Multimodal Models — LLMs That Can See and Hear
An introduction with example Python code
This is the first post in a larger series on Multimodal AI. A Multimodal Model (MM) is an AI system capable of processing or generating multiple data modalities (e.g., text, image, audio, video). In this article, I will discuss a particular type of MM that builds on top of a large language model (LLM). I’ll start with a high-level overview of such models and then share example code for using LLaMA 3.2 Vision to perform various image-to-text tasks.

Large language models (LLMs) have marked a fundamental shift in AI research and development. However, despite their broader impacts, they are still fundamentally limited.
Namely, LLMs can only process and generate text, making them blind to other modalities such as images, video, audio, and more. This is a major limitation since some tasks rely on non-text data, e.g., analyzing engineering blueprints, reading body language or speech tonality, and interpreting plots and infographics.
This has sparked efforts toward expanding LLM functionality to include multiple modalities.
What is a Multimodal Model?
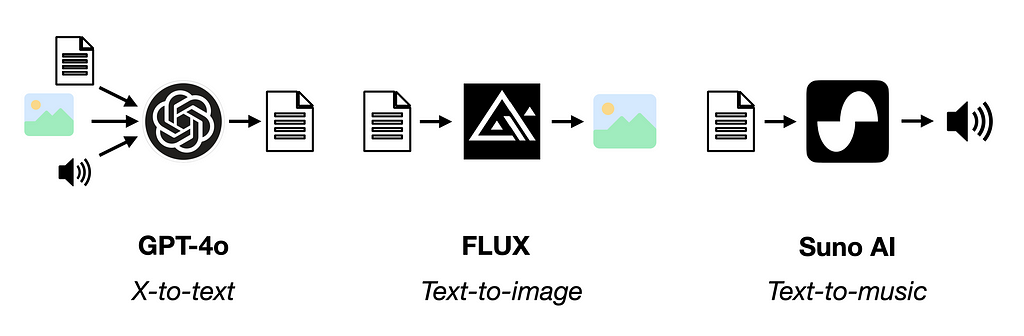
A Multimodal Model (MM) is an AI system that can process multiple data modalities as input or output (or both) [1]. Below are a few examples.
- GPT-4o — Input: text, images, and audio. Output: text.
- FLUX — Input: text. Output: images.
- Suno — Input: text. Output: audio.
While there are several ways to create models that can process multiple data modalities, a recent line of research seeks to use LLMs as the core reasoning engine of a multimodal system [2]. Such models are called multimodal large language models (or large multimodal models) [2][3].
One benefit of using existing LLM as a starting point for MMs is that they’ve demonstrated a strong ability to acquire world knowledge through large-scale pre-training, which can be leveraged to process concepts appearing in non-textual representations.
3 Paths to Multimodality
Here, I will focus on multimodal models developed from an LLM. Three popular approaches are described below.
- LLM + Tools: Augment LLMs with pre-built components
- LLM + Adapters: Augment LLMs with multi-modal encoders or decoders, which are aligned via adapter fine-tuning
- Unified Models: Expand LLM architecture to fuse modalities at pre-training
Path 1: LLM + Tools
The simplest way to make an LLM multimodal is by adding external modules that can readily translate between text and an arbitrary modality. For example, a transcription model (e.g. Whisper) can be connected to an LLM to translate input speech into text, or a text-to-image model can generate images based on LLM outputs.
The key benefit of such an approach is simplicity. Tools can quickly be assembled without any additional model training.
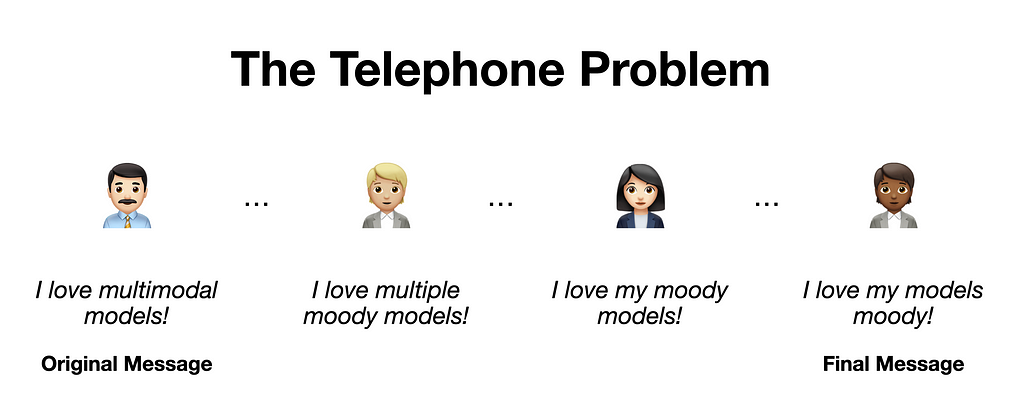
The downside, however, is that the quality of such a system may be limited. Just like when playing a game of telephone, messages mutate when passed from person to person. Information may degrade going from one module to another via text descriptions only.
Path 2: LLM + Adapters
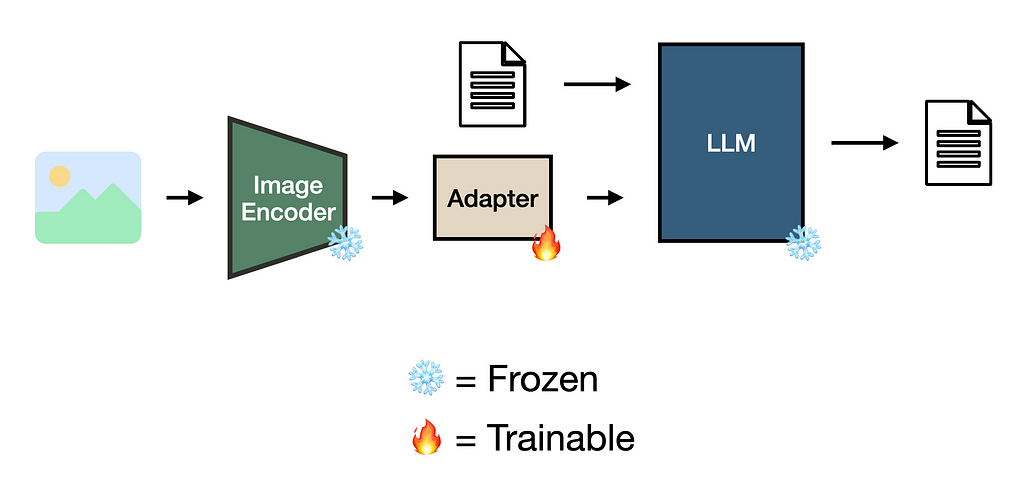
One way to mitigate the “telephone problem” is by optimizing the representations of new modalities to align with the LLM’s internal concept space. For example, ensuring an image of a dog and the description of one look similar to the LLM.
This is possible through the use of adapters, a relatively small set of parameters that appropriately translate a dense vector representation for a downstream model [2][4][5].
Adapters can be trained using, for example, image-caption pairs, where the adapter learns to translate an image encoding into a representation compatible with the LLM [2][4][6]. One way to achieve this is via contrastive learning [2], which I will discuss more in the next article of this series.
The benefits of using adapters to augment LLMs include better alignment between novel modality representations in a data-efficient way. Since many pre-trained embedding, language, and diffusion models are available in today’s AI landscape, one can readily fuse models based on their needs. Notable examples from the open-source community are LLaVA, LLaMA 3.2 Vision, Flamingo, MiniGPT4, Janus, Mini-Omni2, and IDEFICS [3][5][7][8].
However, this data efficiency comes at a price. Just like how adapter-based fine-tuning approaches (e.g. LoRA) can only nudge an LLM so far, the same holds in this context. Additionally, pasting various encoders and decoders to an LLM may result in overly complicated model architectures.
Path 3: Unified Models
The final way to make an LLM multimodal is by incorporating multiple modalities at the pre-training stage. This works by adding modality-specific tokenizers (rather than pre-trained encoder/decoder models) to the model architecture and expanding the embedding layer to accommodate new modalities [9].
While this approach comes with significantly greater technical challenges and computational requirements, it enables the seamless integration of multiple modalities into a shared concept space, unlocking better reasoning capabilities and efficiencies [10].
The preeminent example of this unified approach is (presumably) GPT-4o, which processes text, image, and audio inputs to enable expanded reasoning capabilities at faster inference times than previous versions of GPT-4. Other models that follow this approach include Gemini, Emu3, BLIP, and Chameleon [9][10].
Training these models typically entails multi-step pre-training on a set of (multimodal) tasks, such as language modeling, text-image contrastive learning, text-to-video generation, and others [7][9][10].
Example: Using LLaMA 3.2 Vision for Image-based Tasks
With a basic understanding of how LLM-based multimodal models work under the hood, let’s see what we can do with them. Here, I will use LLaMA 3.2 Vision to perform various image-to-text tasks.
To run this example, download Ollama and its Python library. This enables the model to run locally i.e. no need for external API calls.
The example code is freely available on GitHub.
Importing model
We start by importing ollama.
import ollama
Next, we’ll download the model locally. Here, we use LLaMA 3.2 Vision 11B.
ollama.pull('llama3.2-vision')
Visual QA
Now, we’re ready to use the model! Here’s how we can do basic visual question answering.
# pass image and question to model
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': 'What is in this image?',
'images': ['images/shaw-sitting.jpeg']
}]
)
# print response
print(response['message']['content'])
The image is of me from a networking event (as shown below).

The model’s response is shown below. While it has trouble reading what’s on my hat, it does a decent job inferring the context of the photo.
This image shows a man sitting on a yellow ottoman with his hands clasped
together. He is wearing a black polo shirt with a name tag that says "Shaw"
and a black baseball cap with white text that reads, "THE DATA ENREPRENEUR."
The background of the image appears to be an office or lounge area, with a
large screen on the wall behind him displaying a presentation slide. There are
also several chairs and tables in the background, suggesting that this may be
a meeting room or common area for employees to gather and work.
If you run this on your machine, you may run into a long wait time until the model generates a response. One thing we can do to make this less painful is to enable streaming.
# create stream
stream = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': 'Can you write a caption for this image?',
'images': ['images/shaw-sitting.jpeg']
}],
stream=True,
)
# print chunks in stream as they become available
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
Interestingly, we get a qualitatively different response when prompting the model in a slightly different way for the same image.
This image features a man sitting on a yellow chair. He is wearing a black
polo shirt with a blue name tag that says "Shaw", khaki pants, and a black
baseball cap with white text that reads "THE DATA ENTHUSIAST". The man has his
hands clasped together in front of him and appears to be smiling.
The background of the image consists of a room with various pieces of
furniture. There is a green ottoman to the left of the yellow chair, and two
blue chairs on the right side of the image. A brown table or desk sits behind
the man, along with a fireplace. The walls are painted teal blue and have a
wooden accent wall featuring holes for hanging items.
The overall atmosphere suggests that this may be a modern office space or
co-working area where people can come to work, relax, or socialize.
Explaining Memes
Objectively describing a scene is simpler than understanding and explaining humor. Let’s see how the model explains the meme below.

# ask model to explain meme
stream = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': 'Can you explain this meme to me?',
'images': ['images/ai-meme.jpeg']
}],
stream=True,
)
# print stream
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
The meme depicts Patrick Star from SpongeBob SquarePants, surrounded by
various AI tools and symbols. The caption reads "Trying to build with AI
today..." The image humorously illustrates the challenges of using AI in
building projects, implying that it can be overwhelming and frustrating.
The model does a good job here. It understands that the image is funny while also conveying the pain that people face.
OCR
The last use case is optical character recognition (OCR). This involves extracting text from images, which is valuable in a wide range of contexts. Here, I’ll see if the model can translate a screenshot from my notes app to a markdown file.

# ask model to read screenshot and convert to markdown
stream = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': 'Can you transcribe the text from this screenshot in a
markdown format?',
'images': ['images/5-ai-projects.jpeg']
}],
stream=True,
)
# read stream
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
Here is the transcription of the text in markdown format:
5 AI Projects You Can Build This Weekend (with Python)
1. **Resume Optimization (Beginner)**
* Idea: build a tool that adapts your resume for a specific job description
2. **YouTube Lecture Summarizer (Beginner)**
* Idea: build a tool that takes YouTube video links and summarizes them
3. **Automatically Organizing PDFs (Intermediate)**
* Idea: build a tool to analyze the contents of each PDF and organize them
into folders based on topics
4. **Multimodal Search (Intermediate)**
* Idea: use multimodal embeddings to represent user queries, text knowledge,
and images in a single space
5. **Desktop QA (Advanced)**
* Idea: connect a multimodal knowledge base to a multimodal model like
Llama-3.2-11B-Vision
Note that I've added some minor formatting changes to make the text more
readable in markdown format. Let me know if you have any further requests.
Again, the model does a decent job out of the box. While it missed the header, it accurately captured the content and formatting of the project ideas.
YouTube-Blog/multimodal-ai/1-mm-llms at main · ShawhinT/YouTube-Blog
What’s next?
Multimodal models are AI systems that can process multiple data modalities as inputs or outputs (or both). A recent trend for developing these systems consists of adding modalities to large language models (LLMs) in various ways.
However, there are other types of multimodal models. In the next article of this series, I will discuss multimodal embedding models, which encode multiple data modalities (e.g. text and images) into a shared representation space.
My website: https://www.shawhintalebi.com/
Get FREE access to every new story I write
[1] Multimodal Machine Learning: A Survey and Taxonomy
[2] A Survey on Multimodal Large Language Models
[5] Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
[6] Learning Transferable Visual Models From Natural Language Supervision
[7] Flamingo: a Visual Language Model for Few-Shot Learning
[8] Mini-Omni2: Towards Open-source GPT-4o with Vision, Speech and Duplex Capabilities
[9] Emu3: Next-Token Prediction is All You Need
[10] Chameleon: Mixed-Modal Early-Fusion Foundation Models
Multimodal Models — LLMs that can see and hear was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Multimodal Models — LLMs That Can See and HearAn introduction with example Python codeThis is the first post in a larger series on Multimodal AI. A Multimodal Model (MM) is an AI system capable of processing or generating multiple data modalities (e.g., text, image, audio, video). In this article, I will discuss a particular type of MM that builds on top of a large language model (LLM). I’ll start with a high-level overview of such models and then share example code for using LLaMA 3.2 Vision to perform various image-to-text tasks.Photo by Sincerely Media on UnsplashLarge language models (LLMs) have marked a fundamental shift in AI research and development. However, despite their broader impacts, they are still fundamentally limited.Namely, LLMs can only process and generate text, making them blind to other modalities such as images, video, audio, and more. This is a major limitation since some tasks rely on non-text data, e.g., analyzing engineering blueprints, reading body language or speech tonality, and interpreting plots and infographics.This has sparked efforts toward expanding LLM functionality to include multiple modalities.What is a Multimodal Model?A Multimodal Model (MM) is an AI system that can process multiple data modalities as input or output (or both) [1]. Below are a few examples.GPT-4o — Input: text, images, and audio. Output: text.FLUX — Input: text. Output: images.Suno — Input: text. Output: audio.Example mutlimodal models. Image by author.While there are several ways to create models that can process multiple data modalities, a recent line of research seeks to use LLMs as the core reasoning engine of a multimodal system [2]. Such models are called multimodal large language models (or large multimodal models) [2][3].One benefit of using existing LLM as a starting point for MMs is that they’ve demonstrated a strong ability to acquire world knowledge through large-scale pre-training, which can be leveraged to process concepts appearing in non-textual representations.3 Paths to MultimodalityHere, I will focus on multimodal models developed from an LLM. Three popular approaches are described below.LLM + Tools: Augment LLMs with pre-built componentsLLM + Adapters: Augment LLMs with multi-modal encoders or decoders, which are aligned via adapter fine-tuningUnified Models: Expand LLM architecture to fuse modalities at pre-trainingPath 1: LLM + ToolsThe simplest way to make an LLM multimodal is by adding external modules that can readily translate between text and an arbitrary modality. For example, a transcription model (e.g. Whisper) can be connected to an LLM to translate input speech into text, or a text-to-image model can generate images based on LLM outputs.The key benefit of such an approach is simplicity. Tools can quickly be assembled without any additional model training.The downside, however, is that the quality of such a system may be limited. Just like when playing a game of telephone, messages mutate when passed from person to person. Information may degrade going from one module to another via text descriptions only.An example of information degradation during message passing. Image by author.Path 2: LLM + AdaptersOne way to mitigate the “telephone problem” is by optimizing the representations of new modalities to align with the LLM’s internal concept space. For example, ensuring an image of a dog and the description of one look similar to the LLM.This is possible through the use of adapters, a relatively small set of parameters that appropriately translate a dense vector representation for a downstream model [2][4][5].Adapters can be trained using, for example, image-caption pairs, where the adapter learns to translate an image encoding into a representation compatible with the LLM [2][4][6]. One way to achieve this is via contrastive learning [2], which I will discuss more in the next article of this series.A simple strategy for integrating images into an LLM via an image encoding adapter. Image by author.The benefits of using adapters to augment LLMs include better alignment between novel modality representations in a data-efficient way. Since many pre-trained embedding, language, and diffusion models are available in today’s AI landscape, one can readily fuse models based on their needs. Notable examples from the open-source community are LLaVA, LLaMA 3.2 Vision, Flamingo, MiniGPT4, Janus, Mini-Omni2, and IDEFICS [3][5][7][8].However, this data efficiency comes at a price. Just like how adapter-based fine-tuning approaches (e.g. LoRA) can only nudge an LLM so far, the same holds in this context. Additionally, pasting various encoders and decoders to an LLM may result in overly complicated model architectures.Path 3: Unified ModelsThe final way to make an LLM multimodal is by incorporating multiple modalities at the pre-training stage. This works by adding modality-specific tokenizers (rather than pre-trained encoder/decoder models) to the model architecture and expanding the embedding layer to accommodate new modalities [9].While this approach comes with significantly greater technical challenges and computational requirements, it enables the seamless integration of multiple modalities into a shared concept space, unlocking better reasoning capabilities and efficiencies [10].The preeminent example of this unified approach is (presumably) GPT-4o, which processes text, image, and audio inputs to enable expanded reasoning capabilities at faster inference times than previous versions of GPT-4. Other models that follow this approach include Gemini, Emu3, BLIP, and Chameleon [9][10].Training these models typically entails multi-step pre-training on a set of (multimodal) tasks, such as language modeling, text-image contrastive learning, text-to-video generation, and others [7][9][10].Example: Using LLaMA 3.2 Vision for Image-based TasksWith a basic understanding of how LLM-based multimodal models work under the hood, let’s see what we can do with them. Here, I will use LLaMA 3.2 Vision to perform various image-to-text tasks.To run this example, download Ollama and its Python library. This enables the model to run locally i.e. no need for external API calls.The example code is freely available on GitHub.Importing modelWe start by importing ollama.import ollamaNext, we’ll download the model locally. Here, we use LLaMA 3.2 Vision 11B.ollama.pull(‘llama3.2-vision’)Visual QANow, we’re ready to use the model! Here’s how we can do basic visual question answering.# pass image and question to modelresponse = ollama.chat( model=’llama3.2-vision’, messages=[{ ‘role’: ‘user’, ‘content’: ‘What is in this image?’, ‘images’: [‘images/shaw-sitting.jpeg’] }])# print responseprint(response[‘message’][‘content’])The image is of me from a networking event (as shown below).Image of me from networking event at Richardson IQ. Image by author.The model’s response is shown below. While it has trouble reading what’s on my hat, it does a decent job inferring the context of the photo.This image shows a man sitting on a yellow ottoman with his hands clasped together. He is wearing a black polo shirt with a name tag that says “Shaw” and a black baseball cap with white text that reads, “THE DATA ENREPRENEUR.” The background of the image appears to be an office or lounge area, with a large screen on the wall behind him displaying a presentation slide. There are also several chairs and tables in the background, suggesting that this may be a meeting room or common area for employees to gather and work.If you run this on your machine, you may run into a long wait time until the model generates a response. One thing we can do to make this less painful is to enable streaming.# create streamstream = ollama.chat( model=’llama3.2-vision’, messages=[{ ‘role’: ‘user’, ‘content’: ‘Can you write a caption for this image?’, ‘images’: [‘images/shaw-sitting.jpeg’] }], stream=True,)# print chunks in stream as they become availablefor chunk in stream: print(chunk[‘message’][‘content’], end=”, flush=True)Interestingly, we get a qualitatively different response when prompting the model in a slightly different way for the same image.This image features a man sitting on a yellow chair. He is wearing a black polo shirt with a blue name tag that says “Shaw”, khaki pants, and a black baseball cap with white text that reads “THE DATA ENTHUSIAST”. The man has his hands clasped together in front of him and appears to be smiling.The background of the image consists of a room with various pieces of furniture. There is a green ottoman to the left of the yellow chair, and two blue chairs on the right side of the image. A brown table or desk sits behind the man, along with a fireplace. The walls are painted teal blue and have a wooden accent wall featuring holes for hanging items.The overall atmosphere suggests that this may be a modern office space or co-working area where people can come to work, relax, or socialize.Explaining MemesObjectively describing a scene is simpler than understanding and explaining humor. Let’s see how the model explains the meme below.Building with AI meme. Image by author.# ask model to explain memestream = ollama.chat( model=’llama3.2-vision’, messages=[{ ‘role’: ‘user’, ‘content’: ‘Can you explain this meme to me?’, ‘images’: [‘images/ai-meme.jpeg’] }], stream=True,)# print streamfor chunk in stream: print(chunk[‘message’][‘content’], end=”, flush=True)The meme depicts Patrick Star from SpongeBob SquarePants, surrounded by various AI tools and symbols. The caption reads “Trying to build with AI today…” The image humorously illustrates the challenges of using AI in building projects, implying that it can be overwhelming and frustrating.The model does a good job here. It understands that the image is funny while also conveying the pain that people face.OCRThe last use case is optical character recognition (OCR). This involves extracting text from images, which is valuable in a wide range of contexts. Here, I’ll see if the model can translate a screenshot from my notes app to a markdown file.Screenshot of 5 AI project ideas. Image by author.# ask model to read screenshot and convert to markdownstream = ollama.chat( model=’llama3.2-vision’, messages=[{ ‘role’: ‘user’, ‘content’: ‘Can you transcribe the text from this screenshot in a markdown format?’, ‘images’: [‘images/5-ai-projects.jpeg’] }], stream=True,)# read streamfor chunk in stream: print(chunk[‘message’][‘content’], end=”, flush=True)Here is the transcription of the text in markdown format:5 AI Projects You Can Build This Weekend (with Python)1. **Resume Optimization (Beginner)** * Idea: build a tool that adapts your resume for a specific job description2. **YouTube Lecture Summarizer (Beginner)** * Idea: build a tool that takes YouTube video links and summarizes them3. **Automatically Organizing PDFs (Intermediate)** * Idea: build a tool to analyze the contents of each PDF and organize them into folders based on topics4. **Multimodal Search (Intermediate)** * Idea: use multimodal embeddings to represent user queries, text knowledge, and images in a single space5. **Desktop QA (Advanced)** * Idea: connect a multimodal knowledge base to a multimodal model like Llama-3.2-11B-VisionNote that I’ve added some minor formatting changes to make the text more readable in markdown format. Let me know if you have any further requests.Again, the model does a decent job out of the box. While it missed the header, it accurately captured the content and formatting of the project ideas.YouTube-Blog/multimodal-ai/1-mm-llms at main · ShawhinT/YouTube-BlogWhat’s next?Multimodal models are AI systems that can process multiple data modalities as inputs or outputs (or both). A recent trend for developing these systems consists of adding modalities to large language models (LLMs) in various ways.However, there are other types of multimodal models. In the next article of this series, I will discuss multimodal embedding models, which encode multiple data modalities (e.g. text and images) into a shared representation space.My website: https://www.shawhintalebi.com/Get FREE access to every new story I write[1] Multimodal Machine Learning: A Survey and Taxonomy[2] A Survey on Multimodal Large Language Models[3] Visual Instruction Tuning[4] GPT-4o System Card[5] Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation[6] Learning Transferable Visual Models From Natural Language Supervision[7] Flamingo: a Visual Language Model for Few-Shot Learning[8] Mini-Omni2: Towards Open-source GPT-4o with Vision, Speech and Duplex Capabilities[9] Emu3: Next-Token Prediction is All You Need[10] Chameleon: Mixed-Modal Early-Fusion Foundation ModelsMultimodal Models — LLMs that can see and hear was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. getting-started, llm, ai, machine-learning, multimodal-ai Towards Data Science – MediumRead More

 Add to favorites
Add to favorites

0 Comments