Three Zero-Cost Solutions That Take Hours, Not Months

In my career, data quality initiatives have usually meant big changes. From governance processes to costly tools to dbt implementation — data quality projects never seem to want to be small.
What’s more, fixing the data quality issues this way often leads to new problems. More complexity, higher costs, slower data project releases…
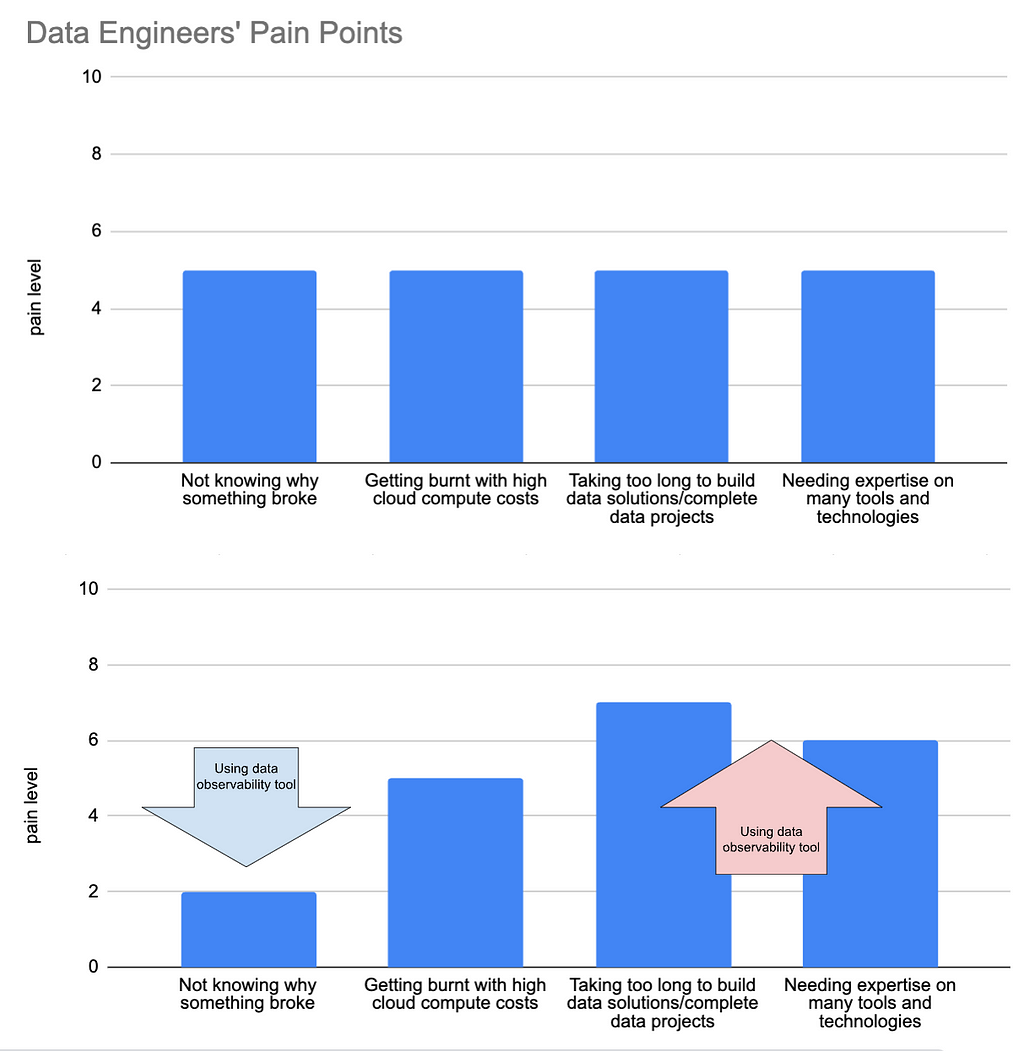
But it doesn’t have to be this way.
Some of the most effective methods to cut down on data issues are also some of the most simple.
In this article, we’ll delve into three methods to quickly improve your company’s data quality, all while keeping complexity to a minimum and new costs at zero. Let’s get to it!
TL;DR
- Take advantage of old school database tricks, like ENUM data types, and column constraints.
- Create a custom dashboard for your specific data quality problem.
- Generate data lineage with one small Python script.
Take advantage of old school database tricks
In the last 10–15 years we’ve seen massive changes to the data industry, notably big data, parallel processing, cloud computing, data warehouses, and new tools (lots and lots of new tools).
Consequently, we’ve had to say goodbye to some things to make room for all this new stuff. Some positives (Microsoft Access comes to mind), but some are questionable at best, such as traditional data design principles and data quality and validation at ingestion. The latter will be the subject of this section.
Firstly, what do I mean by “data quality and validation at ingestion”? Simply, it means checking data before it enters a table. Think of a bouncer outside a nightclub.
What it has been replaced with is build-then-test, which means putting new data in tables first, and then checking it later. Build-then-test is the chosen method for many modern data quality tools, including the most popular, dbt.
Dbt runs the whole data transformation pipeline first, and only once all the new data is in place, it checks to see if the data is good. Of course, this can be the optimal solution in many cases. For example, if the business is happy to sacrifice quality for speed, or if there is a QA table before a production table (coined by Netflix as Write-Audit-Publish). However, engineers who only use this method of data quality are potentially missing out on some big wins for their organization.
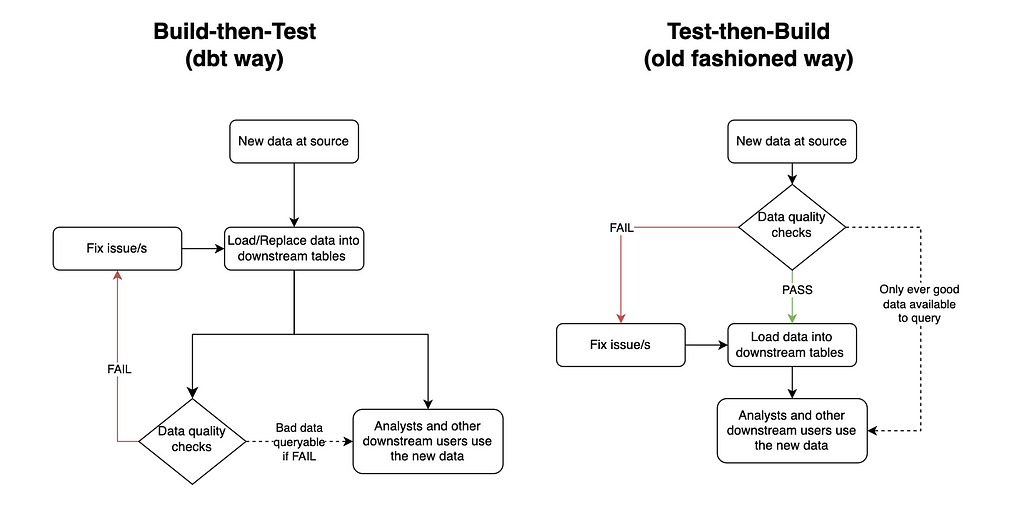
Test-then-build has two main benefits over build-then-test.
The first is that it ensures the data in downstream tables meets the data quality standards expected at all times. This gives the data a level of trustworthiness, so often lacking, for downstream users. It can also reduce anxiety for the data engineer/s responsible for the pipeline.
I remember when I owned a key financial pipeline for a company I used to work for. Unfortunately, this pipeline was very prone to data quality issues, and the solution in place was a build-then-test system, which ran each night. This meant I needed to rush to my station early in the morning each day to check the results of the run before any downstream users started looking at their data. If there were any issues I then needed to either quickly fix the issue or send a Slack message of shame announcing to the business the data sucks and to please be patient while I fix it.
Of course, test-then-build doesn’t totally fix this anxiety issue. The story would change from needing to rush to fix the issue to avoid bad data for downstream users to rushing to fix the issue to avoid stale data for downstream users. However, engineering is all about weighing the pros and cons of different solutions. And in this scenario I know old data would have been the best of two evils for both the business and my sanity.
The second benefit test-then-build has is that it can be much simpler to implement, especially compared to setting up a whole QA area, which is a bazooka-to-a-bunny solution for solving most data quality issues. All you need to do is include your data quality criteria when you create the table. Have a look at the below PostgreSQL query:
CREATE TYPE currency_code_type AS ENUM (
'USD', -- United States Dollar
'EUR', -- Euro
'GBP', -- British Pound Sterling
'JPY', -- Japanese Yen
'CAD', -- Canadian Dollar
'AUD', -- Australian Dollar
'CNY', -- Chinese Yuan
'INR', -- Indian Rupee
'BRL', -- Brazilian Real
'MXN' -- Mexican Peso
);
CREATE TYPE payment_status AS ENUM (
'pending',
'completed',
'failed',
'refunded',
'partially_refunded',
'disputed',
'canceled'
);
CREATE TABLE daily_revenue (
id INTEGER PRIMARY KEY,
date DATE NOT NULL,
revenue_source revenue_source_type NOT NULL,
gross_amount NUMERIC(15,2) NOT NULL CHECK (gross_amount >= 0),
net_amount NUMERIC(15,2) NOT NULL CHECK (net_amount >= 0),
currency currency_code_type,
transaction_count INTEGER NOT NULL CHECK (transaction_count >= 0),
notes TEXT,
CHECK (net_amount <= gross_amount),
CHECK (gross_amount >= processing_fees + tax_amount),
CHECK (date <= CURRENT_DATE),
CONSTRAINT unique_daily_source UNIQUE (date, revenue_source)
);
These 14 lines of code will ensure the daily_revenue table enforces the following standards:
id
- Primary key constraint ensures uniqueness.
date
- Cannot be a future date (via CHECK constraint).
- Forms part of a unique constraint with revenue_source.
revenue_source
- Cannot be NULL.
- Forms part of a unique constraint with date.
- Must be a valid value from revenue_source_type enum.
gross_amount
- Cannot be NULL.
- Must be >= 0.
- Must be >= processing_fees + tax_amount.
- Must be >= net_amount.
- Precise decimal handling.
net_amount
- Cannot be NULL.
- Must be >= 0.
- Must be <= gross_amount.
- Precise decimal handling.
currency
- Must be a valid value from currency_code_type enum.
transaction_count
- Cannot be NULL.
- Must be >= 0.
It’s simple. Reliable. And would you believe all of this was available to us since the release of PostgreSQL 6.5… which came out in 1999!
Of course there’s no such thing as a free lunch. Enforcing constraints this way does have its drawbacks. For example, it makes the table a lot less flexible, and it will reduce the performance when updating the table. As always, you need to think like an engineer before diving into any tool/technology/method.
Create a custom dashboard
I have a confession to make. I used to think good data engineers didn’t use dashboard tools to solve their problems. I thought a real engineer looks at logs, hard-to-read code, and whatever else made them look smart if someone ever glanced at their computer screen.
I was dumb.
It turns out they can be really valuable if executed effectively for a clear purpose. Furthermore, most BI tools make creating dashboards super easy and quick, without (too) much time spent learning the tool.
Back to my personal pipeline experiences. I used to manage a daily aggregated table of all the business’ revenue sources. Each source came from a different revenue provider, and as such a different system. Some would be via API calls, others via email, and others via a shared S3 bucket. As any engineer would expect, some of these sources fell over from time-to-time, and because they came from third parties, I couldn’t fix the issue at source (only ask, which had very limited success).
Originally, I had only used failure logs to determine where things needed fixing. The problem was priority. Some failures needed quickly fixing, while others were not important enough to drop everything for (we had some revenue sources that literally reported pennies each day). As a result, there was a build up of small data quality issues, which became difficult to keep track of.
Enter Tableau.
I created a very basic dashboard that highlighted metadata by revenue source and date for the last 14 days. Three metrics were all I needed:
- A green or red mark indicating whether data was present or missing.
- The row count of the data.
- The sum of revenue of the data.
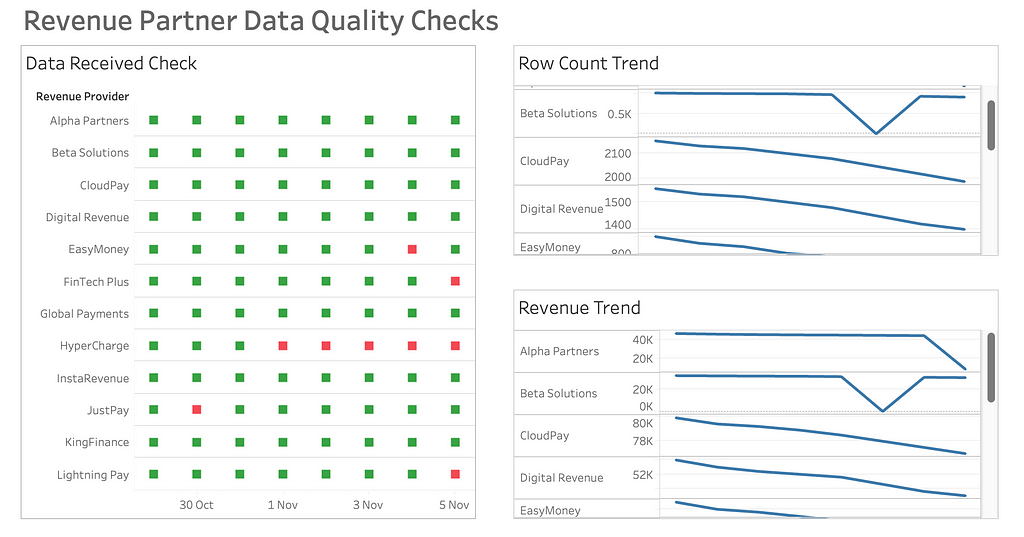
This made the pipeline’s data quality a whole lot easier to manage. Not only was it much quicker for me to glance at where the issues were, but it was user-friendly enough for other people to read from too, allowing for shared responsibility.
After implementing the dashboard, bug tickets reported by the business related to the pipeline dropped to virtually zero, as did my risk of a stroke.
Map your data with a lineage chart
Simple data observability solutions don’t just stop at dashboards.
Data lineage can be a dream for quickly spotting what tables have been affected by bad data upstream.
However, it can also be a mammoth task to implement.
The number one culprit for this, in my opinion, is dbt. A key selling point of the open-source tool is its data lineage capabilities. But to achieve this you have to bow down to dbt’s framework. Including, but not limited to:
- Implementing Jinja3 in all you SQL files.
- Creating a YAML file for each data model.
- Add Source data configuration via YAML files.
- Set up a development and testing process e.g. development environment, version control, CI/CD.
- Infrastructure set-up e.g. hosting your own server or purchasing a managed version (dbtCloud).
Yeah, it’s a lot.
But it doesn’t have to be. Ultimately, all you need for dynamic data lineage is a machine that scans your SQL files, and something to output a user-friendly lineage map. Thanks to Python, this can be achieved using a script with as few as 100 lines of code.
If you know a bit of Python and LLM prompting you should be able to hack the code in an hour. Alternatively, there’s a lightweight open-source Python tool called SQL-WatchPup that already has the code.
Provided you have all your SQL files available, in 15 minutes of set up you should be able to generate dynamic data lineage maps like so:
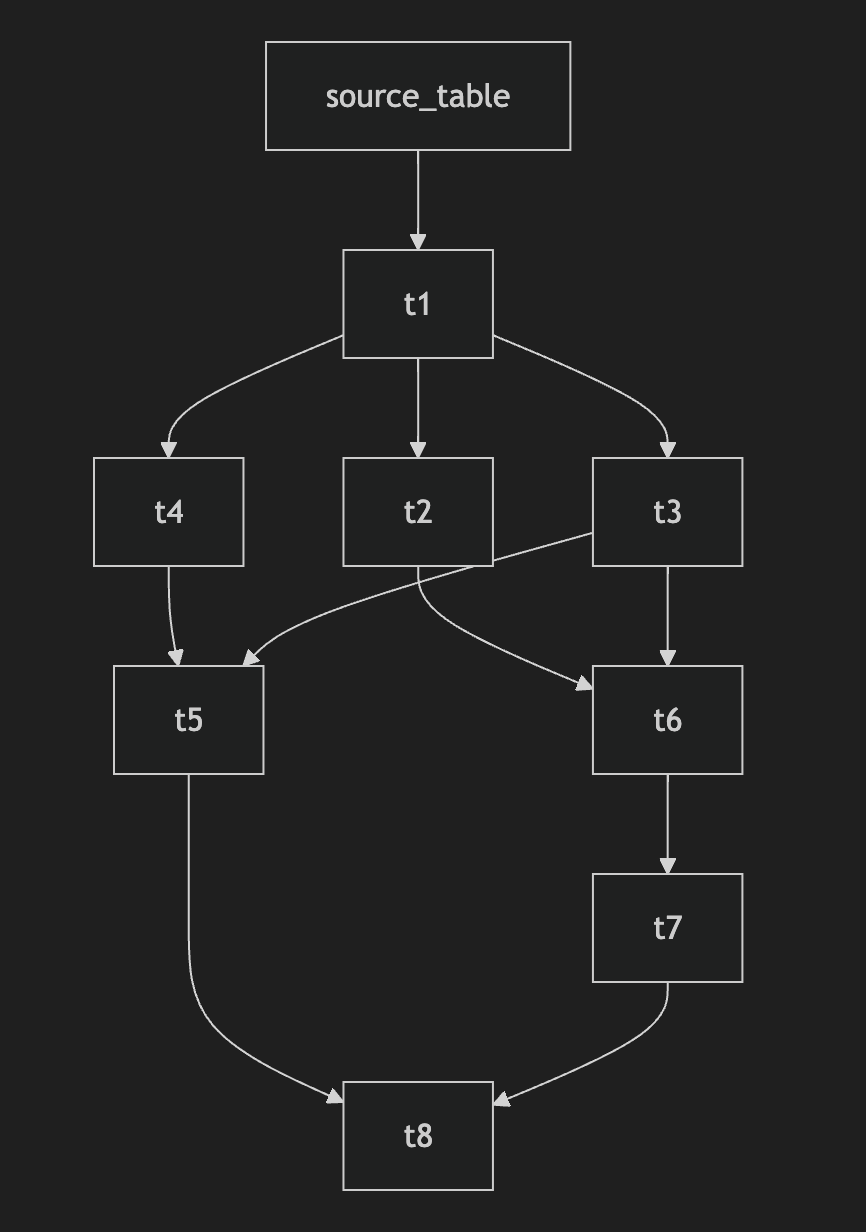
That’s it. No server hosting costs. No extra computer languages to learn. No restructuring of your files. Just running one simple Python script locally.
Conclusion
Let’s face it — we all love shiny new in-vogue tools, but sometimes the best solutions are old, uncool, and/or unpopular.
The next time you’re faced with data quality headaches, take a step back before diving into that massive infrastructure overhaul. Ask yourself: Could a simple database constraint, a basic dashboard, or a lightweight Python script do the trick?
Your sanity will thank you for it. Your company’s budget will too.
Stop Overcomplicating Data Quality was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Three Zero-Cost Solutions That Take Hours, Not MonthsA ‘data quality’ certified pipeline. Source: unsplash.comIn my career, data quality initiatives have usually meant big changes. From governance processes to costly tools to dbt implementation — data quality projects never seem to want to be small.What’s more, fixing the data quality issues this way often leads to new problems. More complexity, higher costs, slower data project releases…created by the author using Google SheetsBut it doesn’t have to be this way.Some of the most effective methods to cut down on data issues are also some of the most simple.In this article, we’ll delve into three methods to quickly improve your company’s data quality, all while keeping complexity to a minimum and new costs at zero. Let’s get to it!TL;DRTake advantage of old school database tricks, like ENUM data types, and column constraints.Create a custom dashboard for your specific data quality problem.Generate data lineage with one small Python script.Take advantage of old school database tricksIn the last 10–15 years we’ve seen massive changes to the data industry, notably big data, parallel processing, cloud computing, data warehouses, and new tools (lots and lots of new tools).Consequently, we’ve had to say goodbye to some things to make room for all this new stuff. Some positives (Microsoft Access comes to mind), but some are questionable at best, such as traditional data design principles and data quality and validation at ingestion. The latter will be the subject of this section.Firstly, what do I mean by “data quality and validation at ingestion”? Simply, it means checking data before it enters a table. Think of a bouncer outside a nightclub.What it has been replaced with is build-then-test, which means putting new data in tables first, and then checking it later. Build-then-test is the chosen method for many modern data quality tools, including the most popular, dbt.Dbt runs the whole data transformation pipeline first, and only once all the new data is in place, it checks to see if the data is good. Of course, this can be the optimal solution in many cases. For example, if the business is happy to sacrifice quality for speed, or if there is a QA table before a production table (coined by Netflix as Write-Audit-Publish). However, engineers who only use this method of data quality are potentially missing out on some big wins for their organization.Testing before vs after generating tables. Created by the author using draw.ioTest-then-build has two main benefits over build-then-test.The first is that it ensures the data in downstream tables meets the data quality standards expected at all times. This gives the data a level of trustworthiness, so often lacking, for downstream users. It can also reduce anxiety for the data engineer/s responsible for the pipeline.I remember when I owned a key financial pipeline for a company I used to work for. Unfortunately, this pipeline was very prone to data quality issues, and the solution in place was a build-then-test system, which ran each night. This meant I needed to rush to my station early in the morning each day to check the results of the run before any downstream users started looking at their data. If there were any issues I then needed to either quickly fix the issue or send a Slack message of shame announcing to the business the data sucks and to please be patient while I fix it.Of course, test-then-build doesn’t totally fix this anxiety issue. The story would change from needing to rush to fix the issue to avoid bad data for downstream users to rushing to fix the issue to avoid stale data for downstream users. However, engineering is all about weighing the pros and cons of different solutions. And in this scenario I know old data would have been the best of two evils for both the business and my sanity.The second benefit test-then-build has is that it can be much simpler to implement, especially compared to setting up a whole QA area, which is a bazooka-to-a-bunny solution for solving most data quality issues. All you need to do is include your data quality criteria when you create the table. Have a look at the below PostgreSQL query:CREATE TYPE currency_code_type AS ENUM ( ‘USD’, — United States Dollar ‘EUR’, — Euro ‘GBP’, — British Pound Sterling ‘JPY’, — Japanese Yen ‘CAD’, — Canadian Dollar ‘AUD’, — Australian Dollar ‘CNY’, — Chinese Yuan ‘INR’, — Indian Rupee ‘BRL’, — Brazilian Real ‘MXN’ — Mexican Peso);CREATE TYPE payment_status AS ENUM ( ‘pending’, ‘completed’, ‘failed’, ‘refunded’, ‘partially_refunded’, ‘disputed’, ‘canceled’);CREATE TABLE daily_revenue ( id INTEGER PRIMARY KEY, date DATE NOT NULL, revenue_source revenue_source_type NOT NULL, gross_amount NUMERIC(15,2) NOT NULL CHECK (gross_amount >= 0), net_amount NUMERIC(15,2) NOT NULL CHECK (net_amount >= 0), currency currency_code_type, transaction_count INTEGER NOT NULL CHECK (transaction_count >= 0), notes TEXT, CHECK (net_amount <= gross_amount), CHECK (gross_amount >= processing_fees + tax_amount), CHECK (date <= CURRENT_DATE), CONSTRAINT unique_daily_source UNIQUE (date, revenue_source)); These 14 lines of code will ensure the daily_revenue table enforces the following standards:idPrimary key constraint ensures uniqueness.dateCannot be a future date (via CHECK constraint).Forms part of a unique constraint with revenue_source.revenue_sourceCannot be NULL.Forms part of a unique constraint with date.Must be a valid value from revenue_source_type enum.gross_amountCannot be NULL.Must be >= 0.Must be >= processing_fees + tax_amount.Must be >= net_amount.Precise decimal handling.net_amountCannot be NULL.Must be >= 0.Must be <= gross_amount.Precise decimal handling.currencyMust be a valid value from currency_code_type enum.transaction_countCannot be NULL.Must be >= 0.It’s simple. Reliable. And would you believe all of this was available to us since the release of PostgreSQL 6.5… which came out in 1999!Of course there’s no such thing as a free lunch. Enforcing constraints this way does have its drawbacks. For example, it makes the table a lot less flexible, and it will reduce the performance when updating the table. As always, you need to think like an engineer before diving into any tool/technology/method.Create a custom dashboardI have a confession to make. I used to think good data engineers didn’t use dashboard tools to solve their problems. I thought a real engineer looks at logs, hard-to-read code, and whatever else made them look smart if someone ever glanced at their computer screen.I was dumb.It turns out they can be really valuable if executed effectively for a clear purpose. Furthermore, most BI tools make creating dashboards super easy and quick, without (too) much time spent learning the tool.Back to my personal pipeline experiences. I used to manage a daily aggregated table of all the business’ revenue sources. Each source came from a different revenue provider, and as such a different system. Some would be via API calls, others via email, and others via a shared S3 bucket. As any engineer would expect, some of these sources fell over from time-to-time, and because they came from third parties, I couldn’t fix the issue at source (only ask, which had very limited success).Originally, I had only used failure logs to determine where things needed fixing. The problem was priority. Some failures needed quickly fixing, while others were not important enough to drop everything for (we had some revenue sources that literally reported pennies each day). As a result, there was a build up of small data quality issues, which became difficult to keep track of.Enter Tableau.I created a very basic dashboard that highlighted metadata by revenue source and date for the last 14 days. Three metrics were all I needed:A green or red mark indicating whether data was present or missing.The row count of the data.The sum of revenue of the data.A simple yet effective dashboard. Created by the author using TableauThis made the pipeline’s data quality a whole lot easier to manage. Not only was it much quicker for me to glance at where the issues were, but it was user-friendly enough for other people to read from too, allowing for shared responsibility.After implementing the dashboard, bug tickets reported by the business related to the pipeline dropped to virtually zero, as did my risk of a stroke.Map your data with a lineage chartSimple data observability solutions don’t just stop at dashboards.Data lineage can be a dream for quickly spotting what tables have been affected by bad data upstream.However, it can also be a mammoth task to implement.The number one culprit for this, in my opinion, is dbt. A key selling point of the open-source tool is its data lineage capabilities. But to achieve this you have to bow down to dbt’s framework. Including, but not limited to:Implementing Jinja3 in all you SQL files.Creating a YAML file for each data model.Add Source data configuration via YAML files.Set up a development and testing process e.g. development environment, version control, CI/CD.Infrastructure set-up e.g. hosting your own server or purchasing a managed version (dbtCloud).Yeah, it’s a lot.But it doesn’t have to be. Ultimately, all you need for dynamic data lineage is a machine that scans your SQL files, and something to output a user-friendly lineage map. Thanks to Python, this can be achieved using a script with as few as 100 lines of code.If you know a bit of Python and LLM prompting you should be able to hack the code in an hour. Alternatively, there’s a lightweight open-source Python tool called SQL-WatchPup that already has the code.Provided you have all your SQL files available, in 15 minutes of set up you should be able to generate dynamic data lineage maps like so:Example data lineage map output. Created by the author using SQL-WatchPupThat’s it. No server hosting costs. No extra computer languages to learn. No restructuring of your files. Just running one simple Python script locally.ConclusionLet’s face it — we all love shiny new in-vogue tools, but sometimes the best solutions are old, uncool, and/or unpopular.The next time you’re faced with data quality headaches, take a step back before diving into that massive infrastructure overhaul. Ask yourself: Could a simple database constraint, a basic dashboard, or a lightweight Python script do the trick?Your sanity will thank you for it. Your company’s budget will too.Stop Overcomplicating Data Quality was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. data-quality, dbt, tips-and-tricks, data-engineering, tableau Towards Data Science – MediumRead More

 Add to favorites
Add to favorites


0 Comments