What I got right (and wrong) about trends in 2024 and daring to make bolder predictions for the year ahead

In 2023, building AI-powered applications felt full of promise, but the challenges were already starting to show. By 2024, we began experimenting with techniques to tackle the hard realities of making them work in production.
Last year, I reviewed the biggest trends in AI in 2023 and made predictions for 2024. This year, instead of a timeline, I want to focus on key themes: What trends emerged? Where did I get it wrong? And what can we expect for 2025?
2024 in Review
If I have to summarize the AI space in 2024, it would be the “Captain, it’s Wednesday” meme. The amount of major releases this year was overwhelming. I don’t blame anyone in this space who’s feeling exhausted towards the end of this year. It’s been a crazy ride, and it’s been hard to keep up. Let’s review key themes in the AI space and see if I correctly predicted them last year.
https://medium.com/media/c0e3c3bf8130f6cfc80109837ab4997f/href
Evaluations
Let’s start by looking at some generative AI solutions that made it to production. There aren’t many. As a survey by A16Z revealed in 2024, companies are still hesitant to deploy generative AI in customer-facing applications. Instead, they feel more confident using it for internal tasks, like document search or chatbots.
So, why aren’t there that many customer-facing generative AI applications in the wild? Probably because we are still figuring out how to evaluate them properly. This was one of my predictions for 2024.
Much of the research involved using another LLM to evaluate the output of an LLM (LLM-as-a-judge). While the approach may be clever, it’s also imperfect due to added cost, introduction of bias, and unreliability.
Looking back, I anticipated we would see this issue solved this year. However, looking at the landscape today, despite being a major topic of discussion, we still haven’t found a reliable way to evaluate generative AI solutions effectively. Although I think LLM-as-a-judge is the only way we’re able to evaluate generative AI solutions at scale, this shows how early we are in this field.
Multimodality
Although this one might have been obvious to many of you, I didn’t have this on my radar for 2024. With the releases of GPT4, Llama 3.2, and ColPali, multimodal foundation models were a big trend in 2024. While we, developers, were busy figuring out how to make LLMs work in our existing pipelines, researchers were already one step ahead. They were already building foundation models that could handle more than one modality.
“There is *absolutely no way in hell* we will ever reach human-level AI without getting machines to learn from high-bandwidth sensory inputs, such as vision.” — Yann LeCun
Take PDF parsing as an example of multimodal models’ usefulness beyond text-to-image tasks. ColPali’s researchers avoided the difficult steps of OCR and layout extraction by using visual language models (VLMs). Systems like ColPali and ColQwen2 process PDFs as images, extracting information directly without pre-processing or chunking. This is a reminder that simpler solutions often come from changing how you frame the problem.
Multimodal models are a bigger shift than they might seem. Document search across PDFs is just the beginning. Multimodality in foundation models will unlock entirely new possibilities for applications across industries. With more modalities, AI is no longer just about language — it’s about understanding the world.
Fine-tuning open-weight models and quantization
Open-weight models are closing the performance gap to closed models. Fine-tuning them gives you a performance boost while still being lightweight. Quantization makes these models smaller and more efficient (see also Green AI) to run anywhere, even on small devices. Quantization pairs well with fine-tuning, especially since fine-tuning language models is inherently challenging (see QLoRA).
Together, these trends make it clear that the future isn’t just bigger models — it’s smarter ones.
https://medium.com/media/8ec8db1e6ce5401145753360f0d2f64d/href
I don’t think I explicitly mentioned this one and only wrote a small piece on this in the second quarter of 2024. So, I will not give myself a point here.
AI agents
This year, AI agents and agentic workflows gained much attention, as Andrew Ng predicted at the beginning of the year. We saw Langchain and LlamaIndex move into incorporating agents, CrewAI gained a lot of momentum, and OpenAI came out with Swarm. This is another topic I hadn’t seen coming since I didn’t look into it.
“I think AI agentic workflows will drive massive AI progress this year — perhaps even more than the next generation of foundation models.” — Andrew Ng
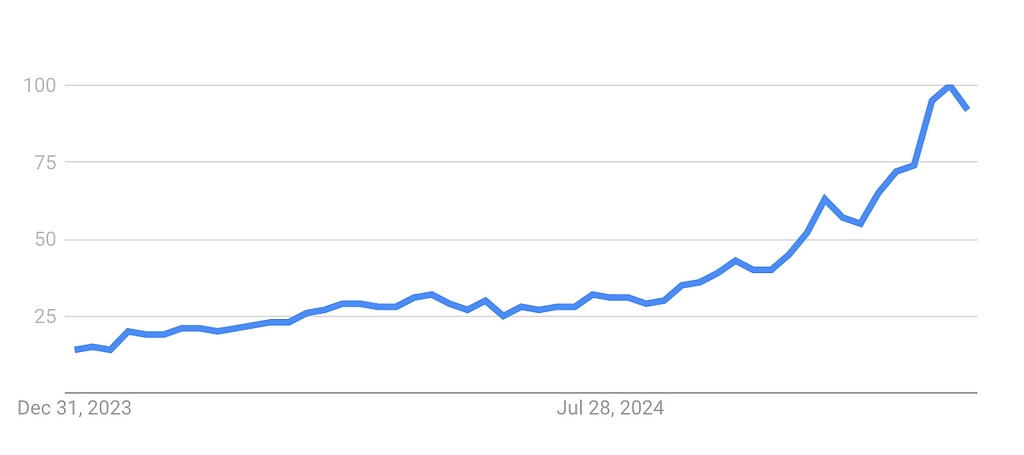
Despite the massive interest in AI agents, they can be controversial. First, there is still no clear definition of “AI agent” and its capabilities. Are AI agents just LLMs with access to tools, or do they have other specific capabilities? Second, they come with added latency and cost. I have read many comments saying that agent systems aren’t suitable for production systems due to this.
But I think we have already been seeing some agentic pipelines in production with lightweight workflows, such as routing user queries to specific function calls. I think we will continue to see agents in 2025. Hopefully, we will get a clearer definition and picture.
RAG isn’t de*d and retrieval goes mainstream
Retrieval-Augmented Generation (RAG) gained significant attention in 2023 and remained a key topic in 2024, with many new variants emerging. However, it remains a topic of debate. Some argue it’s becoming obsolete with long-context models, while others question whether it’s even a new idea. While I think the criticism of the terminology is justified, I think the concept is here to stay (for a little while at least).
https://medium.com/media/777a461a8ac553c94480911a25237210/href
Every time a new long context model is released, some people predict it will be the end of RAG pipelines. I don’t think that’s going to happen. This whole discussion should be a blog post of its own, so I’m not going into depth here and saving the discussion for another one. Let me just say that I don’t think it’s one or the other. They are complements. Instead, we will probably be using long context models together with RAG pipelines.
Also, having a database in applications is not a new concept. The term ‘RAG,’ which refers to retrieving information from a knowledge source to enhance an LLM’s output, has faced criticism. Some argue it’s merely a rebranding of techniques long used in other fields, such as software engineering. While I think we will probably part from the term in the long run, the technique is here to stay.
Despite predictions of RAG’s demise, retrieval remains a cornerstone of AI pipelines. While I may be biased by my work in retrieval, it felt like this topic became more mainstream in AI this year. It started with many discussions around keyword search (BM25) as a baseline for RAG pipelines. It then evolved into a larger discussion around dense retrieval models, such as ColBERT or ColPali.
Knowledge graphs
I completely missed this topic because I’m not too familiar with it. Knowledge graphs in RAG systems (e.g., Graph RAG) were another big topic. Since all I can say about knowledge graphs at this moment is that they seem to be a powerful external knowledge source, I will keep this section short.
The key topics of 2024 suggest that we are now realizing the limitations of building applications with foundation models. The hype around ChatGPT may have settled, but the drive to integrate foundation models into applications is still very much alive. It’s just way more difficult than we had anticipated.
“ The race to make AI more efficient and more useful, before investors lose their enthusiasm, is on.” — The Economist
2024 taught us that scaling foundation models isn’t enough. We need better evaluation, smarter retrieval, and more efficient workflows to make AI useful. The limitations we ran into this year aren’t signs of stagnation — they’re clues about what we need to fix next in 2025.
My 2025 Predictions
OK, now, for the interesting part, what are my 2025 predictions? This year, I want to make some bolder predictions for the next year to make it a little more fun:
- Video will be an important modality: After text-only LLMs evolved into multimodal foundation models (mostly text and images), it’s only natural that video will be the next modality. I can imagine seeing more video-capable foundation models follow in Sora’s footsteps.
- From one-shot to agentic to human-in-the-loop: I imagine we will start incorporating humans into AI-powered systems. While we started with one-shot systems, we are not at the stage of having AI agents coordinate different tasks to improve results. But AI agents won’t replace humans. They’ll empower them. Systems that incorporate human feedback will deliver better outcomes across industries. In the long-term, I imagine that we will have to have systems that wait for human feedback before taking action on the next task.
- Fusion of AI and crypto: Admittedly, I don’t know much about the entire crypto scene, but I saw this Tweet by Brian Armstrong about how AI agents should be equipped with crypto wallets. Also, concepts like DePin (Decentralized Physical Infrastructure) could be interesting to explore for model training and inference. While this sounds like buzzword bingo, I’m curious to see if early experiments will show if this is hype or reality.
- Latency and cost per token will drop: Currently, one big issue for AI agents is added latency and cost. However, with Moore’s law and research for making AI models more efficient, like quantization and efficient training techniques (not only for cost reasons but also for environmental reasons), I can imagine both the latency and cost per token going down.
I am curious to hear your predictions for the AI space in 2025!
PS: Funnily, I was researching recipes for Christmas cookies with ChatGPT a few days ago instead of using Google, which I was wondering about two years ago when ChatGPT was released.
Will We Be Using ChatGPT Instead of Google To Get a Christmas Cookie Recipe Next Year?
Enjoyed This Story?
Subscribe for free to get notified when I publish a new story.
Get an email whenever Leonie Monigatti publishes.
Find me on LinkedIn, Twitter, and Kaggle!
2024 in Review: What I Got Right, Where I Was Wrong, and Bolder Predictions for 2025 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
What I got right (and wrong) about trends in 2024 and daring to make bolder predictions for the year aheadAI Buzzword and Trend Bingo (Image by the author)In 2023, building AI-powered applications felt full of promise, but the challenges were already starting to show. By 2024, we began experimenting with techniques to tackle the hard realities of making them work in production.Last year, I reviewed the biggest trends in AI in 2023 and made predictions for 2024. This year, instead of a timeline, I want to focus on key themes: What trends emerged? Where did I get it wrong? And what can we expect for 2025?2024 in ReviewIf I have to summarize the AI space in 2024, it would be the “Captain, it’s Wednesday” meme. The amount of major releases this year was overwhelming. I don’t blame anyone in this space who’s feeling exhausted towards the end of this year. It’s been a crazy ride, and it’s been hard to keep up. Let’s review key themes in the AI space and see if I correctly predicted them last year.https://medium.com/media/c0e3c3bf8130f6cfc80109837ab4997f/hrefEvaluationsLet’s start by looking at some generative AI solutions that made it to production. There aren’t many. As a survey by A16Z revealed in 2024, companies are still hesitant to deploy generative AI in customer-facing applications. Instead, they feel more confident using it for internal tasks, like document search or chatbots.So, why aren’t there that many customer-facing generative AI applications in the wild? Probably because we are still figuring out how to evaluate them properly. This was one of my predictions for 2024.Much of the research involved using another LLM to evaluate the output of an LLM (LLM-as-a-judge). While the approach may be clever, it’s also imperfect due to added cost, introduction of bias, and unreliability.Looking back, I anticipated we would see this issue solved this year. However, looking at the landscape today, despite being a major topic of discussion, we still haven’t found a reliable way to evaluate generative AI solutions effectively. Although I think LLM-as-a-judge is the only way we’re able to evaluate generative AI solutions at scale, this shows how early we are in this field.MultimodalityAlthough this one might have been obvious to many of you, I didn’t have this on my radar for 2024. With the releases of GPT4, Llama 3.2, and ColPali, multimodal foundation models were a big trend in 2024. While we, developers, were busy figuring out how to make LLMs work in our existing pipelines, researchers were already one step ahead. They were already building foundation models that could handle more than one modality.“There is *absolutely no way in hell* we will ever reach human-level AI without getting machines to learn from high-bandwidth sensory inputs, such as vision.” — Yann LeCunTake PDF parsing as an example of multimodal models’ usefulness beyond text-to-image tasks. ColPali’s researchers avoided the difficult steps of OCR and layout extraction by using visual language models (VLMs). Systems like ColPali and ColQwen2 process PDFs as images, extracting information directly without pre-processing or chunking. This is a reminder that simpler solutions often come from changing how you frame the problem.Multimodal models are a bigger shift than they might seem. Document search across PDFs is just the beginning. Multimodality in foundation models will unlock entirely new possibilities for applications across industries. With more modalities, AI is no longer just about language — it’s about understanding the world.Fine-tuning open-weight models and quantizationOpen-weight models are closing the performance gap to closed models. Fine-tuning them gives you a performance boost while still being lightweight. Quantization makes these models smaller and more efficient (see also Green AI) to run anywhere, even on small devices. Quantization pairs well with fine-tuning, especially since fine-tuning language models is inherently challenging (see QLoRA).Together, these trends make it clear that the future isn’t just bigger models — it’s smarter ones.https://medium.com/media/8ec8db1e6ce5401145753360f0d2f64d/hrefI don’t think I explicitly mentioned this one and only wrote a small piece on this in the second quarter of 2024. So, I will not give myself a point here.AI agentsThis year, AI agents and agentic workflows gained much attention, as Andrew Ng predicted at the beginning of the year. We saw Langchain and LlamaIndex move into incorporating agents, CrewAI gained a lot of momentum, and OpenAI came out with Swarm. This is another topic I hadn’t seen coming since I didn’t look into it.“I think AI agentic workflows will drive massive AI progress this year — perhaps even more than the next generation of foundation models.” — Andrew NgScreenshot from Google Trends for the term “AI agents” in 2024.Despite the massive interest in AI agents, they can be controversial. First, there is still no clear definition of “AI agent” and its capabilities. Are AI agents just LLMs with access to tools, or do they have other specific capabilities? Second, they come with added latency and cost. I have read many comments saying that agent systems aren’t suitable for production systems due to this.But I think we have already been seeing some agentic pipelines in production with lightweight workflows, such as routing user queries to specific function calls. I think we will continue to see agents in 2025. Hopefully, we will get a clearer definition and picture.RAG isn’t de*d and retrieval goes mainstreamRetrieval-Augmented Generation (RAG) gained significant attention in 2023 and remained a key topic in 2024, with many new variants emerging. However, it remains a topic of debate. Some argue it’s becoming obsolete with long-context models, while others question whether it’s even a new idea. While I think the criticism of the terminology is justified, I think the concept is here to stay (for a little while at least).https://medium.com/media/777a461a8ac553c94480911a25237210/hrefEvery time a new long context model is released, some people predict it will be the end of RAG pipelines. I don’t think that’s going to happen. This whole discussion should be a blog post of its own, so I’m not going into depth here and saving the discussion for another one. Let me just say that I don’t think it’s one or the other. They are complements. Instead, we will probably be using long context models together with RAG pipelines.Also, having a database in applications is not a new concept. The term ‘RAG,’ which refers to retrieving information from a knowledge source to enhance an LLM’s output, has faced criticism. Some argue it’s merely a rebranding of techniques long used in other fields, such as software engineering. While I think we will probably part from the term in the long run, the technique is here to stay.Despite predictions of RAG’s demise, retrieval remains a cornerstone of AI pipelines. While I may be biased by my work in retrieval, it felt like this topic became more mainstream in AI this year. It started with many discussions around keyword search (BM25) as a baseline for RAG pipelines. It then evolved into a larger discussion around dense retrieval models, such as ColBERT or ColPali.Knowledge graphsI completely missed this topic because I’m not too familiar with it. Knowledge graphs in RAG systems (e.g., Graph RAG) were another big topic. Since all I can say about knowledge graphs at this moment is that they seem to be a powerful external knowledge source, I will keep this section short.The key topics of 2024 suggest that we are now realizing the limitations of building applications with foundation models. The hype around ChatGPT may have settled, but the drive to integrate foundation models into applications is still very much alive. It’s just way more difficult than we had anticipated.“ The race to make AI more efficient and more useful, before investors lose their enthusiasm, is on.” — The Economist2024 taught us that scaling foundation models isn’t enough. We need better evaluation, smarter retrieval, and more efficient workflows to make AI useful. The limitations we ran into this year aren’t signs of stagnation — they’re clues about what we need to fix next in 2025.My 2025 PredictionsOK, now, for the interesting part, what are my 2025 predictions? This year, I want to make some bolder predictions for the next year to make it a little more fun:Video will be an important modality: After text-only LLMs evolved into multimodal foundation models (mostly text and images), it’s only natural that video will be the next modality. I can imagine seeing more video-capable foundation models follow in Sora’s footsteps.From one-shot to agentic to human-in-the-loop: I imagine we will start incorporating humans into AI-powered systems. While we started with one-shot systems, we are not at the stage of having AI agents coordinate different tasks to improve results. But AI agents won’t replace humans. They’ll empower them. Systems that incorporate human feedback will deliver better outcomes across industries. In the long-term, I imagine that we will have to have systems that wait for human feedback before taking action on the next task.Fusion of AI and crypto: Admittedly, I don’t know much about the entire crypto scene, but I saw this Tweet by Brian Armstrong about how AI agents should be equipped with crypto wallets. Also, concepts like DePin (Decentralized Physical Infrastructure) could be interesting to explore for model training and inference. While this sounds like buzzword bingo, I’m curious to see if early experiments will show if this is hype or reality.Latency and cost per token will drop: Currently, one big issue for AI agents is added latency and cost. However, with Moore’s law and research for making AI models more efficient, like quantization and efficient training techniques (not only for cost reasons but also for environmental reasons), I can imagine both the latency and cost per token going down.I am curious to hear your predictions for the AI space in 2025!PS: Funnily, I was researching recipes for Christmas cookies with ChatGPT a few days ago instead of using Google, which I was wondering about two years ago when ChatGPT was released.Will We Be Using ChatGPT Instead of Google To Get a Christmas Cookie Recipe Next Year?Enjoyed This Story?Subscribe for free to get notified when I publish a new story.Get an email whenever Leonie Monigatti publishes.Find me on LinkedIn, Twitter, and Kaggle!2024 in Review: What I Got Right, Where I Was Wrong, and Bolder Predictions for 2025 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. data-science, notes-from-industry, machine-learning, technology, artificial-intelligence Towards Data Science – MediumRead More

 Add to favorites
Add to favorites


0 Comments