An end-to-end guide covering integration with the Sleeper API, creation of a Streamlit UI, and deployment via AWS CDK

It’s embarrassing how much time I spend thinking about my fantasy football team.
Managing a squad means processing a firehose of information — injury reports, expert projections, upcoming bye weeks, and favorable matchups. And it’s not just the volume of data, but the ephermerality— if your star RB tweaks a hamstring during Wednesday practice, you better not be basing lineup decisions off of Tuesday’s report.
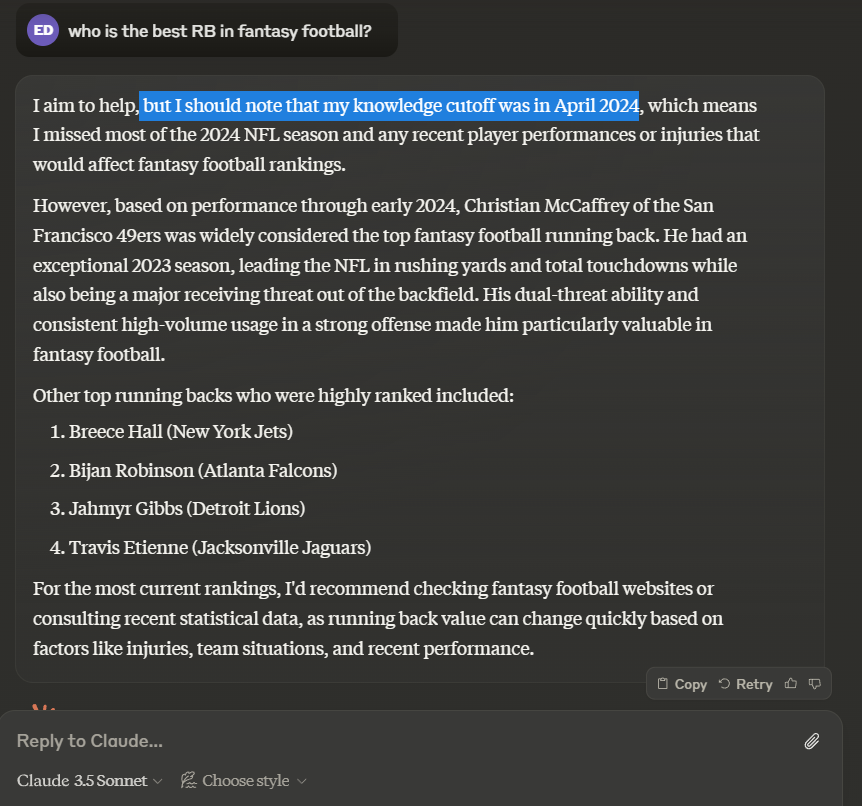
This is why general-purpose chatbots like Anthropic’s Claude and OpenAI’s ChatGPT are essentially useless for fantasy football recommendations, as they are limited to a static training corpus that cuts off months, even years ago.
For instance, if we ask Claude Sonnet 3.5 who the current best running back is, we see names like Christian McCaffrey, Breece Hall, and Travis Etienne, who have had injury-ridden or otherwise disappointing seasons thus far in 2024. There is no mention of Saquon Barkley or Derrick Henry, the obvious frontrunners at this stage. (Though to Claude’s credit, it discloses its limitations.)
Apps like Perplexity are more accurate because they do access a search engine with up-to-date information. However, it of course has no knowledge of my entire roster situation, the state of our league’s playoff picture, or the nuances of our keeper rules.
There is an opportunity to tailor a fantasy football-focused Agent with tools and personalized context for each user.
Let’s dig into the implementation.
Architecture Overview
The heart of the chatbot will be a LangGraph Agent based on the ReAct framework. We’ll give it access to tools that integrate with the Sleeper API for common operations like checking the league standings, rosters, player stats, expert analysis, and more.
In addition to the LangGraph API server, our backend will include a small Postgres database and Redis cache, which are used to manage state and route requests. We’ll use Streamlit for a simple, but effective UI.
For development, we can run all of these components locally via Docker Compose, but I’ll also show the infrastructure-as-code (IaC) to deploy a scalable stack with AWS CDK.
Sleeper API Integration
Sleeper graciously exposes a public, read-only API that we can tap into for user & league details, including a full list of players, rosters, and draft information. Though it’s not documented explicitly, I also found some GraphQL endpoints that provide critical statistics, projections, and — perhaps most valuable of all — recent expert analysis by NFL reporters.
I created a simple API client to access the various methods, which you can find here. The one trick that I wanted to highlight is the requests-cache library. I don’t want to be a greedy client of Sleeper’s freely-available datasets, so I cache responses in a local Sqlite database with a basic TTL mechanism.
Not only does this lessen the amount redundant API traffic bombarding Sleeper’s servers (reducing the chance that they blacklist my IP address), but it significantly reduces latency for my clients, making for a better UX.
Setting up and using the cache is dead simple, as you can see in this snippet —
import requests_cache
from urllib.parse import urljoin
from typing import Union, Optional
from pathlib import Path
class SleeperClient:
def __init__(self, cache_path: str = '../.cache'):
# config
self.cache_path = cache_path
self.session = requests_cache.CachedSession(
Path(cache_path) / 'api_cache',
backend='sqlite',
expire_after=60 * 60 * 24,
)
...
def _get_json(self, path: str, base_url: Optional[str] = None) -> dict:
url = urljoin(base_url or self.base_url, path)
return self.session.get(url).json()
def get_player_stats(self, player_id: Union[str, int], season: Optional[int] = None, group_by_week: bool = False):
return self._get_json(
f'stats/nfl/player/{player_id}?season_type=regular&season={season or self.nfl_state["season"]}{"&grouping=week" if group_by_week else ""}',
base_url=self.stats_url,
)
So running something like
self.session.get(url)
first checks the local Sqlite cache for an unexpired response that particular request. If it’s found, we can skip the API call and just read from the database.
Defining the Tools
I want to turn the Sleeper API client into a handful of key functions that the Agent can use to inform its responses. Because these functions will effectively be invoked by the LLM, I find it important to annotate them clearly and ask for simple, flexible arguments.
For example, Sleeper’s API’s generally ask for numeric player id’s, which makes sense for a programmatic interface. However, I want to abstract that concept away from the LLM and just have it input player names for these functions. To ensure some additional flexibility and allow for things like typos, I implemented a basic “fuzzy search” method to map player name searches to their associated player id.
# file: fantasy_chatbot/league.py
def get_player_id_fuzzy_search(self, player_name: str) -> tuple[str, str]:
# will need a simple search engine to go from player name to player id without needing exact matches. returns the player_id and matched player name as a tuple
nearest_name = process.extract(query=player_name, choices=self.player_names, scorer=fuzz.WRatio, limit=1)[0]
return self.player_name_to_id[nearest_name[0]], self.player_names[nearest_name[2]]
# example usage in a tool
def get_player_news(self, player_name: Annotated[str, "The player's name."]) -> str:
"""
Get recent news about a player for the most up-to-date analysis and injury status.
Use this whenever naming a player in a potential deal, as you should always have the right context for a recommendation.
If sources are provided, include markdown-based link(s)
(e.g. [Rotoballer](https://www.rotoballer.com/player-news/saquon-barkley-has-historic-night-sunday/1502955) )
at the bottom of your response to provide proper attribution
and allow the user to learn more.
"""
player_id, player_name = self.get_player_id_fuzzy_search(player_name)
# news
news = self.client.get_player_news(player_id, limit=3)
player_news = f"Recent News about {player_name}nn"
for n in news:
player_news += f"**{n['metadata']['title']}**n{n['metadata']['description']}"
if analysis := n['metadata'].get('analysis'):
player_news += f"nnAnalysis:n{analysis}"
if url := n['metadata'].get('url'):
# markdown link to source
player_news += f"n[{n['source'].capitalize()}]({url})nn"
return player_news
This is better than a simple map of name to player id because it allows for misspellings and other typos, e.g. saquon → Saquon Barkley
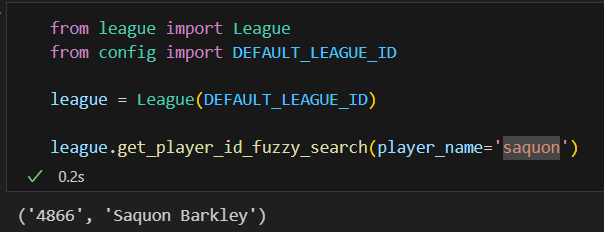
I created a number of useful tools based on these principles:
- Get League Status (standings, current week, no. playoff teams, etc.)
- Get Roster for Team Owner
- Get Player News (up-to-date articles / analysis about the player)
- Get Player Stats (weekly points scored this season with matchups)
- Get Player Current Owner (critical for proposing trades)
- Get Best Available at Position (the waiver wire)
- Get Player Rankings (performance so far, broken down by position)
You can probably think of a few more functions that would be useful to add, like details about recent transactions, league head-to-heads, and draft information.
LangGraph Agent
The impetus for this entire project was an opportunity to learn the LangGraph ecosystem, which may be becoming the de facto standard for constructing agentic workflows.
I’ve hacked together agents from scratch in the past, and I wish I had known about LangGraph at the time. It’s not just a thin wrapper around the various LLM providers, it provides immense utility for building, deploying, & monitoring complex workflows. I’d encourage you to check out the Introduction to LangGraph course by LangChain Academy if you’re interested in diving deeper.
As mentioned before, the graph itself is based on the ReAct framework, which is a popular and effective way to get LLM’s to interact with external tools like those defined above.
I’ve also added a node to persist long-term memories about each user, so that information can be persisted across sessions. I want our agent to “remember” things like users’ concerns, preferences, and previously-recommended trades, as this is not a feature that is implemented particularly well in the chatbots I’ve seen. In graph form, it looks like this:
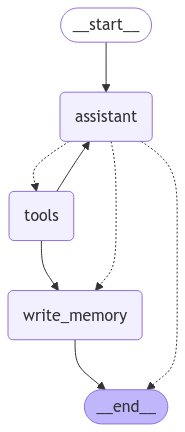
Pretty simple right? Again, you can checkout the full graph definition in the code, but I’ll highlight the write_memory node, which is responsible for writing & updating a profile for each user. This allows us to track key interactions while being efficient about token use.
def write_memory(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Reflect on the chat history and save a memory to the store."""
# get the username from the config
username = config["configurable"]["username"]
# retrieve existing memory if available
namespace = ("memory", username)
existing_memory = store.get(namespace, "user_memory")
# format the memories for the instruction
if existing_memory and existing_memory.value:
memory_dict = existing_memory.value
formatted_memory = (
f"Team Name: {memory_dict.get('team_name', 'Unknown')}n"
f"Current Concerns: {memory_dict.get('current_concerns', 'Unknown')}"
f"Other Details: {memory_dict.get('other_details', 'Unknown')}"
)
else:
formatted_memory = None
system_msg = CREATE_MEMORY_INSTRUCTION.format(memory=formatted_memory)
# invoke the model to produce structured output that matches the schema
new_memory = llm_with_structure.invoke([SystemMessage(content=system_msg)] + state['messages'])
# overwrite the existing user profile
key = "user_memory"
store.put(namespace, key, new_memory)
These memories are surfaced in the system prompt, where I also gave the LLM basic details about our league and how I want it to handle common user requests.
Streamlit UI and Demo
I’m not a frontend developer, so the UI leans heavily on Streamlit’s components and familiar chatbot patterns. Users input their Sleeper username, which is used to lookup their available leagues and persist memories across threads.
I also added a couple of bells and whistles, like implementing token streaming so that users get instant feedback from the LLM. The other important piece is a “research pane”, which surfaces the results of the Agent’s tool calls so that user can inspect the raw data that informs each response.
Here’s a quick demo.
https://medium.com/media/4076e5f39771c68327b58492407ecff0/href
Deployment
For development, I recommend deploying the components locally via the provided docker-compose.yml file. This will expose the API locally at http://localhost:8123 , so you can rapidly test changes and connect to it from a local Streamlit app.
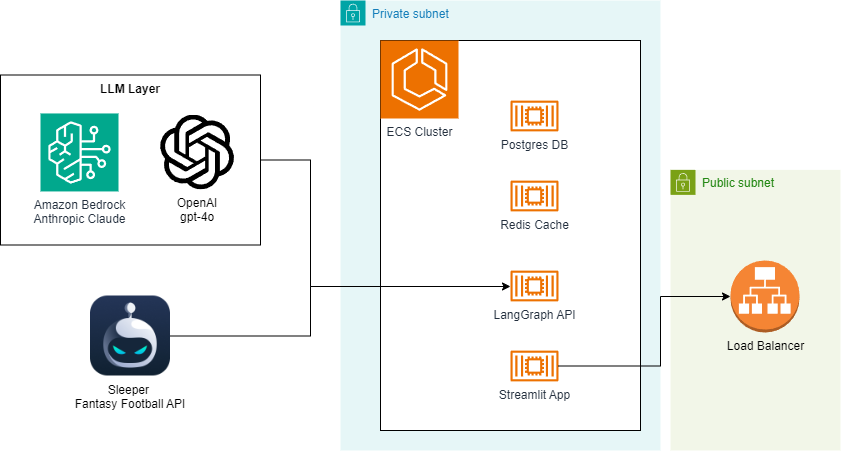
I have also included IaC for an AWS CDK-based deployment that I use to host the app on the internet. Most of the resources are defined here. Notice the parallels between the docker-compose.yml and the CDK code related to the ECS setup:
Snippet from docker-compose.yml for the LangGraph API container:
# from docker-compose.yml
langgraph-api:
image: "fantasy-chatbot"
ports:
- "8123:8000"
healthcheck:
test: curl --request GET --url http://localhost:8000/ok
timeout: 1s
retries: 5
interval: 5s
depends_on:
langgraph-redis:
condition: service_healthy
langgraph-postgres:
condition: service_healthy
env_file: "../.env"
environment:
REDIS_URI: redis://langgraph-redis:6379
POSTGRES_URI: postgres://postgres:postgres@langgraph-postgres:5432/postgres?sslmode=disable// file: fantasy-football-agent-stack.ts
And here is the analogous setup in the CDK stack:
// fantasy-football-agent-stack.ts
const apiImageAsset = new DockerImageAsset(this, 'apiImageAsset', {
directory: path.join(__dirname, '../../fantasy_chatbot'),
file: 'api.Dockerfile',
platform: assets.Platform.LINUX_AMD64,
});
const apiContainer = taskDefinition.addContainer('langgraph-api', {
containerName: 'langgraph-api',
image: ecs.ContainerImage.fromDockerImageAsset(apiImageAsset),
portMappings: [{
containerPort: 8000,
}],
environment: {
...dotenvMap,
REDIS_URI: 'redis://127.0.0.1:6379',
POSTGRES_URI: 'postgres://postgres:[email protected]:5432/postgres?sslmode=disable'
},
logging: ecs.LogDrivers.awsLogs({
streamPrefix: 'langgraph-api',
}),
});
apiContainer.addContainerDependencies(
{
container: redisContainer,
condition: ecs.ContainerDependencyCondition.HEALTHY,
},
{
container: postgresContainer,
condition: ecs.ContainerDependencyCondition.HEALTHY,
},
)
Aside from some subtle differences, it’s effectively a 1:1 translation, which is always something I look for when comparing local environments to “prod” deployments. The DockerImageAsset is a particularly useful resource, as it handles building and deploying (to ECR) the Docker image during synthesis.
Note: Deploying the stack to your AWS account via npm run cdk deploy WILL incur charges. In this demo code I have not included any password protection on the Streamlit app, meaning anyone who has the URL can use the chatbot! I highly recommend adding some additional security if you plan to deploy it yourself.
Takeaways
You want to keep your tools simple. This app does a lot, but is still missing some key functionality, and it will start to break down if I simply add more tools. In the future, I want to break up the graph into task-specific sub-components, e.g. a “News Analyst” Agent and a “Statistician” Agent.
Traceability and debugging are more important with Agent-based apps than traditional software. Despite significant advancements in models’ ability to produce structured outputs, LLM-based function calling is still inherently less reliable than conventional programs. I used LangSmith extensively for debugging.
In an age of commoditized language models, there is no replacement for reliable reporters. We’re at a point where you can put together a reasonable chatbot in a weekend, so how do products differentiate themselves and build moats? This app (or any other like it) would be useless without access to high-quality reporting from analysts and experts. In other words, the Ian Rapaport’s and Matthew Berry’s of the world are more valuable than ever.
Repo
GitHub – evandiewald/fantasy-football-agent
All images, unless otherwise noted, are by the author.
Building a Fantasy Football Research Agent with LangGraph was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
An end-to-end guide covering integration with the Sleeper API, creation of a Streamlit UI, and deployment via AWS CDKPhoto by Dmitriy Demidov on UnsplashIt’s embarrassing how much time I spend thinking about my fantasy football team.Managing a squad means processing a firehose of information — injury reports, expert projections, upcoming bye weeks, and favorable matchups. And it’s not just the volume of data, but the ephermerality— if your star RB tweaks a hamstring during Wednesday practice, you better not be basing lineup decisions off of Tuesday’s report.This is why general-purpose chatbots like Anthropic’s Claude and OpenAI’s ChatGPT are essentially useless for fantasy football recommendations, as they are limited to a static training corpus that cuts off months, even years ago.For instance, if we ask Claude Sonnet 3.5 who the current best running back is, we see names like Christian McCaffrey, Breece Hall, and Travis Etienne, who have had injury-ridden or otherwise disappointing seasons thus far in 2024. There is no mention of Saquon Barkley or Derrick Henry, the obvious frontrunners at this stage. (Though to Claude’s credit, it discloses its limitations.)Apps like Perplexity are more accurate because they do access a search engine with up-to-date information. However, it of course has no knowledge of my entire roster situation, the state of our league’s playoff picture, or the nuances of our keeper rules.There is an opportunity to tailor a fantasy football-focused Agent with tools and personalized context for each user.Let’s dig into the implementation.Architecture OverviewThe heart of the chatbot will be a LangGraph Agent based on the ReAct framework. We’ll give it access to tools that integrate with the Sleeper API for common operations like checking the league standings, rosters, player stats, expert analysis, and more.In addition to the LangGraph API server, our backend will include a small Postgres database and Redis cache, which are used to manage state and route requests. We’ll use Streamlit for a simple, but effective UI.For development, we can run all of these components locally via Docker Compose, but I’ll also show the infrastructure-as-code (IaC) to deploy a scalable stack with AWS CDK.Sleeper API IntegrationSleeper graciously exposes a public, read-only API that we can tap into for user & league details, including a full list of players, rosters, and draft information. Though it’s not documented explicitly, I also found some GraphQL endpoints that provide critical statistics, projections, and — perhaps most valuable of all — recent expert analysis by NFL reporters.I created a simple API client to access the various methods, which you can find here. The one trick that I wanted to highlight is the requests-cache library. I don’t want to be a greedy client of Sleeper’s freely-available datasets, so I cache responses in a local Sqlite database with a basic TTL mechanism.Not only does this lessen the amount redundant API traffic bombarding Sleeper’s servers (reducing the chance that they blacklist my IP address), but it significantly reduces latency for my clients, making for a better UX.Setting up and using the cache is dead simple, as you can see in this snippet —import requests_cachefrom urllib.parse import urljoinfrom typing import Union, Optionalfrom pathlib import Pathclass SleeperClient: def __init__(self, cache_path: str = ‘../.cache’): # config self.cache_path = cache_path self.session = requests_cache.CachedSession( Path(cache_path) / ‘api_cache’, backend=’sqlite’, expire_after=60 * 60 * 24, ) … def _get_json(self, path: str, base_url: Optional[str] = None) -> dict: url = urljoin(base_url or self.base_url, path) return self.session.get(url).json() def get_player_stats(self, player_id: Union[str, int], season: Optional[int] = None, group_by_week: bool = False): return self._get_json( f’stats/nfl/player/{player_id}?season_type=regular&season={season or self.nfl_state[“season”]}{“&grouping=week” if group_by_week else “”}’, base_url=self.stats_url, )So running something likeself.session.get(url)first checks the local Sqlite cache for an unexpired response that particular request. If it’s found, we can skip the API call and just read from the database.Defining the ToolsI want to turn the Sleeper API client into a handful of key functions that the Agent can use to inform its responses. Because these functions will effectively be invoked by the LLM, I find it important to annotate them clearly and ask for simple, flexible arguments.For example, Sleeper’s API’s generally ask for numeric player id’s, which makes sense for a programmatic interface. However, I want to abstract that concept away from the LLM and just have it input player names for these functions. To ensure some additional flexibility and allow for things like typos, I implemented a basic “fuzzy search” method to map player name searches to their associated player id.# file: fantasy_chatbot/league.pydef get_player_id_fuzzy_search(self, player_name: str) -> tuple[str, str]: # will need a simple search engine to go from player name to player id without needing exact matches. returns the player_id and matched player name as a tuple nearest_name = process.extract(query=player_name, choices=self.player_names, scorer=fuzz.WRatio, limit=1)[0] return self.player_name_to_id[nearest_name[0]], self.player_names[nearest_name[2]]# example usage in a tooldef get_player_news(self, player_name: Annotated[str, “The player’s name.”]) -> str: “”” Get recent news about a player for the most up-to-date analysis and injury status. Use this whenever naming a player in a potential deal, as you should always have the right context for a recommendation. If sources are provided, include markdown-based link(s) (e.g. [Rotoballer](https://www.rotoballer.com/player-news/saquon-barkley-has-historic-night-sunday/1502955) ) at the bottom of your response to provide proper attribution and allow the user to learn more. “”” player_id, player_name = self.get_player_id_fuzzy_search(player_name) # news news = self.client.get_player_news(player_id, limit=3) player_news = f”Recent News about {player_name}nn” for n in news: player_news += f”**{n[‘metadata’][‘title’]}**n{n[‘metadata’][‘description’]}” if analysis := n[‘metadata’].get(‘analysis’): player_news += f”nnAnalysis:n{analysis}” if url := n[‘metadata’].get(‘url’): # markdown link to source player_news += f”n[{n[‘source’].capitalize()}]({url})nn” return player_newsThis is better than a simple map of name to player id because it allows for misspellings and other typos, e.g. saquon → Saquon BarkleyI created a number of useful tools based on these principles:Get League Status (standings, current week, no. playoff teams, etc.)Get Roster for Team OwnerGet Player News (up-to-date articles / analysis about the player)Get Player Stats (weekly points scored this season with matchups)Get Player Current Owner (critical for proposing trades)Get Best Available at Position (the waiver wire)Get Player Rankings (performance so far, broken down by position)You can probably think of a few more functions that would be useful to add, like details about recent transactions, league head-to-heads, and draft information.LangGraph AgentThe impetus for this entire project was an opportunity to learn the LangGraph ecosystem, which may be becoming the de facto standard for constructing agentic workflows.I’ve hacked together agents from scratch in the past, and I wish I had known about LangGraph at the time. It’s not just a thin wrapper around the various LLM providers, it provides immense utility for building, deploying, & monitoring complex workflows. I’d encourage you to check out the Introduction to LangGraph course by LangChain Academy if you’re interested in diving deeper.As mentioned before, the graph itself is based on the ReAct framework, which is a popular and effective way to get LLM’s to interact with external tools like those defined above.I’ve also added a node to persist long-term memories about each user, so that information can be persisted across sessions. I want our agent to “remember” things like users’ concerns, preferences, and previously-recommended trades, as this is not a feature that is implemented particularly well in the chatbots I’ve seen. In graph form, it looks like this:Pretty simple right? Again, you can checkout the full graph definition in the code, but I’ll highlight the write_memory node, which is responsible for writing & updating a profile for each user. This allows us to track key interactions while being efficient about token use.def write_memory(state: MessagesState, config: RunnableConfig, store: BaseStore): “””Reflect on the chat history and save a memory to the store.””” # get the username from the config username = config[“configurable”][“username”] # retrieve existing memory if available namespace = (“memory”, username) existing_memory = store.get(namespace, “user_memory”) # format the memories for the instruction if existing_memory and existing_memory.value: memory_dict = existing_memory.value formatted_memory = ( f”Team Name: {memory_dict.get(‘team_name’, ‘Unknown’)}n” f”Current Concerns: {memory_dict.get(‘current_concerns’, ‘Unknown’)}” f”Other Details: {memory_dict.get(‘other_details’, ‘Unknown’)}” ) else: formatted_memory = None system_msg = CREATE_MEMORY_INSTRUCTION.format(memory=formatted_memory) # invoke the model to produce structured output that matches the schema new_memory = llm_with_structure.invoke([SystemMessage(content=system_msg)] + state[‘messages’]) # overwrite the existing user profile key = “user_memory” store.put(namespace, key, new_memory)These memories are surfaced in the system prompt, where I also gave the LLM basic details about our league and how I want it to handle common user requests.Streamlit UI and DemoI’m not a frontend developer, so the UI leans heavily on Streamlit’s components and familiar chatbot patterns. Users input their Sleeper username, which is used to lookup their available leagues and persist memories across threads.I also added a couple of bells and whistles, like implementing token streaming so that users get instant feedback from the LLM. The other important piece is a “research pane”, which surfaces the results of the Agent’s tool calls so that user can inspect the raw data that informs each response.Here’s a quick demo.https://medium.com/media/4076e5f39771c68327b58492407ecff0/hrefDeploymentFor development, I recommend deploying the components locally via the provided docker-compose.yml file. This will expose the API locally at http://localhost:8123 , so you can rapidly test changes and connect to it from a local Streamlit app.I have also included IaC for an AWS CDK-based deployment that I use to host the app on the internet. Most of the resources are defined here. Notice the parallels between the docker-compose.yml and the CDK code related to the ECS setup:Snippet from docker-compose.yml for the LangGraph API container:# from docker-compose.ymllanggraph-api: image: “fantasy-chatbot” ports: – “8123:8000” healthcheck: test: curl –request GET –url http://localhost:8000/ok timeout: 1s retries: 5 interval: 5s depends_on: langgraph-redis: condition: service_healthy langgraph-postgres: condition: service_healthy env_file: “../.env” environment: REDIS_URI: redis://langgraph-redis:6379 POSTGRES_URI: postgres://postgres:postgres@langgraph-postgres:5432/postgres?sslmode=disable// file: fantasy-football-agent-stack.tsAnd here is the analogous setup in the CDK stack:// fantasy-football-agent-stack.tsconst apiImageAsset = new DockerImageAsset(this, ‘apiImageAsset’, { directory: path.join(__dirname, ‘../../fantasy_chatbot’), file: ‘api.Dockerfile’, platform: assets.Platform.LINUX_AMD64,});const apiContainer = taskDefinition.addContainer(‘langgraph-api’, { containerName: ‘langgraph-api’, image: ecs.ContainerImage.fromDockerImageAsset(apiImageAsset), portMappings: [{ containerPort: 8000, }], environment: { …dotenvMap, REDIS_URI: ‘redis://127.0.0.1:6379’, POSTGRES_URI: ‘postgres://postgres:[email protected]:5432/postgres?sslmode=disable’ }, logging: ecs.LogDrivers.awsLogs({ streamPrefix: ‘langgraph-api’, }),});apiContainer.addContainerDependencies( { container: redisContainer, condition: ecs.ContainerDependencyCondition.HEALTHY, }, { container: postgresContainer, condition: ecs.ContainerDependencyCondition.HEALTHY, },)Aside from some subtle differences, it’s effectively a 1:1 translation, which is always something I look for when comparing local environments to “prod” deployments. The DockerImageAsset is a particularly useful resource, as it handles building and deploying (to ECR) the Docker image during synthesis.Note: Deploying the stack to your AWS account via npm run cdk deploy WILL incur charges. In this demo code I have not included any password protection on the Streamlit app, meaning anyone who has the URL can use the chatbot! I highly recommend adding some additional security if you plan to deploy it yourself.TakeawaysYou want to keep your tools simple. This app does a lot, but is still missing some key functionality, and it will start to break down if I simply add more tools. In the future, I want to break up the graph into task-specific sub-components, e.g. a “News Analyst” Agent and a “Statistician” Agent.Traceability and debugging are more important with Agent-based apps than traditional software. Despite significant advancements in models’ ability to produce structured outputs, LLM-based function calling is still inherently less reliable than conventional programs. I used LangSmith extensively for debugging.In an age of commoditized language models, there is no replacement for reliable reporters. We’re at a point where you can put together a reasonable chatbot in a weekend, so how do products differentiate themselves and build moats? This app (or any other like it) would be useless without access to high-quality reporting from analysts and experts. In other words, the Ian Rapaport’s and Matthew Berry’s of the world are more valuable than ever.RepoGitHub – evandiewald/fantasy-football-agentAll images, unless otherwise noted, are by the author.Building a Fantasy Football Research Agent with LangGraph was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. hands-on-tutorials, fantasy-football, langchain, agents, streamlit Towards Data Science – MediumRead More

 Add to favorites
Add to favorites
0 Comments