revenue for each country?Golden query:select country, median(revenue) as median_revenue, quantile(0.25)(revenue) as percentile_25_revenue, quantile(0.75)(revenue) as percentile_75_revenue from ecommerce.sessions AS s inner join ecommerce.users AS u on u.user_id = s.user_id where (revenue > 0) group by country format TabSeparatedWithNames Generated query:select country, median(revenue) as median_revenue, quantile(0.25)(revenue) as percentile_25_revenue, quantile(0.75)(revenue) as percentile_75_revenue from ecommerce.sessions s join ecommerce.users u on s.user_id = u.user_id group by country format TabSeparatedWithNames When inspecting the problem, it’s crucial to focus on the model’s misconceptions or incorrect assumptions. For example, in this case, there may be a temptation to add examples similar to those in the golden dataset, but that would be too specific. Instead, we should address the actual root cause of the model’s misconception:It understood the concepts of median and IQR quite well.The split by country is also correct.However, it misinterpreted the concept of “purchase revenue”, including sessions where there was no purchase at all (revenue = 0).So, we need to ensure that our datasets contain enough information related to purchase revenue. Let’s take a look at what we have now. There’s only one example, and it’s incorrect.Let’s fix this example and add more cases of purchase revenue calculations.Using a similar approach, I’ve added more examples for the two remaining incorrect queries and compiled an updated, cleaned version of the training dataset. You can find it on GitHub. With this, our data is ready to the next iteration.Another iteration of fine-tuningBefore diving into fine-tuning, it’s essential to double-check the quality of the training dataset by ensuring that all SQL queries are valid.clean_sample_dataset_df = pd.read_csv( ‘small_sample_for_finetuning_cleaned.csv’, sep = ‘t’, on_bad_lines = ‘warn’)clean_sample_dataset_df[‘output’] = clean_sample_dataset_df.sql_query .map(lambda x: get_clickhouse_data(str(x)))clean_sample_dataset_df[‘is_valid_output’] = clean_sample_dataset_df[‘output’] .map(is_valid_output)print(clean_sample_dataset_df.is_valid_output.value_counts())# is_valid_output# ok 241clean_formatted_responses = []for rec in clean_sample_dataset_df.to_dict(‘records’): clean_formatted_responses.append( { ‘input’: get_llama_prompt( rec[‘question’], generate_query_system_prompt), ‘output’: rec[‘sql_query’] } )Now that we’re confident in the data, we can proceed with fine-tuning. This time, I’ve decided to train it for 150 steps to achieve better accuracy.finetune_args = { “max_steps”: 150, “learning_rate”: 0.0001}llm = Lamini(model_name=”meta-llama/Meta-Llama-3.1-8B-Instruct”)llm.train( data_or_dataset_id=clean_formatted_responses, finetune_args=finetune_args)After waiting a bit longer than last time, we now have a new fine-tuned model with nearly zero loss after 150 tuning steps.We can run the evaluation again and see much better results. So, our approach is working.The result is astonishing, but it’s still worth examining the incorrect example to understand what went wrong. We got an incorrect result for the question we discussed earlier: “What are the median and interquartile range (IQR) of purchase revenue for each country?” However, this time, the model generated a query that is exactly identical to the one in the golden set.select country, median(revenue) as median_revenue, quantile(0.25)(revenue) as percentile_25_revenue, quantile(0.75)(revenue) as percentile_75_revenue from ecommerce.sessions AS s inner join ecommerce.users AS u on u.user_id = s.user_id where (s.revenue > 0) group by country format TabSeparatedWithNamesSo, the issue actually lies in our evaluation. In fact, if you try to execute this query multiple times, you’ll notice that the results are slightly different each time. The root cause is that the quantile function in ClickHouse computes approximate values using reservoir sampling, which is why we’re seeing varying results. We could have used quantileExact instead to get more consistent numbers.That said, this means that fine-tuning has allowed us to achieve 100% accuracy. Even though our toy golden dataset consists of just 10 questions, this is a tremendous achievement. We’ve progressed all the way from zero valid queries with vanilla Llama to 70% accuracy with RAG and self-reflection, and now, thanks to Lamini Memory Tuning, we’ve reached 100% accuracy.You can find the full code on GitHub.SummaryIn this article, we continued exploring techniques to improve LLM accuracy:After trying RAG and self-reflection in the previous article, we moved on to a more advanced technique — fine-tuning.We experimented with Memory Tuning developed by Lamini, which enables a model to remember a large volume of facts with near-zero errors.In our example, Memory Tuning performed exceptionally well, and we achieved 100% accuracy on our evaluation set of 10 questions.Thank you a lot for reading this article. I hope this article was insightful for you. If you have any follow-up questions or comments, please leave them in the comments section.ReferenceAll the images are produced by the author unless otherwise stated.This article is inspired by the “Improving Accuracy of LLM Applications” short course from DeepLearning.AI.Disclaimer: I am not affiliated with Lamini in any way. The views expressed in this article are solely my own, based on independent testing and evaluation of the Lamini platform. This post is intended for educational purposes and does not constitute an endorsement of any specific tool or service.The Next Frontier in LLM Accuracy was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. data-science, llm, artificial-intelligence, hands-on-tutorials, fine-tuning Towards Data Science – MediumRead More

 Add to favorites
Add to favorites


0 Comments